What are some of the biggest problems with the current state of Java monitoring?
Errors in production are much like drunk texting. You only realize something went wrong after it had already happened. Texting logs are usually more amusing than application error logs, but… both can be equally hard to fix.
In this post we’ll go through a 12 step monitoring flaws rehab program. A thought experiment backed by the experience of Takipi’s users with some of the most common problems that you’re likely to encounter – And what you can do about them.
Let’s roll.
Step #1: Admitting that we have a problem
In fact, it’s only one problem on a higher level, application reliability. To be able to quickly know when there’s something wrong with the application, and having quick access to all the information you need in order to fix it.
When we take a step closer, the reliability problem is made up of many other symptoms with the current state of monitoring and logging. These are thorny issues that most people try to bury or avoid altogether. But in this post, we’re putting them in the spotlight.
Bottom line: Troubleshooting and handling new errors that show up in production is unavoidable.
Step #2: Shutting down monitoring information overload
A good practice is to collect everything you can about your application, but that’s only useful when the metrics are meaningful. Inconsistent logging and metrics telemetry generate more noise when their actionability is just an afterthought. Even if they result in beautiful dashboards.
A big part of this is misusing exceptions and logged errors as part of the application’s control flow, clogging up logs with the paradox of “normal” exceptions. You can read more about this in the recent eBook we released right here.
As the cost for monitoring and data retention goes lower, the problem shifts to collecting actionable data and making sense of it.
Bottom line: Even though it’s gradually getting easier to log and report on everything, error root cause discovery is still mostly manual, the haystack gets bigger and the needle is harder to find.
Step #3: Avoiding tedious log analysis
Let’s assume we have some error, a specific transaction that fails some of the time. We now have to find all the relevant information about it in our log files. Time to grep our way through the logs, or play around with different queries in tools that make the search quicker like Splunk, ELK, or other log management tools.
To make this process easier, developers who use Takipi are able to extend the context of each logged error, warning and exception into the source, state and variable state that caused it. Each log line gets a link appended to it that leads to the event’s analysis in Takipi:
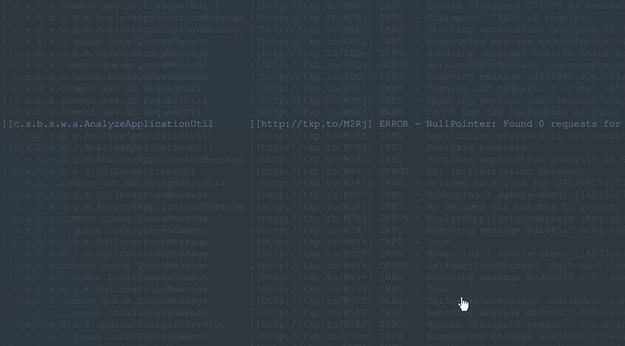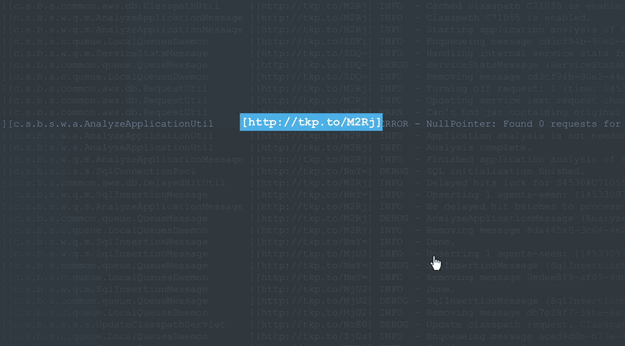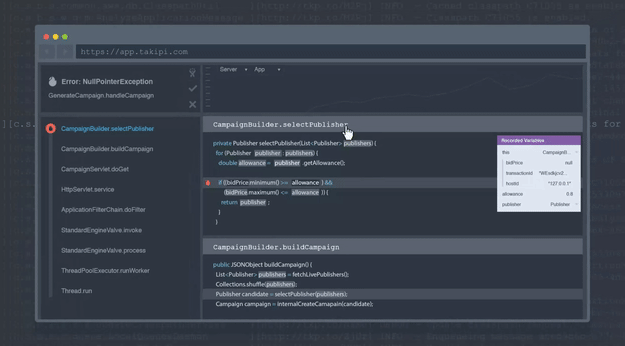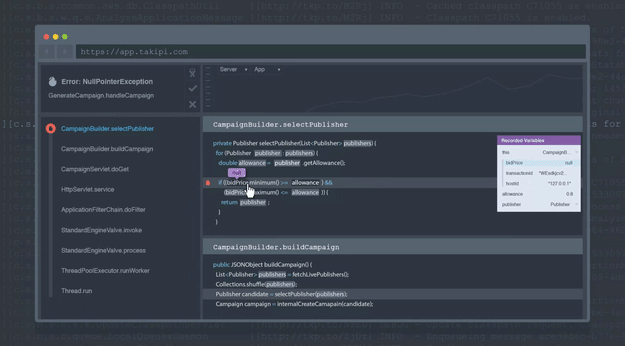
Bottom line: Manually sifting through logs is a tedious process that can be avoided.
Step #4: Realizing that production log levels aren’t verbose enough
Log levels are a double edged sword. The more levels you log in production, the more context you have. BUT, the extra logging creates overhead that is best to avoid in production. Sometimes, the additional data you need would exist in a “DEBUG” or an “INFO” message, but production applications usually only write “WARN” level messages and above.
The way we solve this in Takipi is with a recently released new feature that gives you the ability to see the last 250 log statements within the thread leading up to an error. Even if they were not written to the log file in production.
Wait, what? Logless logging with no additional overhead. Since log statements are captured directly in-memory, without relying on log files, we’re able to do full verbosity, in production, without affecting log size or creating overhead. You can read more about it right here, or try it yourself.
Bottom line: As of today you’re not limited to WARN and above levels in production logging.
Step #5: Next person who says “cannot reproduce” buys a round of drinks
Probably the most common excuse for deferring a bug fix is “can’t reproduce”. An error that lacks the state that cause it. Something bad happens, usually you first hear about it from an actual user, and can’t recreate it or find evidence in the logs / collected metrics.
The hidden meaning of “can’t reproduce” is right at the source. If you’re used to first hearing about errors from users, there might be something wrong with the way errors are tracked internally. With proper monitoring in place, it’s possible to identify and solve errors before actual users report them.
Bottom line: Stop reproducing “cannot reproduce”.

Step #6: Breaking the log statements redeploy cycle
A common infamous and unfortunate cure for “cannot reproduce” is adding additional logging statements in production and hoping for the bug to happen again.
In production.
Messing up real users.
That’s the production debugging paradox right there. A bug happens, you don’t have enough data to solve it (but you do have lots of noise), adding logging statements, build, test (the same test that missed the bug in the first place), deploy to production, hope for it to happen again, hope for the new data to be enough or… repeat.
Bottom line: The ultimate goal for a successful monitoring strategy would be to prevent this cycle from happening.
Step #7: APM + Trackers + Metrics + Logs = Limited visibility
Let’s step it up a notch. We’ve covered logs and dashboard reporting metrics, now it’s time to add error tracking tools and APMs to the mix.
The fact is that even when a monitoring stack includes a solution from all 4 categories, the visibility you’re getting into application errors is limited. You’ll see the stack trace of the transaction, or at most specific predefined hardcoded variables. Traditional monitoring stacks have no visibility to the full state of the application at moment of error.
Bottom line: There’s a critical missing component in today’s common monitoring stack. Variable level visibility for production debugging.
Step #8: Preparing for distributed error monitoring
Monitoring doesn’t stop on the single server level, especially with microservice architectures where an error that formed on one server could be causing trouble elsewhere.
While microservices promote the “Separation of Concerns” principle, they’re also introducing a plethora of new problems at a server level scale. In this previous post we covered these issues and offered possible solution strategies.
Bottom line: Any monitoring solution should take distributed errors into account and be able to stitch in troubleshooting data from multiple sources.
Step #9: Find a way around long troubleshooting cycles
Whether it’s an alerting issue or simply a matter of priorities, for most applications the troubleshooting cycle takes days, weeks or even months after the first error was introduced. The person who reported the error might be unreachable or worse, the relevant data could be long gone / rolled over due to data retention policies.
The ability to freeze a snapshot of the application state at moment of error, even if it comes from multiple services / sources is critical in this case, otherwise the important data can be lost.
Bottom line: Long troubleshooting cycles should be avoided.
Step #10: Acknowledge the dev vs ops dilemma
Keeping up with release cycle issues, we’re all on the same boat, BUT, developers want to release features faster while operations would rather keep the production environment stable.
Short feature cycles and long troubleshooting cycles just don’t go together. There should be a balance between the two. Monitoring is a team sport, and the tools have to know how to speak to each other. For example, at Takipi you’re able to get alerts on Slack, Pagerduty or Hipchat, and directly open a JIRA ticket with all the available error analysis data.
Bottom line: Collaborative workflows speed up issue resolution times.
Step #11: There’s hope
Modern developer tools are taking big steps to improve on the current state of monitoring. Whether it’s in the field of logs, application performance management or the new categories that are in the works.
Bottom line: Keep an eye out for developments in the tooling ecosystem and best practices from other companies.
Step #12: Spread the word
Monitoring is an inseparable part of software development, let’s keep the discussion going!
We hope you’ve enjoyed this overview / rant of some of the main problems with the current state of monitoring. Are there any other issues with monitoring that keep you up at night?
Please feel free to share them in the comments section below.
| Reference: | The 12 Step Program to Realizing Your Java Monitoring is Flawed from our JCG partner Alex Zhitnitsky at the Takipi blog. |
