At Strata+Hadoop World in London, MapR Director of Enterprise Strategy & Architecture Jim Scott talked about Real-time Hadoop: The Ideal Messaging System. You can watch his presentation here or read the post below to learn more:
Within this post you will see mention of message-driven architectures. This is in short a subset of a service oriented architecture (SOA). This has been around for many years and is a very popular model. What you will find going through this post is that the foundational message-driven architecture is more competitive to the concepts of the enterprise service bus (ESB). The ESB was very heavy and rigid whereas a general SOA implementations to not require an ESB.
What are we talking about when we start getting into Real-time Hadoop? Well, life’s a batch, or at least that’s how you might hear people talk about everything around big data. At the end of the day, life isn’t done in a batch. Life is about streaming events that are constantly occurring, and having to deal with it one thing at a time.
We’ve got to be able to move forward, move on, and handle things coming through as they happen. Everybody has been really comfortable with batch for a long time. As people get more comfortable with these technologies, they start realizing that they can do more and more. It’s not really much of a surprise that streaming technologies are as big as they are at this point. Being able to move from batch to real time is not terribly complicated, depending on your use case.
Real-time or near-time
Some of the goals that I’ve set forth are real time or near real time. To clarify, it’s important to understand the general semantics that we’re really dealing with, because real time doesn’t always just deal with an event that physically occurred just now. It could be “I’m ready to do processing on my data, and I need it to happen now.” The event may have happened two days ago, but now you’re ready to perform your real-time processing. Whatever service levels you set up, that’s what you’re trying to work with.
Micro-services
When we start looking at things like micro-services, it’s a natural tendency to think of well, how do micro-services tie together with streaming? It’s a natural design pattern if you want to scale an application, how do you decouple applications from the communications? Micro-services are really the new model that people are looking at to say, look, I’m going to break it up into smaller pieces, which gives an ability to deploy software in simpler, smaller chunks. But in order to do that, and in order to scale those services, you have to decouple the communication.
Advantages of Message Based Real-time Enablement
Less moving parts. What are some of the advantages of messaging and real-time enablement? We have less moving parts. When you start thinking about all of the technologies that go into inter-process communication, being able to scale systems, having your persistence stores, when you start decoupling these with the messaging platform, it actually simplifies your architecture, in most cases. Message-driven Architectures and Service Oriented Architectures are not brand new. They have been around for a long time and will continue to flourish.
Better resource utilization. When we start looking at resource utilization, there’s a big benefit here, and as we look across different environments, we have the ability to create new types of isolation models. When you run code in your development environment, does your development environment ever look the same shape as your production environment? Likely not. If you have two servers in dev and two servers in production, great. That’s not most use cases. I used to work in ad tech, where I built a platform handling 60 billion transactions a day, and we had 10 servers in dev, and we had 600 in production.
Common deployment model. Being able to figure out how to take your production environment and test with real live data is a problem that a lot of people struggle with. When you decouple your messaging platform from your components, you have the ability to absorb all that information coming from production environments for development and test purposes.
Improved integration testing. When you get to things like integration testing, you simplify it, and it’s a huge deal. A lot of people would pay a lot of money to have this ability in their current environments. The problem is, most of those environments were not built to support such capabilities. Doing full database copies from your production environment into a development environment is not usually cost effective, or timely enough to be impactful.
Shared file system. Having a shared file system for your state of your applications is a really big deal. Messaging plays one part in real time, but being able to have stateful services that, in the micro-service world, you want to be able to tear down or throw away is a good thing.
How to Couple Services and Break Micro-Ness
A micro-service is loosely coupled with bounded context. Let’s take a look at the concepts of micro-services:
Having a shared schema and a shared database that shares a schema. Now, what’s the greatest single thing about a shared database? It’s when you have to go sit in a meeting to talk about how you evolve your schema, and you come to an agreement within five minutes of the beginning of the meeting, because that doesn’t happen. That’s not realistic, that’s not life. Typically, when you’re going through these shared schemas, it takes hours of time and you can’t come to agreement, it’s a pain.
Ad hoc communication between services. When we get rid of the ad-hoc communication between the services, we fully decouple that, and suddenly we now have a way to handle scaling and not worry about breaking that “micro-ness.”
Brittle protocols. Having protocols that cannot evolve is really bad. Think of java serialization as a bad protocol, if you were trying to use that between services. Corba is another example of a brittle protocol. If you have a restful service that interchanges data in JSON format, that’s a pretty nice simple protocol that can evolve.
Poor protocol versioning. Then being able to version your protocol is a pretty important thing. Being able to identify what it is in time, as you’re using it, and not having to question what the format or expectation is.
Don’t do these things!
How to Decouple Services
Use self-describing data. Self-describing data is a big deal. I mentioned JSON. Avro is pretty good. Binary JSON is also nice. When we think about migrating over time, you want to add fields. You don’t want to go changing data types. I’ve known people who have taken JSON, and they’ve swapped out a string field for an array. Why would you go and do that? You don’t want to be that guy.
Private databases. Now, private databases are actually a good thing, when it comes down to it. We could both be using the same schema today, but if I put it in my own database, and you need to evolve yours tomorrow, and they diverge, who cares? My use case is my use case: I have my database, and you don’t need to get into it.
Use shared storage where necessary due to scale. When we start going through all of these protocols, and we start looking at things like shared storage, we’ve got to be cognitive of being able to get the data stored someplace, where you don’t have to worry about something like a container blowing up and never being able to get the data back out.
Decoupled Architecture
Ideally, in something like a decoupled architecture, you’d have a diagram like this. This is a pretty accurate type of representation for how people end up building systems with decoupled architectures.
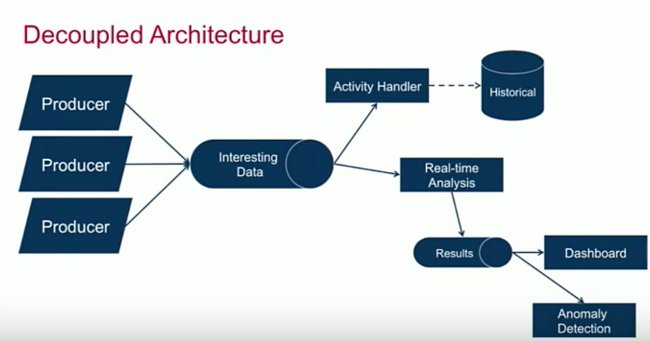
At the top, you can build a process to take all the activity and perhaps store it in your historical archive. At the bottom, you end up creating some type of results, and maybe build dashboards on top of it. You have the ability to be able to plug these things in, and as you’re scaling out your environment, you don’t have to worry about bottlenecking your system. You don’t have to worry about running out of resource capacity on either side of the messaging platform.
Message queues are classic answers. Traditional message queues are kind of inherently flawed, when it comes to being able to handle the scale that we want. When you look at acknowledgements, we look at this really heavy transactional nature that comes along with traditional message queues.
Key feature/flaw is out-of-order acknowledgement. Having out of order acknowledgement is something that can happen. Traditionally, these days, not really something people want to have to think about, but everybody wants to think about making sure they don’t lose messages.
You pay a huge performance hit for persistence. Not losing messages means you need persistence. Needing persistence in a traditional message queue means you need to have that heavy overhead of those transactions.
Mechanisms for Decoupling
Kafka-esque logs. Persistence is the key feature, and so when we look at the Kafka-esque style model, we get this ability to effectively have a continuous IO stream in a sweeping motion, and able to pick everything up. It increases your throughput, you get the persistence that you want, and being able to have out of order acknowledgement, you can’t really do that, because you pick up everything from start to finish. We get the performance, the scalability is there, and we can actually deliver upon having a real message-driven service oriented architecture with a platform like Kafka.
Fraud Detection
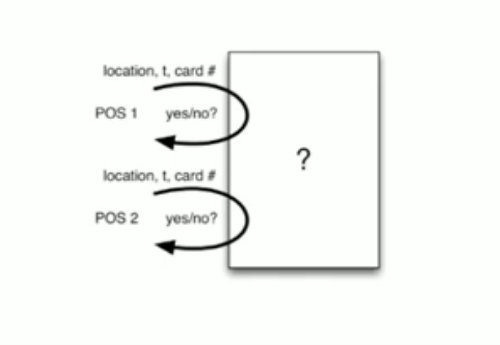
Given a topic like credit card velocity, if a credit card transaction happens here, and then a credit card transaction 3 seconds later happens in Stockholm, and 5 seconds later happens in New York, we can be pretty sure there’s fraudulent activity going on. Unless they happen to only be internet vendors. Maybe then, but still, 3 transactions in 5 seconds, that’s really tight. The card literally cannot go between those locations fast enough to make those transactions happen, so it’s a way for us to identify card fraud.
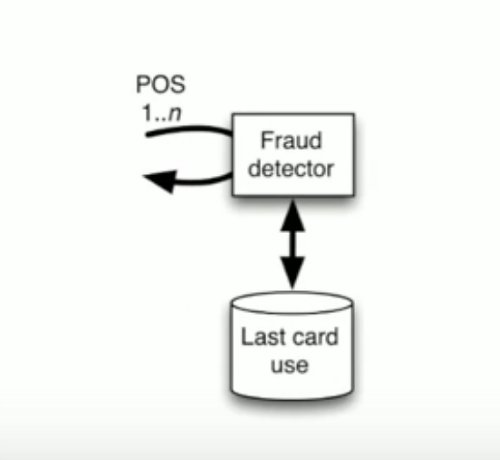
In a traditional solution, we’d see something like this event coming in. The fraud detector would do some work, and it would spit out its last card use into a database. In this model, we don’t really have a great scaling model. What would end up happening here, is if we want to scale that fraud detector, we may want to version it, maybe we want to have different types of fraud detection, we would then use this shared database. Having a shared database in this model is brittle. It’s going to potentially cause the system to fall.
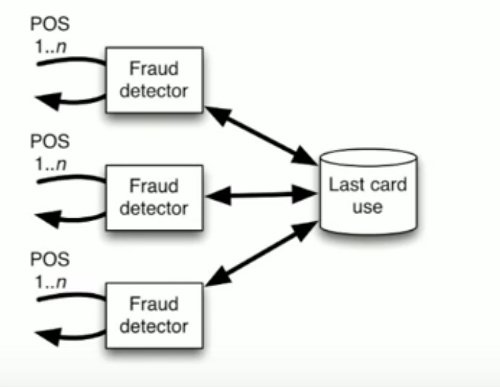
Why is it breaking here? Well, number one, it could go this way because you’re sitting stuck in meetings trying to evolve the schema, and you can’t agree on it, because you need to put a new fraud detector in place, and it’s going to break everything else. Or, it’s going to just fall over because it can’t handle the volume, because you may have hundreds of millions of transactions per day, running through each of these fraud detectors, and every one of them needs to work, and they all need to work with that shared database.
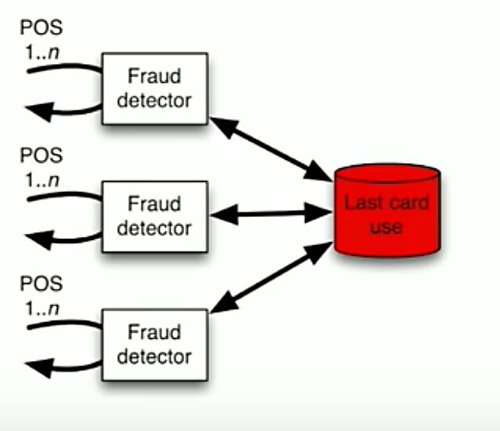
My experience with relational databases in these models, they’re not necessarily built to scale, or they weren’t prepared to scale, so putting these services out and scaling them, was probably not something someone thought about. I’m not saying relational databases don’t scale, but it probably wasn’t thought about for this.
How to Get Service Isolation
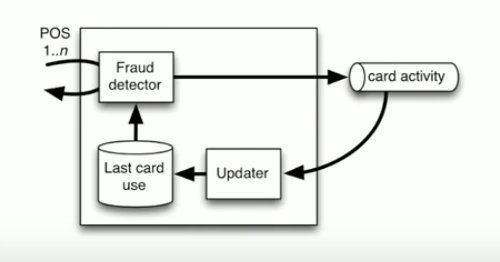
If we want to get service isolation, a great way to do that is to break out that information into a messaging platform. If we send those messages through the messaging platform, we can now have an updater come through and update that private database.
New Uses of Data
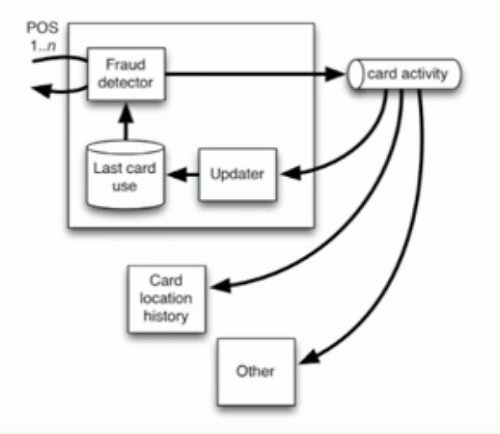
Now, the fraud detector has its own private database, the updates come through, and as we decide to scale, we can have these new use cases come on, and they can all listen to card activity. Now the database has been separated out, and when we go forward we can scale this anyway we want to, and none of them share a database.
Scaling Through Isolation
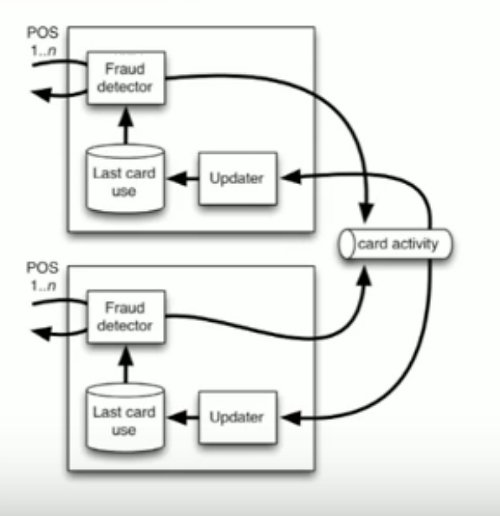
A shared database doesn’t mean I have to have a dedicated server somewhere. Whatever your model is, you can use that. It could be a NoSQL database, it could be flat files, who knows? Whatever your database is, that’s cool, fine by me. I’m not trying to tell you which it should be, but in this case, if this database ends up growing to 10 gigs of data over the life of detecting all of these credit card transaction fraud histories, who cares? You can’t even go out and buy a 10 gigabyte disk anymore. Just about the smallest disk you can get your hands on is around 600 gigs.
Lessons
Some of the things to consider here is that when we move to this isolation model it’s really truly what we’re looking for. You get the autonomy to build, deploy, and scale these services out as the business needs are defined. You’re not stuck in a corner waiting and hoping that you don’t have use cases that conflict with one another on top of your shared database or on top of your shared storage. The communication becomes easier. You can propagate these events, and you don’t have to worry about the table updates.
Can We Get “Extreme?”
If we want to evolve in this model, one of the things that I like to talk about is, can we get to the extremes? When I’m talking about extreme, I’m typically talking about a trillion plus events per day. Let’s evaluate some of the other requirements I have. I want to be able to effectively support millions of producers, and billions of events per second. Logistically speaking, I may have multiple consumers for every single message. That’s where you really start seeing that being able to handle that many events per day really scales out quickly, because as soon as you start adding every other consumer in the pipeline, you now are radically increasing how many total events you’re pushing through your pipeline.
I like to make sure that when I’m talking about extremes, I’m talking about multiple data centers, because multiple data centers is about the best way you can go to implement a disaster recovery copy. I would personally opt for not having it be a “DR” copy, and actually making it a fully live-functioning copy, so that if I ever have to failover, I don’t have to worry about having my data working somewhere else.
Let’s try and put this in perspective. What does reality look like? I’ve pulled out what I consider to be a pretty reasonable set of numbers here:
Monitoring and Application logs
- 100 metrics per server
- 60 samples per minute
- 50 metrics per request
- 1,000 log entries per request
- 1 million requests per day
2 billion events per day – for one small use case
When you add it up, this is about 2 billion events per day. That’s pretty substantial. Is it a trillion events per day? No, but as you start looking at a micro-service model, you start looking at more and more decoupled communication, which fans out very quickly. If you say, I’ve got a service to handle X, and I do resource management, and I now need to add 10 more of these, you now just went 10X on any metrics getting produced. It scales very quickly.
Considering a Messaging Platform
50-100k messages per second used to be good. Six years ago, we were happy when I used to work on cellular probe data coming in from phones, and we were handling those probe points and matching them to the map geographically, putting them where they’re supposed to be. We were really happy when we got 50,000 to 100,000 messages per second.
To build a proper message-driven, service oriented architecture, you can’t really scale effectively with low numbers like that, because the more your fan-out is, the more you’re going to have to add to your messaging platform to be able to handle the scale. If you’re putting all the cost back into the scaling of your messaging platform, you have to ask the question if you’re putting the money in the right place.
Kafka model is BLAZING fast. Now, when I say the Kafka model, there are a couple products in the space, but specifically with MapR Streams we’ve benchmarked it:
- Kafka 0.9 API with message sizes at 200 bytes
- MapR Streams on a 5 node cluster sustained 18 million events/sec
- Throughput of 3.5GB/s and over 1.5 trillion events/day
Which Products Are We Discussing?
Specifically, the products that fall into this category–and there are no other products I am personally aware of that can do this other than–MapR Streams and Apache Kafka. Fundamentally, the difference here is that they both support that same API, MapR Streams is an implementation of the API on top of MapR. It’s not the same implementation. It follows the model, but it’s a different implementation, so the API is there. It’s effectively a zero administration messaging model.
How We Do This with MapR
MapR Streams is a C++ reimplementation of the Kafka API
- Advantages in predictability, performance, scale
- Common security and permissions with entire MapR Converged Data Platform
Semantic extensions
- A cluster contains volumes, files, tables, and now streams
- Streams contain topics
- Stream are accessed by path name
Core MapR Capabilities Preserved
- Consistent snapshots, mirrors, multi-master replication
The fundamentals for how MapR Streams works is the same, but because we have the underlying platform, we wrote our own. The model is there, and it delivers all of these capabilities, like being able to mirror your data from data center A to B. It’s literally click, send a copy over to here. Schedule it, every hour do a mirror, and it’s just the bytes that have changed. It’s not full file copies. If you have a 10 gigabyte file, and you change a byte in HDFS, you have to recopy the entire 10 gigabytes. In MapR, that one byte change is going to yield an 8k transfer, because 8k is the smallest block size that we move. That’s a pretty good comparison. Do I move 8k, or do I move 10 gigabytes? I like that. Being able to do snapshots works on the file system, it works on the tables, and it works on the streams, so you can get a consistent point in time view of all that at the same time.
And More…
Streams are implemented in terms of B-tress as well
- Topics and consumer offsets are kept in stream, not ZooKeeper
- Similar splitting technology as MapR-DB tables
- Consistent permissions, security, data replication
It’s all implemented under the covers in B-trees. All the data is sorted and organized with B-trees. We don’t have the ZooKeeper bottleneck that you might see in Kafka. We’ve taken the effort out of administering MapR Streams. We’ve taken it out of MapR-DB, as well. The benefits are, you’re going to get everything you want to make your life easier. The features and functionality are there, and you don’t have to worry about how to move things back and forth anymore.
The Importance of Common APIs
Commonality and interoperability are critical
- Compare Hadoop ecosystem and the NoSQL world
Table Stakes
- Persistence
- Performance
- Polymorphism
Major trend so far is to adopt Kafka API
- 0.9 API and beyond remove major abstraction leaks
- Kafka API supported by all major Hadoop vendors
The common APIs are very important. When you start decoupling things, you want to make sure that you can talk. It’s the same thing with the brittleness for micro-services. You don’t want to have a protocol that’s easy to break. You don’t want to have a protocol that you can’t version appropriately.
The lessons here are:
- APIs matter more than implementations.
- There is plenty of room to innovate ahead of the community. The community is about evolution. It’s slowly creating new and adding on more functionality. Being able to take those APIs and go re-implement them in a different way is what causes revolution. It’s being able to make your life easier. It’s not about little incremental changes, it’s about sweeping changes that say, “I’m going to re-do it. I’m going to make it so your program still works, and I’m going to make your life easier.”
- POSIX, HDFS, HBase all define useful APIs. When you look at POSIX, NFS, HDFS, and HBase, you see all these APIs. They’re pretty widely accepted APIs, even with HBase as an example. Even Google took the HBase API and started supporting it on Google Bigtable.
- Kafka 0.9+ does the same.
What Have We Learned?
Need persistence and performance
- Possibly for years and to hundreds of millions t/s
Must have convergence
- Need files, tables AND streams
- Need volumes, snapshots, mirrors, and permissions
Must have platform security
- Cannot depend on perimeter
- Must follow business structure
When we’re looking at all of this data, we need to have all of the scale-out that we require, a decoupled message-driven, service oriented architecture, and a messaging platform that can actually scale to the volumes that we need. In the message queues of yesteryear, you would have to worry about that. That would be a serious concern. That did not scale out the same way.
Being able to scale out in a global capacity is a really big deal. I highly recommend message-driven, service oriented architecture as part of your future, if you have not already implemented this. The technologies sitting here are fantastic and not terribly difficult to use, and they’re fast.
I encourage you to create producers and consumers that support the Kafka API. It’s the same thing I was saying when I was one of the first people back in 2009 using HBase. I thought the HBase API was great. Suddenly, others started adopting it slowly over the following few years. Having these APIs accepted and building against them is pretty nice. It gives you the ability to pick up and move between the products.
| Reference: | Real-time Message-driven Service Oriented Architecture: Bringing the Boom! from our JCG partner Jim Scott at the Mapr blog. |
