Offloading cold or unused data and ETL workloads from a data warehouse to Hadoop/big data platforms is a very common starting point for enterprises beginning their big data journey. Platforms like Hadoop provide an economical way to store data and do bulk processing of large data sets; hence, it’s not surprising that cost is the primary driver for this initial use case.
What do these projects look like when they are actually implemented? In this post, we’ll take a look at the different factors to think about, we’ll provide a methodology for implementing data warehouse offloads, and demonstrate how things translate in a Hadoop/big data world. In the traditional data warehouse world, people are very used to sequencing tasks and workflows. Data has to be extracted from source systems, transformed, and then loaded into the target, i.e., data warehouses.
In the traditional data warehousing world, structure and schemas are essential, which lead to clearly defined transformations. In the Hadoop and big data world, data doesn’t need to be stored as a structured format. New tools work without schema, or apply schema on read, or are optimized for columnar, key value pair and document databases as such. There is no real extract and loading—it’s all about the transformations that occur after the data lands in the cluster. When offloading from a data warehouse, both data and transformations are being moved. Data lifecycle is an important topic with three main areas to consider: data ingest, data integrations, and data delivery.
- Data Ingest: When it comes to data ingestion, what’s important is to map out your existing data flows to understand what modifications might be necessary in the Hadoop architecture. MapR offers various alternatives when it comes to ingest. You can use the unique NFS capability that comes only with the MapR Platform to ingest data into the cluster. Tools such as SQOOP or other third party tools like Informatica can also be used. On the storage side, it’s important to understand if data needs to be partitioned by day, for example, and whether updates will be incremental or full rewrites. When it comes to transformations, the big difference in the Hadoop world is that these occur after the fact and the critical step of defining a schema for transforming data is not a requirement.
- Data Integrations: In the traditional world of data warehousing, customers have often built their data models using a star schema methodology, or a 3NF, or perhaps a mix of both. These techniques provide a compact relational understanding of the data and comprise a centralized data model. This can be leveraged in the Hadoop architecture and one can build data microservices on top of this which can be denormalized, cubed, or otherwise aggregated and interpreted for specific applications.
- Data Delivery: At some point within the big data journey, customers will want to have to some sort of OLAP-like capabilities and build cubes to surface data easily to end users. Using tools from the broad Hadoop ecosystem, these data “microservices” can be built on top of streaming and batch models, using SQL and full programming languages, or perhaps with tools such at Atscale.
The below visual shows how the data lifecycle is accomplished and aids in offloading data and transformations to a Hadoop-based environment.
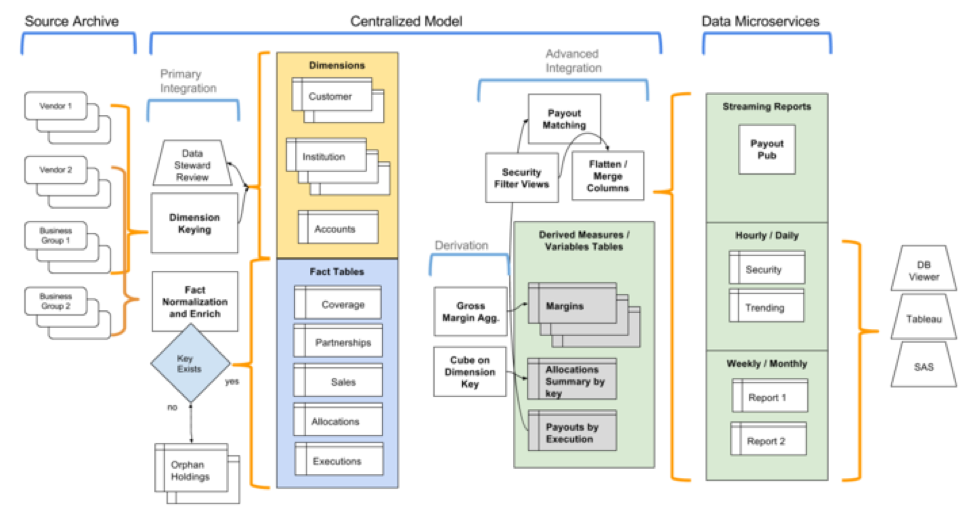
Another key topic to address is around data structures. There are potential decisions to be made on data models regarding architecture in the context of data warehouse offloads.
- Some of the unique capabilities offered in the MapR Platform with MapR-DB can help facilitate key-based lookups, even through SQL as an example.
- When it comes to delimited files, the MapR Platform can work directly on these, removing the need to architect metadata for these files, which can then be put in compressed indexed formats like Avro and Parquet to speed up regular reporting and exploration queries.
- JSON is increasingly becoming a key format for nested data and is very flexible. Handling JSON data is a key strength for the MapR Platform. In the data warehousing world, it’s common to find 2D table structures and various aggregations to put nested dimensional data into different entities. These can be interpreted differently by different functions within an organization. Restructuring these entities provides a distinct challenge in a pure relational data warehousing data flow, but can be handled more easily by using JSON in the MapR Platform.
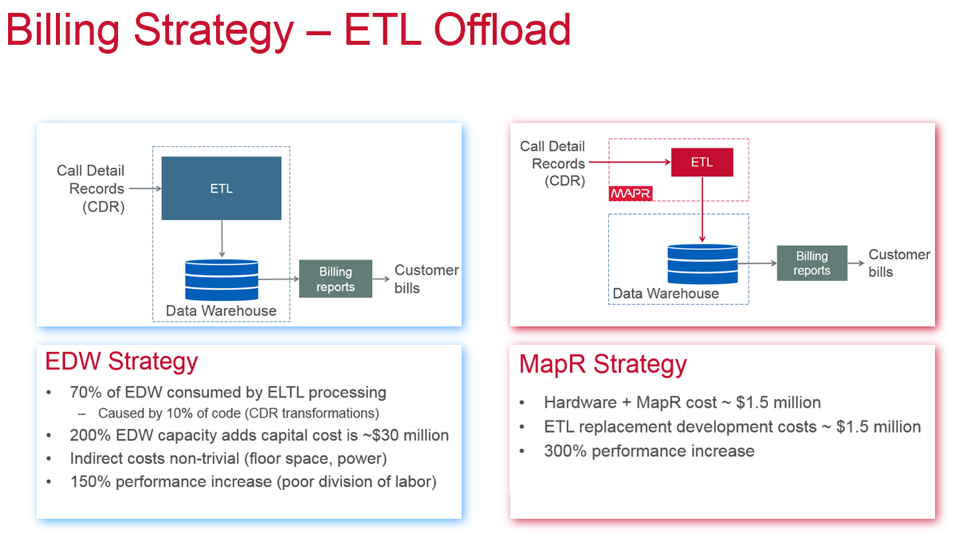
Above is an example of a customer in the telecommunications space that migrated portions of their data warehouse workload to a MapR cluster. You can see that they are benefiting from both a performance and price perspective.
When it finally comes to data migration, there are a couple of different perspectives to consider and where the MapR Platform can help this effort.
- Existing stored procedures implemented in a current data warehouse implementation can be moved over with reasonable effort, though this will require some development efforts to cover for platform specific features (Teradata, Oracle) and SQL compatibility.
- On the systems architecture front, components can be ported to different toolsets altogether (e.g., SQL to Pig) but with the ability to retain their interfaces to other parts of the data workflow. Re-architecting at this level can improve development speed and manageability, while helping facilitate a more intuitive and efficient interface to other processes in the data workflow.
Summary
After the data migration and transformation efforts are done, there are quite a few downstream benefits. New analytical tools and methods can be applied to derive new business insights. Use cases such as customer 360 and deeper analytics on existing business processes can be made available to business stakeholders and improve operational efficiency. As seen in the customer example above, there are cost savings and performance improvements to be gained as well. Clearly, data warehouse migration and offload initiatives can benefit not only the bottom line but also the top line. For more information on solutions MapR offers in this area, we encourage you to check out the data warehouse optimization area on our website.
| Reference: | Best Practices on Migrating from a Data Warehouse to a Big Data Platform from our JCG partner Sameer Nori at the Mapr blog. |
