Using MapR, Mesos, Marathon, Docker, and Apache Spark to Deploy and Run Your First Jobs and Containers
This blog post describes steps for deploying Mesos, Marathon, Docker, and Spark on a MapR cluster, and running various jobs as well as Docker containers using this deployment.
Here are the components that we’re going to use:
- Mesos: an open-source cluster manager.
- Marathon: a cluster-wide init and control system.
- Spark: an open source cluster computing framework.
- Docker: automates the deployment of applications inside software containers.
- MapR Converged Data Platform: integrates Hadoop and Spark with real-time database capabilities, global event streaming, and scalable enterprise storage to power a new generation of big data applications.
Assumptions
This tutorial assumes you already have a MapR 5.1.0 cluster up and running. For testing purposes, it can be installed on a single node environment. In this example, however, we will deploy Mesos on a 3-node MapR cluster, e.g.:
- Mesos Master: MAPRNODE01
- Mesos Slave: MAPRNODE02, MAPRNODE03
Let’s get started!
Prerequisites
# Make sure Java 8 is installed on all the nodes in the cluster java -version # If Java 8 is not yet installed, install it and validate yum install -y java-1.8.0-openjdk java -version # Set JAVA_HOME to Java 8 on all the nodes echo $JAVA_HOME # If JAVA_HOME isn't pointing towards Java 8, fix it and test again # Please make sure that: /usr/lib/jvm/java-1.8.0-* is matching your java 8 version vi /etc/profile export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.65-2.b17.el7_1.x86_64/jre # Load and validate the newly set JAVA_HOME source /etc/profile echo $JAVA_HOME
Now you’re all set with the correct Java version. Let’s go ahead and install the Mesos repository so that we can retrieve the binaries from it.
Install Mesos repository
Please make sure you install the correct Mesos repository matching your CentOS version.
# Validate your CentOS version cat /etc/centos-release # for CentOS 6.x rpm -Uvh http://repos.mesosphere.com/el/6/noarch/RPMS/mesosphere-el-repo-6-2.noarch.rpm # for CentOS 7.x rpm -Uvh http://repos.mesosphere.com/el/7/noarch/RPMS/mesosphere-el-repo-7-1.noarch.rpm
Now that we have the Mesos repositories installed, it is time to start installing Mesos and Marathon.
Install Mesos and Marathon
# On the node(s) that will be running the Mesos Master (e.g., MAPRNODE01): yum install mapr-mesos-master mapr-mesos-marathon # On the nodes that will be running the Mesos Slave (e.g., MAPRNODE02, MAPRNODE03): yum install mapr-mesos-slave # Run on all nodes to make the MapR cluster is aware of the new services /opt/mapr/server/configure.sh -R # Validate the Mesos Web UI to see the master and slave http://MAPRNODE01:5050
Launch a Mesos job from the shell
# Launch a simple Mesos job from the terminal by executing: MASTER=$(mesos-resolve `cat /etc/mesos/zk`) mesos-execute --master=$MASTER --name="cluster-test" --command="sleep 5"
Besides the console output, which will show a task being created and changing status to TASK_RUNNING and then TASK_FINISHED, you should also see a newly terminated framework on the frameworks page of the Mesos console UI: http://MAPRNODE01:5050
Launch a Mesos job using Marathon
Open Marathon by pointing your browser to http://MAPRNODE01:8080 and click on “Create Application”
# Create a simple app to echo out 'hello' to a file. ID: cluster-marathon-test CPU's: 0.1 Memory: 32 Disk space: 0 Instances: 1 Command: echo "hello" >> /tmp/output.txt # Click "Create Application"
Check the Marathon console (http://localhost:8080) to see the job being deployed and started:

Also:
# Check the job output to see "hello" being written constantly tail -f /tmp/output.txt
Check the Active task in Mesos by pointing your browser to http://localhost:5050

Finally, destroy the application by opening Marathon console (http://MAPRNODE01:8080), click on the ‘cluster-marathon-test’ application and select ‘destroy’ from the config drop-down:
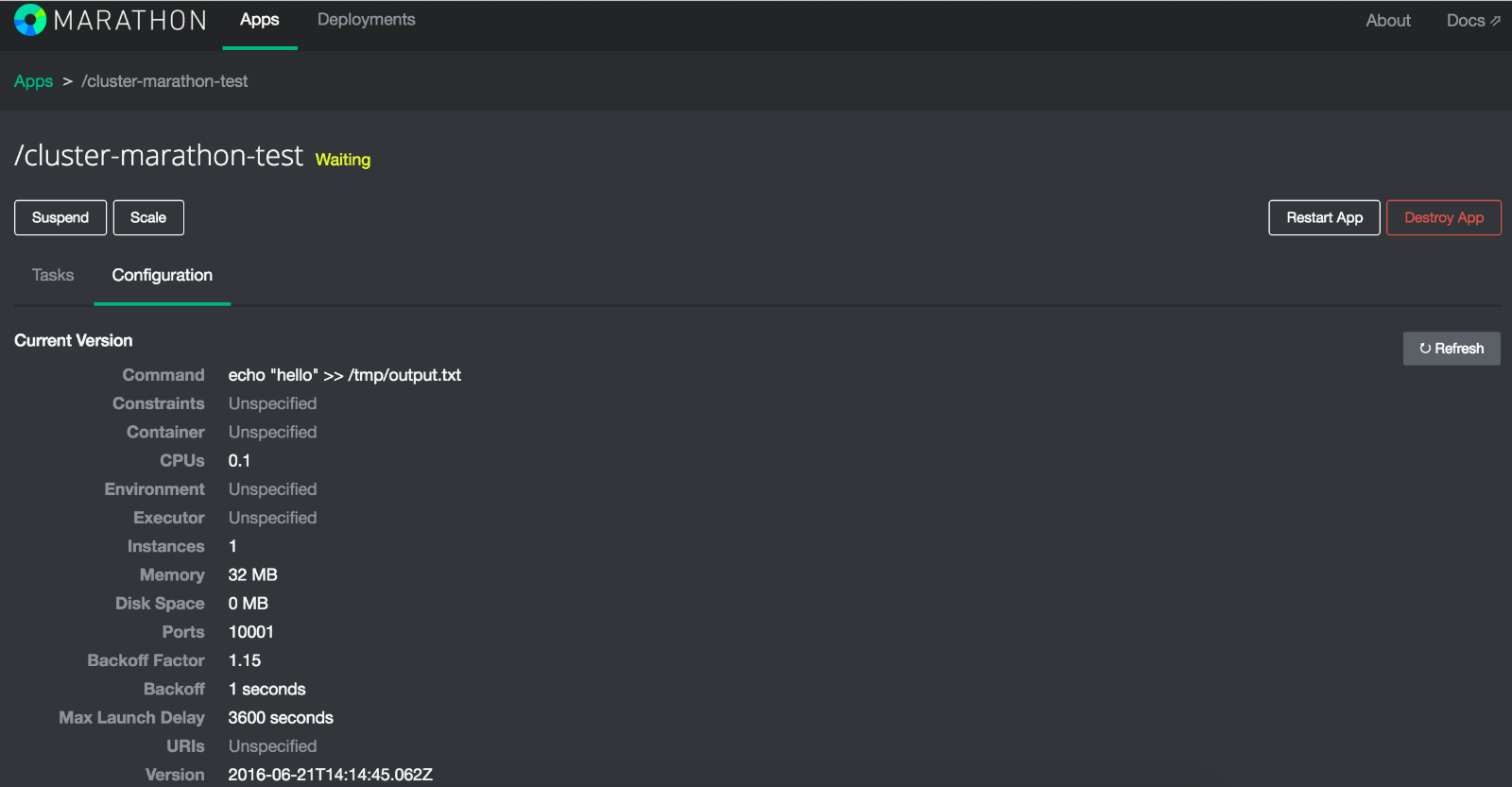
Launch Docker containers on Mesos
Now that we have Mesos running, it is easy to run Docker containers at scale. Simply install Docker on all nodes running Mesos Slave, and start launching those containers:
Install docker on all Mesos Slave nodes
# Download and install Docker on all Mesos Slave nodes curl -fsSL https://get.docker.com/ | sh # Start Docker service docker start chkconfig docker on # Configure Mesos Slaves to allow docker containers # On all mesos slaves, execute: echo 'docker,mesos' > /etc/mesos-slave/containerizers echo '5mins' > /etc/mesos-slave/executor_registration_timeout # Restart the mesos-slave service on all nodes using the MapR MCS
Now that we have Docker installed, we will be using Marathon to launch a simple Docker container being the Httpd web server container for this example.
# Create a JSON file with the Docker image details to be launched on Mesos using Marathon
vi /tmp/docker.json
# Add the following to the json file:
{
"id": "httpd",
"cpus": 0.2,
"mem": 32,
"disk": 0,
"instances": 1,
"constraints": [
[
"hostname",
"UNIQUE",
""
]
],
"container": {
"type": "DOCKER",
"docker": {
"image": "httpd",
"network": "BRIDGE",
"portMappings": [
{
"containerPort": 80,
"protocol": "tcp",
"name": "http"
}
]
}
}
}
# Submit the docker container using the created docker.json file to Marathon from the terminal
curl -X POST -H "Content-Type: application/json" http://MAPRNODE01:8080/v2/apps -d@/tmp/docker.jsonPoint your browser to open Marathon (http://localhost:8080) and locate the httpd Docker container:
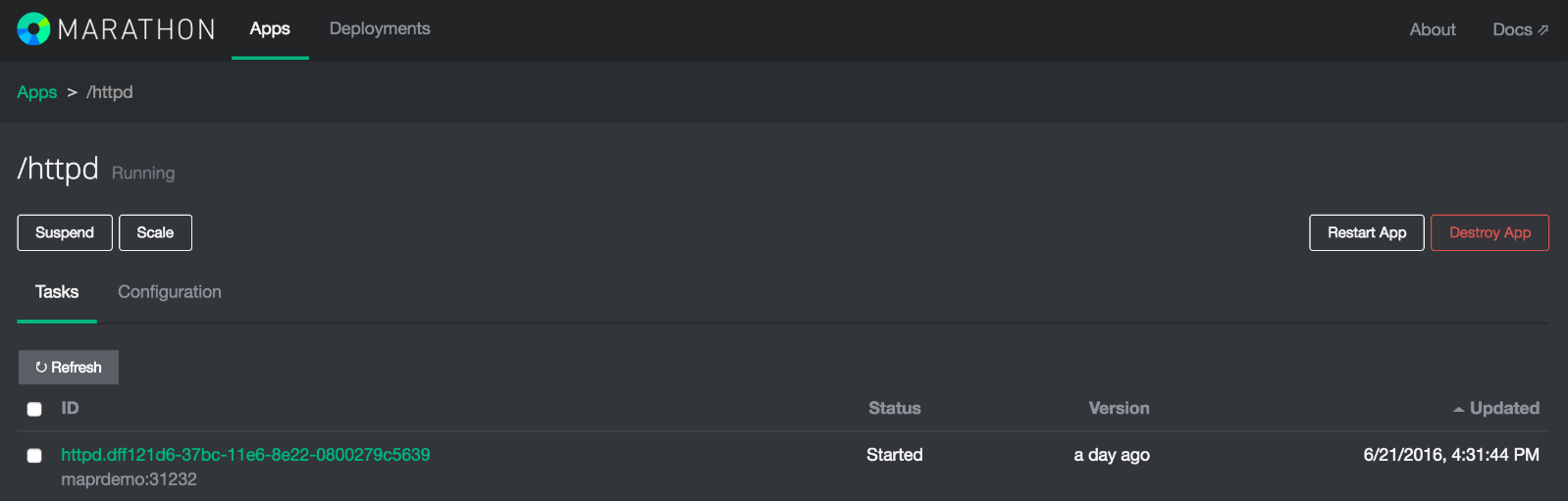
Underneath the ID field, Marathon will expose a hyperlink to the Docker container (please note that the port will be different as this will be dynamically generated). Click on it and you will connect to the httpd container:
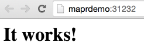
You’ve now successfully launched a Docker container on Mesos using Marathon. You can use the same approach to launch any kind of Docker container on the Mesos infrastructure. In addition, you can use the unique NFS capabilities of MapR to connect the Docker container to any data on the MapR Converged Data Platform, without needing to worry about which physical node the Docker container will be launched in. In addition, if you want to connect your Docker containers securely to MapR-FS, it is highly recommended to use the MapR POSIX Client. My community post below describes how to achieve this:
With the ability to launch Docker containers on our Mesos cluster, lets move on and launch Spark Jobs on the same infrastructure.
Install and launch Spark jobs on Mesos
# Install Spark on the MapR node (or nodes) from which you want to submit jobs yum install -y mapr-spark-1.6.1* # Create the Spark Historyserver folder on the cluster hadoop fs -mkdir /apps/spark hadoop fs -chmod 777 /apps/spark # Tell the cluster that new packages have been installed /opt/mapr/server/configure.sh -R # Download Spark 1.6.1 - Pre-built for Hadoop 2.6 wget http://d3kbcqa49mib13.cloudfront.net/spark-1.6.1-bin-hadoop2.6.tgz # Deploy Spark 1.6.1 on the MapR File System so Mesos can reach it from every MapR node hadoop fs -put spark-1.6.1-bin-hadoop2.6.tgz / # Set Spark to use Mesos as the execution framework vi /opt/mapr/spark/spark-1.6.1/conf/spark-env.sh # Set the following parameters, and make sure the libmesos version matches your installed version of Mesos export MESOS_NATIVE_JAVA_LIBRARY=/usr/local/lib/libmesos-0.28.2.so export SPARK_EXECUTOR_URI=hdfs:///spark-1.6.1-bin-hadoop2.6.tgz
Launch a simple spark-shell command to test Spark on Mesos:
# Launch the Spark shell job using Mesos as the execution framework /opt/mapr/spark/spark-1.6.1/bin/spark-shell --master mesos://zk://MAPRNODE01:5181/mesos # You should now see the Spark shell as an active framework in the Mesos UI # Execute a simple Spark job using Mesos as the execution framework val data = 1 to 100 sc.parallelize(data).sum()
Submit a Spark job to Mesos using spark-submit:
# Run a Spark Submit example to test Spark on Mesos and MapR /opt/mapr/spark/spark-1.6.1/bin/spark-submit \ --name SparkPiTestApp \ --master mesos://MAPRNODE01:5050 \ --driver-memory 1G \ --executor-memory 2G \ --total-executor-cores 4 \ --class org.apache.spark.examples.SparkPi \ /opt/mapr/spark/spark-1.6.1/lib/spark-examples-1.6.1-mapr-1605-hadoop2.7.0-mapr-1602.jar 10
Troubleshooting
Troubleshooting the various components like Mesos, Marathon, Spark, and Docker to find potential issues can be a bit challenging, given the amount of components involved. Here are five troubleshooting tips:
# 1. Marathon port number 8080 This port number might conflict with the Spark Master as this runs on the same port. # 2. Log information The Mesos Master and Slave nodes write their log information into on the respective nodes: /var/log/mesos/ # 3. Marathon as well as some generic Mesos Master and Slave logging ends up in /var/log/messages tail -f /var/log/messages # 4. Enable extra console logging by executing the following export prior to running spark-submit on Mesos export GLOG_v=1 # 5. Failed to recover the log: IO error This error message may occur if you previously ran Mesos as the root user and are now trying to run it as non-root users (for example, the mapr user). # Full error message in /var/log/messages: # Failed to recover the log: IO error /var/lib/mesos/replicated_log/LOCK: Permission denied chown -R mapr:mapr /var/lib/mesos/replicated_log/
Conclusion
In this blog post, you’ve learned how to deploy Mesos, Marathon, Docker, and Spark on top of the MapR Converged Data Platform. You’ve also submitted various jobs using the shell, and launched Spark jobs as well as Docker containers.
If you want to securely connect Docker containers to the MapR Converged Data Platform, please read my community post here:
If you have any feedback or questions, please post them in the comments section below.
| Reference: | Using MapR, Mesos, Marathon, Docker, and Apache Spark to Deploy and Run Your First Jobs and Containers from our JCG partner Martijn Kieboom at the Mapr blog. |

