Redis provides a neat command to iterate over all keys on a node. It’s the SCAN command that is used to scan over keys and to return a cursor to resume then the scanning from the cursor position. Complexity comes in when using Redis Cluster. In the previous scenario, all keys are located on one Redis node. With Redis Cluster keys are spread over some nodes.
When iterating over elements in a Set (SSCAN), a Sorted Set (ZSCAN) or a Hash (HSCAN) it basically does not matter whether using Redis Standalone or Redis Cluster because these commands take a key. The key resolves in Redis Cluster to a particular slot and you’re able to iterate over the elements. This is possible because the whole associated data structure is fully stored on the Redis Cluster node (or nodes when using slaves).
The SCAN command does not take a key but a key pattern. Changes to a key immediately result in a different hash slot. That’s the reason why you have to scan over the whole cluster, except for one case, when using keys prefixed with a hash tag.
When using hash tags you know the hash slot of the particular key and keys using this prefix:
{user1000}.myKey
{user1000}.myKey2
{user1000}.myKey3Redis Cluster uses user1000 to calculate the hash slot and stores all keys using this prefix in this slot.
But what about keys without a prefix? In this case, you need to scan over the whole cluster, or at least over all master nodes having slots assigned.
Most Redis Cluster clients provide two API. A Standalone API and a Cluster-specific API. The Cluster-specific API usually takes a command, inspects its key and routes the command to the appropriate node. Commands without a key are either rejected or executed on a default connection which usually defaults to the first node in the connection string/address.
You can still perform a cluster-wide SCAN but you need to create some functionality to make it work.
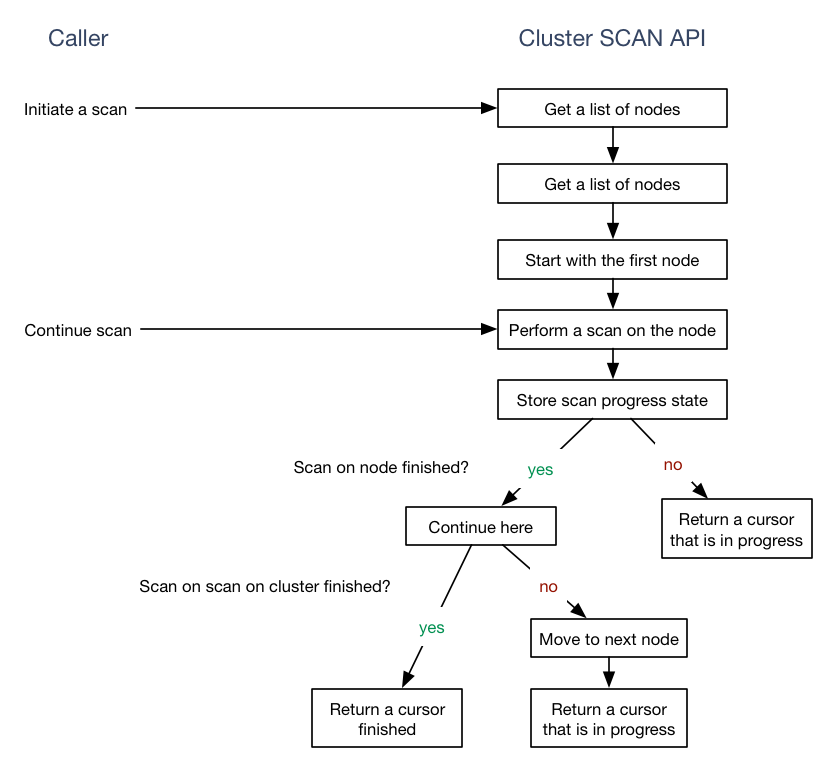
The idea is simple: Just perform a sequential scan over all nodes that could possibly serve the keys. To do so you need to:
- Retrieve a list of nodes that qualify for the scan (usually masters or slaves)
- Start on the first node
- Perform a
SCANon the node - Keep the scan state somewhere
- Return the result to the caller and indicate the scan is not over yet (except for 8.)
- Continue the
SCANon the node you left if the cursor was not finished and resume with 4. - If the
SCANwas finished on the particular node, continue theSCANon the next node and resume with 4. - If you have scanned over all nodes, then return a final signal so your caller knows the
SCANis finished
A good abstraction is to clone the SCAN API of your client. Usually, a client returns a Cursor or ScanCursor that carries the cursor value, the resulting elements and whether it is finished or not.
In programming languages supporting objects and subclasses, it’s a good idea to keep the state within the cursor. The cursor is an instance that is controlled by the caller. If the state were stored on the client itself, the state would have been to be managed with regard to timeout, disposal, ….
You don’t want to take this burden, you want to give this responsibility to the caller since the caller is the one who knows whether it continues the SCAN or not.
Note: A Hibernate Redis OGM PR (https://github.com/hibernate/hibernate-ogm/pull/629) carries an example implementation for a cluster-wide SCAN.
| Reference: | Iterate over all keys in a Redis Cluster from our JCG partner Mark Paluch at the paluch.biz blog. |
