I’ve been working at Chronopost, the French leader of express shipping, for most my carrier. In 2013, fed up with the inability of RDBMS to scale, I came up with a proposal of experimenting with C* in order to get a much faster, scalable, cheaper and more resilient data storage. The project has been very successful and now C* is at the center of our IT strategy. As we needed JDBC access to C* I’ve modified the legacy driver to make it C* 2.0+ compatible and use a round robin connection scheme with node discovery. Recently, I rewrote the JDBC driver almost entirely to wrap it around the Datastax java driver and get support for async queries, paging, UDTs, load balancing policies, etc.. I’ve been speaking lastly about Cassandra at Eu summit 2014, Big Data Paris 2015 and Devoxx France 2015.
Cassandra has a famous built in support for multi datacenter clusters, which does a lot to make this as transparent as operating on a single DC.
Usual reasons for going multi DC are :
- Disaster recovery / Adding resiliency
- Geographic colocation with clients to have low latencies
- Adding high latency datacenters for search or analytics
Whatever the motivation, you must forecast which multi DC pattern will be yours before building your apps or you might get into trouble, especially in case of failure.
Going multi DC the right way
Adding a new DC to an existing cluster is documented on the Datastax website, so just follow the recipe.
Still, before doing this you must understand how your apps/services will behave once the new DC is turned on.
Be aware that there is no bootstrap phase for the nodes in a new DC, which means they go live instantly with no data, and catch up later with the “nodetool rebuild” command.
Until the rebuild is finished (that can take a few hours based on your cluster load, the volume of data to stream and the fact that you’re using vnodes), the new DC will not be able to return the data that was inserted before it was turned on.
If your load balancing policy and consistency level allow having the new DC answer to queries on its own, you will end up with inconsistent query results : data could be incomplete, if not missing.
What you must do is either :
- use at least a QUORUM CL, if your replication factor doesn’t allow the new DC to reach it by itself
- or use the DCAwareRoundRobinPolicy + a LOCAL_* CL to segregate traffic to your historical DC
The Datastax drivers (across all supported languages) expose load balancing policies, which are used to select the coordinator nodes for your queries.
Among those, you’ll find the DCAwareRoundRobinPolicy, which is the only policy that allows to filter the coordinator nodes based on their datacenter.
Filtering the coordinator is only the first part in localizing your traffic since the consistency level will decide which nodes, across all DCs, will be involved in the query execution.
Local CLs (LOCAL_ONE, LOCAL_QUORUM, LOCAL_ALL, …) will only involve nodes that are located in the same DC as the coordinator, while non-local CLs (ONE, QUORUM, ALL, …) may involve nodes located in other DCs.
Are your DCs synchronous or asynchronous ?
Using a local CL means your datacenters are asynchronous : queries are completed even if a distant DC didn’t acknowledge it (yet). In this case, you are guaranteed that a row successfully inserted in a specific DC can be read from that same DC (given you’re using LOCAL_QUORUM reads/writes or a combination of LOCAL_ONE/LOCAL_ALL for read/writes).
Using a non local CL means your datacenters are synchronous : queries may involve all DCs and given you’re using QUORUM for reads/writes, all data inserted through any DC can be read instantly from any DC.
How to decide which pattern to use ?
Clusters with synchronous DCs have the following requirements :
- Low latencies between DCs
- At least 3 DCs in the cluster
- No analytical/search DC in the cluster
If your DCs communicate through high latency network links, it will have an impact on all queries and affect their latency. You might end up with poor performance in your application and occasional timeouts. An example here is the use of different AWS regions as different DCs, to serve european originating requests from a european datacenter.
Having at least 3 DCs is mandatory because in case you lose one DC, QUORUM can still be reached with the remaining ones. If you only have 2 DCs, losing one will prevent from reaching QUORUM and all queries will fail.
If you need to bring up a search cluster using SOLR (DSE), or an analytical one using Spark, their latencies under load will destroy your performance if they get involved in operational single partition queries. Accessing Cassandra through Spark usually implies reading all the SSTables for a given table, which leads to a lot of I/O and CPU load.
It is widely known in the community that this kind of load is incompatible with what Cassandra is primarily designed for : low latency queries.
That leaves us with the following list of characteristics for clusters with asynchronous DCs :
- High latencies between DCs
- exactly 2 DCs in the cluster
- At least 1 search/analytical DC in the cluster
How do I handle DC failure in both cases ?
Failover is pretty straightforward with synchronous DCs : you (mostly) have nothing to do. When using QUORUM, the loss of a DC leaves at least 2 DCs that can still achieve the CL.
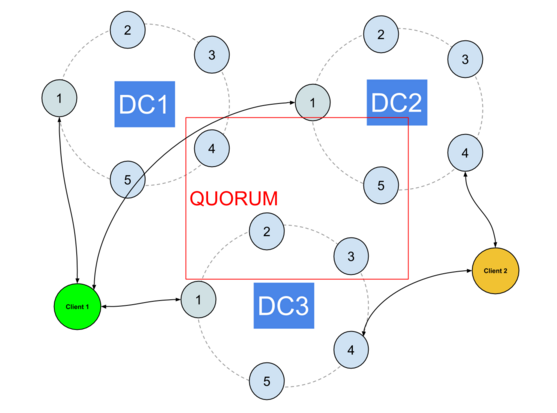
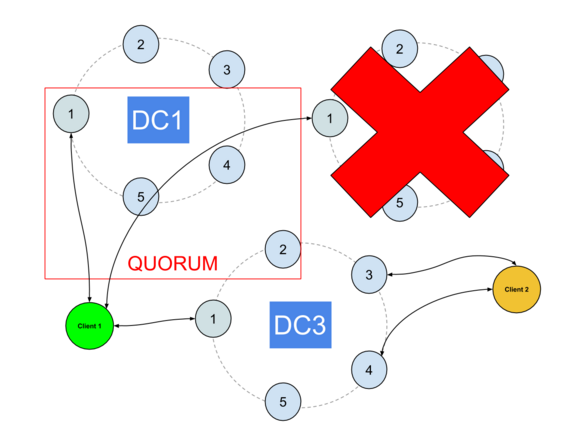
Things get a lot trickier with asynchrounous DCs.
The DCAwareRoundRobinPolicy, by default, prevents using other DCs nodes in case the local DC fails, and while this can be overriden by allowing some remote nodes to be used as coordinators, you might break consistency if you enforce this with local CLs.
For example, imagine your local DC gets turned off for maintenance during 6 hours. This is out of the defaults hint window which means a repair will be necessary when it comes back up . Until then, its data will be inconsistent with the other DCs.
If the driver allows switching to another DC, everything will work fine until the local DC comes back up and gets used as primary once again.
Failover methods with asynchronous DCs
I’ve selected 3 main methods to handle failover between DCs, all working on different layers of your infrastructure :
- at the request routing level
- at the application/service level
- at the driver level
Method 1
The most widely known way to handle failover between async DCs is also the one that requires the higher level of IT mastery. Services and app instances are colocated with Cassandra DCs and publish metrics on query failures. Those metrics are used to determine if the DC is still working properly and if the failure rate reaches a certain threshold, service requests are routed to another DC.
One prominent Cassandra user that implemented this technique is Netflix, with tools like Zuul to route traffic to microservices across AWS regions (it is a simplified view of how this works, the reality is a bit more complex).
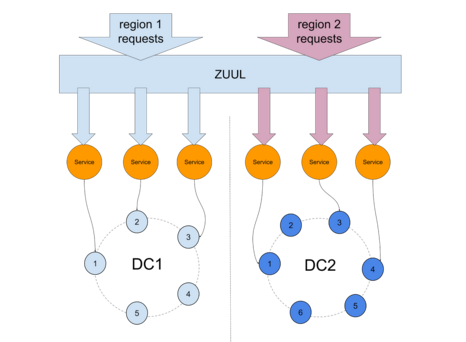
If the error rate reaches a defined threshold on DC1, region 1 requests get routed to region 2, as pictured in Netflix’s Flux :
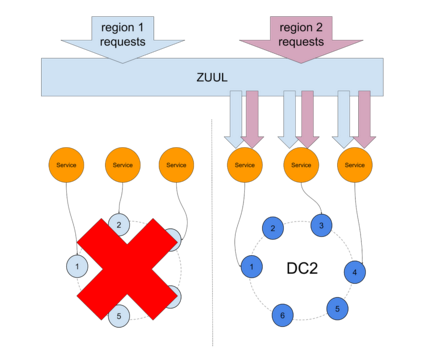
Among other things, this technique allowed Netflix to overcome the AWS reboot apocalypse without downtime.
Method 2
The second method is more DIY and supposes that you handle 2 separate Cassandra sessions in each app, and code the switch logic by yourself (beware of prepared statements, they need to be prepared again each time you switch sessions).
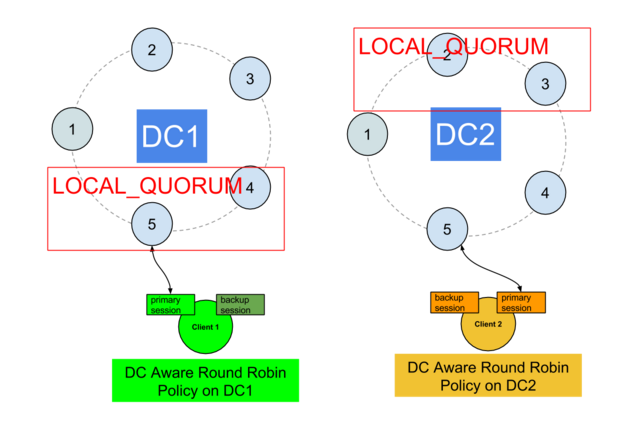
You must handle detecting the failure rate and switching to the secondary connection.
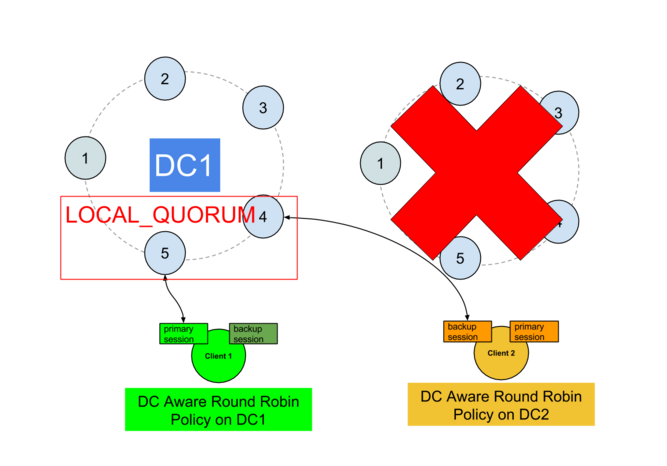
You must also prevent switching back instantly to the primary DC when it comes back up, since it may require a repair.
Method 3
The third method is to handle it at the driver level, through a custom load balancing policy.
The Datastax drivers facilitate creating your own load balancing policies by implementing the LoadBalancingPolicy interface.
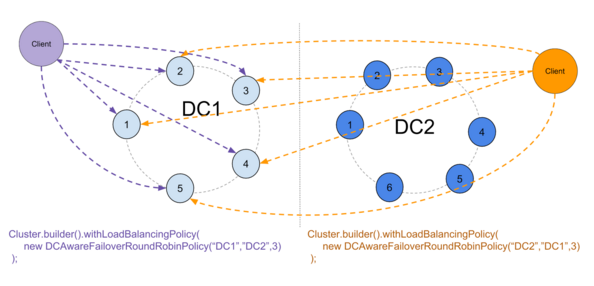
I’ve built such a policy on top of the existing DCAwareRoundRobinPolicy. It is currently best suited for small DCs (<10 nodes) but can work with bigger ones, and I named it DCAwareFailoverRoundRobinPolicy.
The source code is available on GitHub and the compiled package can be grabbed from Maven.
The policy takes 3 arguments : the primary DC, the backup DC and the number of nodes down that will trigger a switch.
It can also purely prevent switching back to the primary DC after a switch, or allow it if conditions are considered safe :
- The primary DC was down for less than the hint window
- Enough time has passed since the primary DC came back up to allow the hints to be processed
When everything is up, the policy works like the standard DCAwareRR policy :
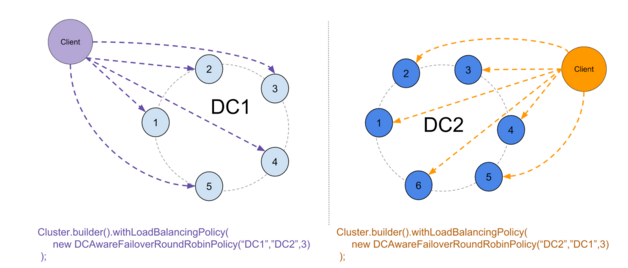
If we lose too many nodes in the primary DC, the policy will switch to the backup DC :
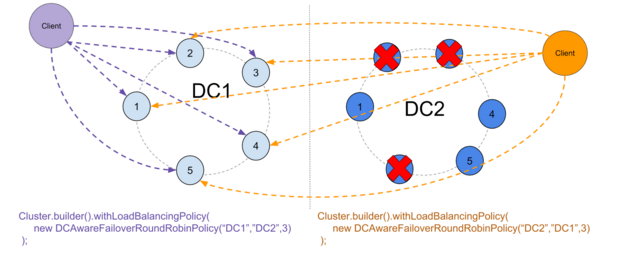
Switching back is prevented as a security against inconsistencies :
While in small DCs, with a replication factor of 3, you can reasonably expect that loosing 3 nodes will make you lose at least quorum for some token ranges, it is not the case with bigger DCs.
The upcoming version of the policy will not work on nodes down but on lost token ranges, so that the switch will only occur if you actually lost quorum on at least one token range (if your data is correctly distributed, you should always have data in most ranges).
Using racks instead of datacenters
If you want to have at least 3 operational synchrounous DCs and 1 or more search/analytical DCs, you may want to use racks instead of DCs.
Create 1 operational DC divided in racks, and 1 analytical DC, then use the standard DCAware policy to direct all traffic to the operational DC, with a local CL to avoid involving the analytical DC in low latency requests.
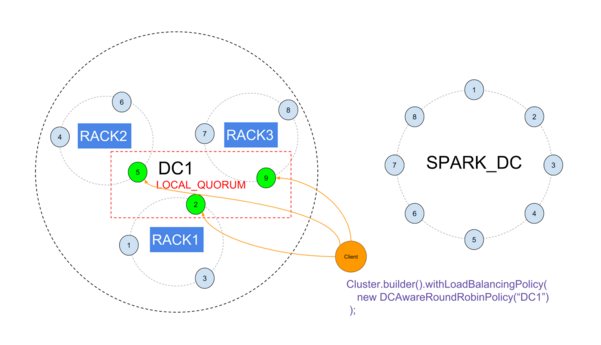
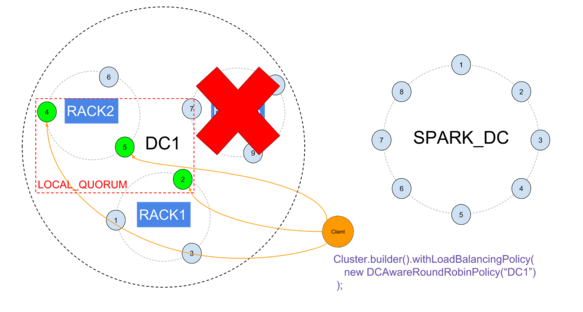
Losing one rack won’t affect LOCAL_QUORUM :
Conclusion
Cassandra offers great features for multi DC support, but keep in mind that while giving more flexibility in the design of your clusters, it adds complexity to failover procedures : you’ll go from simply choosing the right CL in single DC clusters (hint : use QUORUM), to having to track metrics at the app level and route traffic appropriately.
Identify the pattern of your multi DC cluster, and choose the failover method that will most easily be implemented in your apps. Also, check that your apps are all “multi DC ready”, and understand what will happen when the new DC comes up to avoid inconsistencies during the rebuild phase.
| Reference: | Going multi DC with Cassandra : what is the pattern of your cluster ? from our JCG partner Alexander Dejanovski at the Planet Cassandra blog. |
