In this article, author of the book “High Performance in-memory computing with Apache Ignite”, will discuss the complex event processing with Apache Strom and the Apache Ignite. Part of this article taken from the complex event processing chapter of the
book.
There is no broadly or highly accepted definition of the term Complex Event Processing or CEP. What Complex Event Processing is may be briefly described as the following quote from the Wikipedia:
“Complex Event Processing, or CEP, is primarily an event processing concept that deals with the task of processing multiple events with the goal of identifying the meaningful events within the event cloud. CEP employs techniques such as detection of complex patterns of many events, event correlation and abstraction, event hierarchies, and relationships between events such as causality, membership, and timing, and event-driven processes.”
For simplicity, Complex Event Processing (CEP) is a technology for low-latency filtering, aggregating and computing on real-world never ending or streaming event data. The quantity and speed of both raw infrastructure and business events are exponentially growing in IT environments. In addition, the explosion of mobile devices and the ubiquity of high-speed connectivity add to the explosion of mobile data. At the same time, demand for business process agility and execution has only grown. These two trends have put pressure on organizations to increase their capability to support event-driven architecture patterns of implementation. Real-time event processing requires both the infrastructure and the application development environment to execute on event processing requirements. These requirements often include the need to scale from everyday use cases to extremely high velocities or varieties of data and event throughput, potentially with latencies measured in microseconds rather than seconds of response time.
Apache Ignite allows processing continuous never-ending streams of data in scalable and fault-tolerant fashion in in-memory, rather than analyzing data after it’s reached the database. Not only does this enable you to correlate relationships and detect meaningful patterns from significantly more data, you can do it faster and much more efficiently. Event history can live in memory for any length of time (critical for long-running event sequences) or be recorded as transactions in a stored database.
Apache Ignite CEP can be used in a wealth of industries area, the following are some first class use cases:
- Financial services: the ability to perform real-time risk analysis, monitoring and reporting of financial trading and fraud detection.
- Telecommunication: ability to perform real time call detail record and SMS monitoring and DDoS attack.
- IT systems and infrastructure: the ability to detect failed or unavailable application or servers in real time.
- Logistics: ability to track shipments and order processing in real-time and reports on potential delays on arrival.
There are a few more industrials or functional areas, where you can use Apache Ignite to process streams event data such as Insurance, transportation and Public sector. Complex event processing or CEP contains three main parts of its process:
- Event Capture or data ingesting.
- Compute or calculation of these data.
- Response or action.
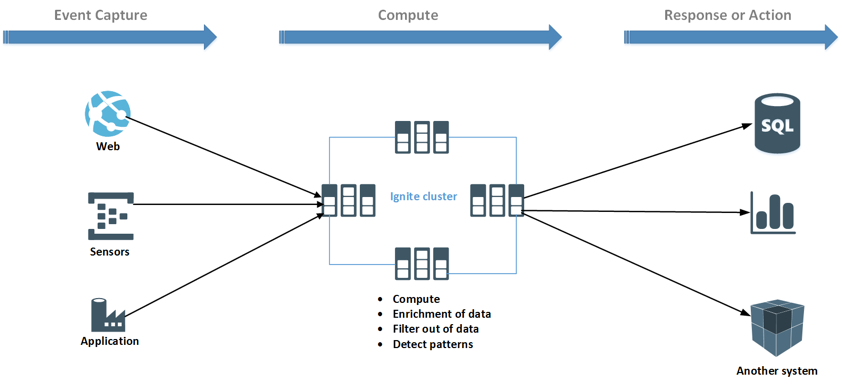
As shown in the above figure, data are ingesting from difference sources. Sources can be any sensors (IoT), web application or industry applications. Stream data can be concurrently processed directly on the Ignite cluster in collecting fashion. In addition, data can be enriched from other sources or filter out. After computing the data, computed or aggregated data can be exported to other systems for visualizing or taking an action.
Apache Ignite Storm Streamer module provides streaming via Storm to Ignite cache. Before start using the Ignite streamer lets take a look at the Apache Storm to get a few basics about apache Storm.
Apache storm is a distributed fault-tolerant real-time computing system. In a short time, Apache Storm became a standard for distributed real-time processing system that allows you to process a large amount of data. Apache Storm project is open source and written in Java and Clojure. It became a first choose for real-time analytics. Apache Ignite Storm streamer module provides a convenience way to streaming data via Storm to Ignite cache.
Key concepts:
Apache Storm reads raw stream of data from the one end and passes it through a sequence of small processing units and output the processed information at the other end. Let’s have a detailed look at the main components of Apache Storm –
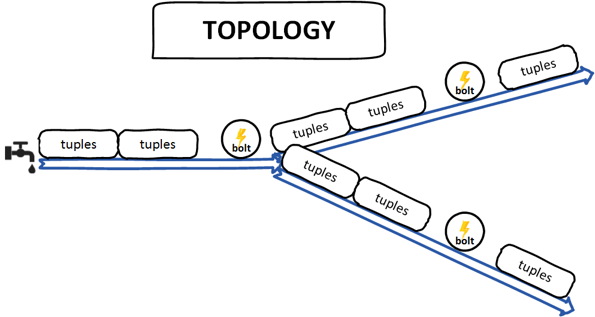
Tuples – It is the main data structure of the Storm. It’s an ordered list of elements. Generally, tuple supports all primitives data types.

Streams – It’s an unbound and un-ordered sequence of tuples.
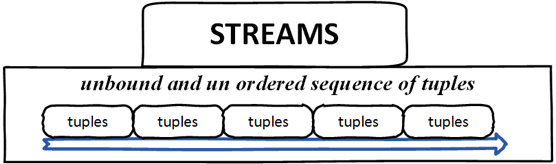
Spouts – Source of streams, in simple terms, a spout reads the data from a source for use in topology. A spout can reliable or unreliable. A spout can talk with Queues, Web logs, event data etc.
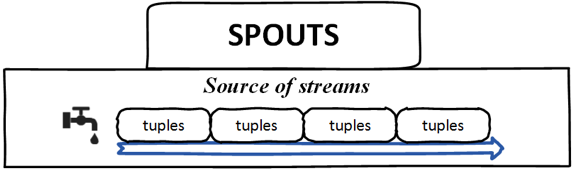
Bolts – Bolts are logical processing units, it is responsible for processing data and creating new streams. Bolts can perform the operations of filtering, aggregation, joining, interacting with files/database and so on. Bolts receive data from the spout and emit to one or more bolts.
Topology – A topology is a directed graph of Spouts and Bolts, each node of this graph contains the data processing logic (bolts) while connecting edges define the flow of the data (streams).
Unlike Hadoop, Storm keeps the topology running forever until you kill it. A simple topology starts with spouts, emit stream from the sources to bolt for processing data. Apache Storm main job is to run the topology and will run any number of topology at given time.
Ignite out of the box provides an implementation of Storm Bolt (StormStreamer) to streaming the computed data into Ignite cache. On the other hand, you can write down your custom Strom Bolt to ingest stream data into Ignite. To develop a custom Storm Bolt, you just have to implement *BaseBasicBolt* or *IRichBolt* Storm interface. However, if you decide to use StormStreamer, you have to configure a few properties to work the Ignite Bolt correctly. All mandatory properties are shown below:
| No | Property Name | Description |
|---|---|---|
| 1 | CacheName | Cache name of the Ignite cache, in which the data will,be store. |
| 2 | IgniteTupleField | Names the Ignite Tuple field, by which tuple data is,obtained in topology. By default the value is ignite. |
| 3 | IgniteConfigFile | This property will set the Ignite spring configuration file. Allows you to send and consume message to and from Ignite topics. |
| 4 | AllowOverwrite | It will enabling overwriting existing values in the,cache, default value is false. |
| 5 | AutoFlushFrequency | Automatic flush frequency in milliseconds. Essentially,,this is the time after which the streamer will make an attempt to submit all data added so far to remote nodes. Default is 10 sec. |
Now that we have got the basics, let’s build something useful to check how the Ignite StormStreamer works. The basic idea behind the application is to design one topology of spout and bolt that can process a huge amount of data from a traffic log files and trigger an alert when a specific value crosses a predefined threshold. Using a topology, the log file is read line by line and the topology is designed to monitor the incoming data. In our case, the log file will contain data, such as vehicle registration number, speed and the highway name from highway traffic camera. If the vehicle crosses the speed limit (for example 120km/h), Storm topology will send the data to Ignite cache.
Next listing will show a CSV file of the type we are going to use in our example, which contain vehicle data information such as vehicle registration number, the speed at which the vehicle is traveling and the location of the highway.
01 02 03 04 05 06 07 08 09 10 11 12 | AB 123, 160, North cityBC 123, 170, South cityCD 234, 40, South cityDE 123, 40, East cityEF 123, 190, South cityGH 123, 150, West cityXY 123, 110, North cityGF 123, 100, South cityPO 234, 140, South cityXX 123, 110, East cityYY 123, 120, South cityZQ 123, 100, West city |
The idea of the above example is taken from the Dr. Dobbs journal. Since this book is not for studying Apache Storm, I am going to keep the example simple as possible. Also, I have added the famous word count example of Storm, which ingests the word count value into Ignite cache through StormStreamer module. If you are curious about the code, it’s available at
chapter-cep/storm. The above CSV file will be the source for the Storm topology.
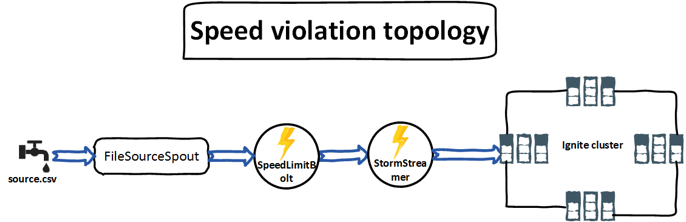
As shown in above figure, the FileSourceSpout accepts the input CSV log file, reads the data line by line and emits the data to the SpeedLimitBolt for further threshold processing. Once the processing is done and found any car with exceeding the speed limit, the data is emitted to the Ignite StormStreamer bolt, where it is ingested into the cache. Let’s dive into the detailed explanation of our Storm topology.
Step 1:
Because this is a Storm topology, you must add the Storm and the Ignite StormStreamer dependency in the maven project.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | <dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-storm</artifactId> <version>1.6.0</version></dependency><dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-core</artifactId> <version>1.6.0</version></dependency><dependency> <groupId>org.apache.ignite</groupId> <artifactId>ignite-spring</artifactId> <version>1.6.0</version></dependency><dependency> <groupId>org.apache.storm</groupId> <artifactId>storm-core</artifactId> <version>0.10.0</version> <exclusions> <exclusion> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> </exclusion> <exclusion> <groupId>commons-logging</groupId> <artifactId>commons-logging</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> </exclusion> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> </exclusions></dependency> |
At the time of writing this book, Apache Storm version 0.10.0 is only supported. Note that, You do not need any Kafka module to run or execute this example as describe in the Ignite documentation.
Step 2:
Create an Ignite configuration file (see example-ignite.xml file in /chapter-cep/storm/src/resources/example-ignite.xml) and make sure that it is available from the classpath. The content of the Ignite configuration is identical from the previous section of this chapter.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | xsi:schemaLocation=" <bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration"> <!-- Enable client mode. --> <property name="clientMode" value="true"/> <!-- Cache accessed from IgniteSink. --> <property name="cacheConfiguration"> <list> <!-- Partitioned cache example configuration with configurations adjusted to server nodes'. --> <bean class="org.apache.ignite.configuration.CacheConfiguration"> <property name="atomicityMode" value="ATOMIC"/> <property name="name" value="testCache"/> </bean> </list> </property> <!-- Enable cache events. --> <property name="includeEventTypes"> <list> <!-- Cache events (only EVT_CACHE_OBJECT_PUT for tests). --> <util:constant static-field="org.apache.ignite.events.EventType.EVT_CACHE_OBJECT_PUT"/> </list> </property> <!-- Explicitly configure TCP discovery SPI to provide list of initial nodes. --> <property name="discoverySpi"> <bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi"> <property name="ipFinder"> <bean class="org.apache.ignite.spi.discovery.tcp.ipfinder.vm.TcpDiscoveryVmIpFinder"> <property name="addresses"> <list> <value>127.0.0.1:47500</value> </list> </property> </bean> </property> </bean> </property> </bean></beans> |
Step 3:
Create an ignite-storm.properties file to add the cache name, tuple name and the name of the Ignite configuration as shown below.
1 2 3 | cache.name=testCachetuple.name=igniteignite.spring.xml=example-ignite.xml |
Step 4:
Next, create FileSourceSpout Java class as shown below,
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | public class FileSourceSpout extends BaseRichSpout { private static final Logger LOGGER = LogManager.getLogger(FileSourceSpout.class); private SpoutOutputCollector outputCollector; @Override public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { this.outputCollector = spoutOutputCollector; }@Override public void nextTuple() { try { Path filePath = Paths.get(this.getClass().getClassLoader().getResource("source.csv").toURI()); try(Stream<String> lines = Files.lines(filePath)){ lines.forEach(line ->{ outputCollector.emit(new Values(line)); }); } catch(IOException e){ LOGGER.error(e.getMessage()); } } catch (URISyntaxException e) { LOGGER.error(e.getMessage()); } } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields("trafficLog")); }} |
The FileSourceSpout code has three important methods
- open(): This method would get called at the start of the spout and will give you context information.
- nextTuple(): This method would allow you to pass one tuple to Storm topology for processing at a time, in this method, I am reading the CSV file line by line and emitting the line as a tuple to the bolt.
- declareOutputFields(): This method declares the name of the output tuple, in our case, the name should be trafficLog.
Step 5:
Now create SpeedLimitBolt.java class which implements BaseBasicBolt interface.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | public class SpeedLimitBolt extends BaseBasicBolt { private static final String IGNITE_FIELD = "ignite"; private static final int SPEED_THRESHOLD = 120; private static final Logger LOGGER = LogManager.getLogger(SpeedLimitBolt.class); @Override public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) { String line = (String)tuple.getValue(0); if(!line.isEmpty()){ String[] elements = line.split(","); // we are interested in speed and the car registration number int speed = Integer.valueOf((elements[1]).trim()); String car = elements[0]; if(speed > SPEED_THRESHOLD){ TreeMap<String, Integer> carValue = new TreeMap<String, Integer>(); carValue.put(car, speed); basicOutputCollector.emit(new Values(carValue)); LOGGER.info("Speed violation found:"+ car + " speed:" + speed); } } } @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { outputFieldsDeclarer.declare(new Fields(IGNITE_FIELD)); }} |
Let’s go through line by line again.
- execute(): This is the method where you implement the business logic of your bolt, in this case, I am splitting the line by the comma and check the speed limit of the car. If the speed limit of the given car is higher than the threshold, we are creating a new treemap data type from this tuple and emit the tuple to the next bolt, in our case the next bolt will be the StormStreamer.
- declareOutputFields(): This method is similar to declareOutputFields() method in FileSourceSpout, it declares that it is going to return Ignite tuple for further processing.
Note that, The tuple name IGNITE is important here, the StormStreamer will only process the tuple with name Ignite.
Step 6:
It’s the time to create our topology to run our example. Topology ties the spouts and bolts together in a graph, which defines how the data flows between the components. It also provides parallelism hints that Storm uses when creating instances of the components within the cluster. To implement the topology, create a new file named SpeedViolationTopology.java in the src\main\java\com\blu\imdg\storm\topology directory. Use the following as the contents of the file:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | public class SpeedViolationTopology { private static final int STORM_EXECUTORS = 2; public static void main(String[] args) throws Exception { if (getProperties() == null || getProperties().isEmpty()) { System.out.println("Property file <ignite-storm.property> is not found or empty"); return; } // Ignite Stream Ibolt final StormStreamer<String, String> stormStreamer = new StormStreamer<>(); stormStreamer.setAutoFlushFrequency(10L); stormStreamer.setAllowOverwrite(true); stormStreamer.setCacheName(getProperties().getProperty("cache.name")); stormStreamer.setIgniteTupleField(getProperties().getProperty("tuple.name")); stormStreamer.setIgniteConfigFile(getProperties().getProperty("ignite.spring.xml")); TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new FileSourceSpout(), 1); builder.setBolt("limit", new SpeedLimitBolt(), 1).fieldsGrouping("spout", new Fields("trafficLog")); // set ignite bolt builder.setBolt("ignite-bolt", stormStreamer, STORM_EXECUTORS).shuffleGrouping("limit"); Config conf = new Config(); conf.setDebug(false); conf.setMaxTaskParallelism(1); LocalCluster cluster = new LocalCluster(); cluster.submitTopology("speed-violation", conf, builder.createTopology()); Thread.sleep(10000); cluster.shutdown(); } private static Properties getProperties() { Properties properties = new Properties(); InputStream ins = SpeedViolationTopology.class.getClassLoader().getResourceAsStream("ignite-storm.properties"); try { properties.load(ins); } catch (IOException e) { e.printStackTrace(); properties = null; } return properties; }} |
Let’s go through line by line again. First, we read the ignite-strom.properties file to get all the necessary parameters to configure the StormStreamer bolt next. The storm topology is basically a Thrift structure. The TopologyBuilder class provides the simple and elegant way to build complex Storm topology. The TopologyBuilder class has methods to setSpout and setBolt. Next, we used the Topology builder to build the Storm topology and added the spout with name spout and parallelism hint of 1 executor.
We also define the SpeedLimitBolt to the topology with parallelism hint of 1 executor. Next we set the StormStreamer bolt with shufflegrouping, which subscribes to the bolt, and equally, distributes tuples (limit) across the instances of the StormStreamer bolt.
For development purpose, we create a local cluster using LocalCluster instance and submit the topology using the submitTopology method. Once the topology is submitted to the cluster, we will wait 10 seconds for the cluster to compute the submitted topology and then shutdown the cluster using shutdown method of LocalCluster.
Step 7:
Next, run a local node of Apache Ignite or cluster first. After building the maven project, use the following command to run the topology locally.
1 | mvn compile exec:java -Dstorm.topology=com.blu.imdg.storm.topology.SpeedViolationTopology |
The application will produce a lot of system logs as follows.
Now, if we verify the Ignite cache through ignitevisior, we should get the following output into the console.

The output shows the result, what we expected. From our source.csv log file, only five vehicles exceed the speed limit of 120 km/h.
This is pretty much sums up the practical overview of the Ignite Storm Streamer. If you are curious about Ignite Camel or Ignite Flume streamer please refer to the book “High performance in-memory computing with Apache Ignite”. You can also contact the author for the free copy of the book, the book is freely distributed for Students and the teachers.
| Reference: | Complex event processing (CEP) with Apache Storm and Apache Ignite from our JCG partner Shamim Bhuiyan at the My workspace blog. |
