At Keyhole Software we are in large part a modernization company. We have consultants who specialize in moving old to new, renovating dilapidated code bases, and designing brighter futures for enterprises that have been vendor-locked for most of their existence.
As an interesting side effect of these experiences, we have come across some repeated patterns and strategies for how to approach modernization of legacy systems.
In this blog, we will cover a strategy that seems to be very popular right now, Re-Platforming, and we will demonstrate it with a Keyhole Labs product that we have developed. The basic flow of this post will be:
- Introduction to Modernization
- High-level definition of the Re-Platforming Strategy
- Sample of Re-platforming using Keyhole Syntax Tree Transformer
- Closing arguments
- Summary
“I’ll take one Modernization please… no wait, maybe two…”
When we first engage clients around the topic of Modernization, we are presented with wildly varying definitions of what they actually want to accomplish in the process. These range from getting off of a mainframe application, to moving on from an ESB/classic SOA architecture into a cloud-based PaaS implementation, to migrating to a DevOps/Microservices architecture from a vendor-locked/layered architecture.
All of these scenarios are occurring with more frequency as companies that updated their tech stack as recently as a decade ago are running into some of the key problems of successful operation or growth:
- Deployment woes: Everything has to be deployed as one unit and is a painful process and/or is tightly coupled to all of its infrastructure
- Scalability woes: The vertical limits of scalability are being hit – meaning the machines cannot get bigger fast enough to handle increases in capacity
- Performance woes: The volume of messages/transactions through the system is increasing latency and in some cases causing cascading failures
- Resource woes: The engineers and computer scientists who worked on this system originally are no longer around or are retiring, and the programming language is not being taught in schools anymore
Thus, enter modernization initiatives. Let’s start out by reviewing the Re-Platforming strategy and its benefits and drawbacks.
“Re-Platform? Is that like fixing my boots?”
Re-Platform is sometimes called lift-and-shift. At its core, re-platform is transpiling, meaning translating, one code language into another. As a modernization strategy, this means converting older code languages into newer ones.
Mainframes are still prevalent in some larger enterprises for a myriad of reasons, and because of this, older code bases like COBOL still exist as well. The reasons to get off of these older code bases and mainframes are usually one of the following:
- Resource issues (as mentioned above): mainframe programmers are becoming scarce and those language sets are not being covered in modern curriculums in any depth. It is harder to recruit new developers, especially when rapid change and ever-widening technology choices are becoming the norm. Fewer staff are willing to work on what is considered, by some, deprecated technology.
- Mainframes can be a large expense for enterprises of any size with the only option for growth being vertical scaling – which is sometimes punitively expensive.
Disaster recovery and high-availability strategies common in most modern architectures can be cost-prohibitive with mainframes. - Newer programming patterns cannot be easily leveraged in procedural language constructs (OOP, Functional programming, Reactive programming, etc…) – thus limiting options.
- A change in the SDLC – i.e. moving from waterfall to Agile process to stay competitive.
So, to make a long story endless – what do we actually mean when we say “Re-Platforming”?
This is a process where older code bases are analyzed to determine a grammar or patterns in the code base.
Once either a grammar tree or a set of code patterns has been defined, the original code base (i.e. COBOL) is run through some single or multi-step compiler-compiler software to convert the legacy code into the desired end state – usually Java, C# or newer language equivalent.
From a business perspective, this can be very appealing. Instead of staffing up teams of product owners and developers to gradually re-write each of the legacy code bits in a new language – this method carries the promise of doing all the heavy lifting with a couple of button pushes. Sounds great!
Well, hold on a sec there, professor – there are inherent problems with this approach that need to be mentioned before we proceed. The hardest things to realize are:
Code translation does not necessarily fix technical debt!
In some cases, these legacy code bases may have been around for 20+ years. That is potentially 20+ years of bad, or mainframe-specific decisions baked into your code.
All the translation process will give you is those potential code landmines now in a newer language that may not benefit from some of the mainframe’s generosity and horsepower.
The code could come out looking worse than it did on the mainframe!
Running code through this process can sometimes ending up looking like it has been thrown through a wood chipper. Some mainframe and legacy code constructs/behaviors do not translate well or at all into newer code bases. (For example: at a recent client, we found an example where in one code base the mathematical operation of x/0 returned 0!)
Even if the code converts and looks fine, that does not mean it will always run!
Just translating into another language does not guarantee execution – an initial successful translation usually means no syntax errors.
Some tweaking, additional infrastructure may need to be in place to help the code work and build.
Running != Performing
Again, if we get it running and building, all may seem great in our pilot conversion. Once we throw millions of transactions and records at it to process – you will find all the holes in the bucket.
Complexity will most likely not be reduced by this process!
During this process, you are most likely going from something that handles all of its complexity in-process (and in some cases with little or no i/o penalties), into something less generous with its resources.
Moving these code bases into newer languages, usually involves some separation of concerns:
- data access layer opposed to in-line SQL statements
- potential new relational data stores opposed to file-based data stores
- presentation layer opposed to UI code baked right in
- service/business logic layer as its own layer
Some additional infrastructure may be needed to handle things that the mainframe did for free
Like messaging, container or vm orchestration, queues and AD/LDAP/OAuth integration, etc.
So now you are probably feeling like you just stepped into a pharmaceutical commercial where I said:
“This tiny little pill will solve all your back pain and yellow toenail issues. Potential side effects may include vomiting, bleeding from the eyes and/or ears, temporary vision loss, spontaneous baldness and painful sensitivity to the letter ‘A’.”
However, this can be a successful journey if you focus on the following:
- If you have a large code base in legacy/mainframe languages, this process can get your code base into a more modern code base very quickly.
- From this point – your dev teams will be much more capable of renovating the applications in your desired end state just by the simple fact that they can now read the code.
If you select a process that can utilize a grammar tree for the initial conversion…
You can quickly pivot and adjust your renovated output by just adjusting the grammar and re-running.
Sometimes pattern-based conversion is the only option. But, in many cases, a grammar tree can be generated – and then you simply adjust your grammar, instead of the output or the individual patterns on a one-off basis.
Keyhole’s Syntax Tree Transformer and its proprietary COBOL Grammar Parser, are grammar-based and built to do exactly this!
This can be a viable option to get you there in a phased implementation…
Especially if your organization is not staffed to handle the conversion of potentially thousands of programs into the new stack.
By converting all of your legacy code in short time, you can get off the old technologies much sooner. Then you can re-allocate those resources to analyze and re-write or clean-up the parts of the code with the most business value and ROI.
This enables the organization to make more purposeful decisions on what is actually important to the business.
Provides valuable insight and analysis into the business logic being applied in your code base.
In several cases, the business logic may be as old as the code base and no longer apply. Most clients find a great deal of value in this and end up reducing their code base to be converted by 10-25% just through the analysis activity.
An opportunity to introduce DevOps as a part of the conversion.
Depending on the desired end-state of the code, an opportunity to introduce DevOps as a part of the conversion can be beneficial beyond the conversion process. Sometimes “having” to stand up some tooling or implement a new process ends up as an opportunity to inject best practices without going through as much red tape or gateways.
These newer processes and tooling can be leveraged by other areas of the business and add value by increasing agility and causing some culture shifts.
This process can be a short-term budgetary win-win.
With the potential for a quick conversion and deprecation of mainframe and older technologies, capital expense and maintenance costs can be reclaimed.
The overall cost of development to get the code into this converted state is usually smaller than manual team rewrites.
The caveat with this item is that long term, this may be a more expensive undertaking because of the amount of code now in newer languages and infrastructures – new/additional resources may be required to maintain and grow the code base. –But at least you should be able to find them!
The gist of this strategy is:
If you make sure you realize what the process can actually do and select a robust, grammar-based tool (like Keyhole Syntax Tree Transformer and our Parser – just sayin’), you can achieve a very predictable result that can get you budgetary and time wins.
Now that we have been through the definition and pros-cons of implementing this strategy, lets actually get our hands mildly dirty. Our use case for this article will be going from COBOL to JAVA using our Keyhole Syntax Tree Transformer.
“Let’s Re-Platform Already!”
To begin this example, we are going to start with a sample bit of COBOL that has been converted to a JSON syntax tree by our proprietary grammar parser. The COBOL program just reads a DB2 data store and returns a list of employees. We will not be showing the actual conversion of COBOL to JSON – instead we will start from an already converted COBOL program.
(Sorry, this is the secret sauce of the blog post – so we are going to do this cooking show style and start with a turkey we already prepared last night! If you are interested in process for your organization or would like a demo – please contact us).
To begin, there are a couple of setup items that we need to cover:
- You will need to clone this repo for this example: https://github.com/in-the-keyhole/khs-syntax-tree-transformer
- You will need to be on a machine that has support for Docker (Windows 10, various flavors of Linux, Mac). This is for the DB2 example, if you don’t want to mess with Docker there is a simple COBOL example in the repo.
- This is a contrived example! It is not meant to cure any disease or be used in any production environment! It is meant to demonstrate the mechanism and show how going from a syntax tree to a Java application.
OK, let’s get to it!
Step One:
After you have cloned the repo, import it as a Maven Project into Eclipse, STS or Intellij.
Step Two:
Execute the main method with command line arguments for JSON input file and emitted Java package name. Like so:
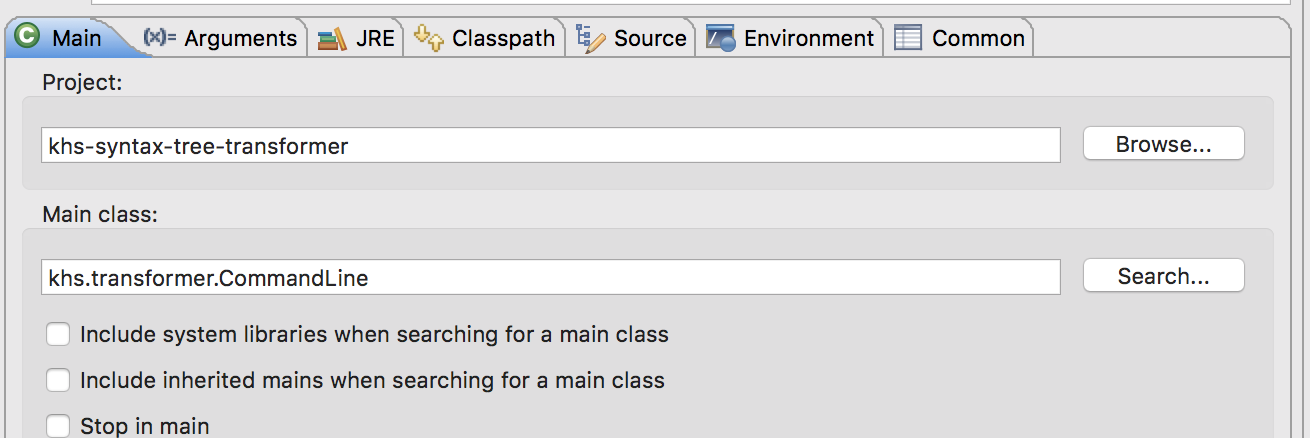
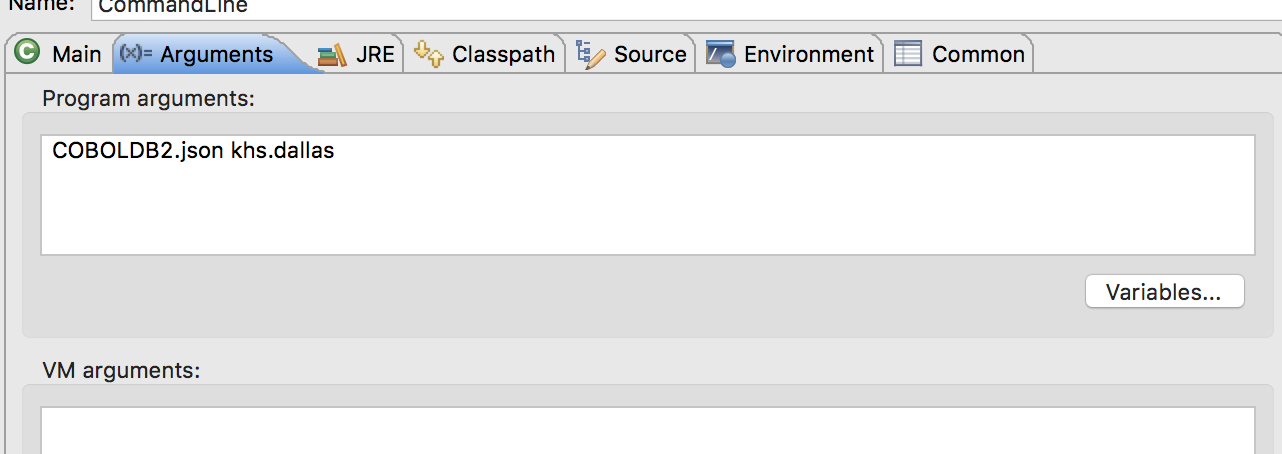
This produces an emitted Program.java program in the project directory:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | package khs.res.example.Programpublic class Program { private Double CONST-PI = null; private Double WORK-1 = 0; private Double WORK-2 = 0; private Double PRINT-LINE = null; public void static main(String[] args) { Program job = new Program (); job.A-PARA (); } public void A-PARA () { WORK-1 = 123.46 WORK-2 = WORK-2+2 WORK-2 = WORK-3*3 C-PARA() } public void B-PARA () { CONST-PI = Math.PI; EDT-ID = ZERO } public void C-PARA () { B-PARA() }} |
The following is the input demo.json created by our secret sauce parser that our program will use:
001 002 003 004 005 006 007 008 009 010 011 012 013 014 015 016 017 018 019 020 021 022 023 024 025 026 027 028 029 030 031 032 033 034 035 036 037 038 039 040 041 042 043 044 045 046 047 048 049 050 051 052 053 054 055 056 057 058 059 060 061 062 063 064 065 066 067 068 069 070 071 072 073 074 075 076 077 078 079 080 081 082 083 084 085 086 087 088 089 090 091 092 093 094 095 096 097 098 099 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 | { "name" : "Program", "typeName" : "CLASS", "variables" : [ { "name" : "CONST-PI", "typeName" : "VARIABLE", "value" : null, "isLocal" : false, "isWorking" : true, "isArray" : false, "fileLevel" : null, "variables" : [ ] }, { "name" : "WORK-1", "typeName" : "VARIABLE", "value" : "ZERO", "isLocal" : false, "isWorking" : true, "isArray" : false, "fileLevel" : null, "variables" : [ ] }, { "name" : "WORK-2", "typeName" : "VARIABLE", "value" : "ZERO", "isLocal" : false, "isWorking" : true, "isArray" : false, "fileLevel" : null, "variables" : [ ] }, { "name" : "PRINT-LINE", "typeName" : "VARIABLE", "value" : null, "isLocal" : false, "isWorking" : true, "isArray" : true, "fileLevel" : null, "variables" : [ { "name" : "EDT-ID", "typeName" : "VARIABLE", "value" : "SPACES", "isLocal" : false, "isWorking" : true, "isArray" : false, "fileLevel" : null, "variables" : [ ] }, { "name" : "FILLER", "typeName" : "VARIABLE", "value" : "' Perimeter '", "isLocal" : false, "isWorking" : true, "isArray" : false, "fileLevel" : null, "variables" : [ ] }, { "name" : "EDT-3-15-CIR", "typeName" : "VARIABLE", "value" : null, "isLocal" : false, "isWorking" : true, "isArray" : false, "fileLevel" : null, "variables" : [ ] }, { "name" : "FILLER", "typeName" : "VARIABLE", "value" : "' Radius '", "isLocal" : false, "isWorking" : true, "isArray" : false, "fileLevel" : null, "variables" : [ ] }, { "name" : "EDT-3-15-RAD", "typeName" : "VARIABLE", "value" : null, "isLocal" : false, "isWorking" : true, "isArray" : false, "fileLevel" : null, "variables" : [ ] }, { "name" : "FILLER", "typeName" : "VARIABLE", "value" : "' Pi '", "isLocal" : false, "isWorking" : true, "isArray" : false, "fileLevel" : null, "variables" : [ ] }, { "name" : "EDT-1-15-PI", "typeName" : "VARIABLE", "value" : null, "isLocal" : false, "isWorking" : true, "isArray" : false, "fileLevel" : null, "variables" : [ ] } ] } ], "functions" : [ { "name" : "A-PARA", "typeName" : "FUNCTION", "methods" : [ { "name" : "123.46TOWORK-1", "typeName" : "METHOD", "type" : { "name" : null, "typeName" : "MOVE", "varName" : "WORK-1", "value" : "123.46" } }, { "name" : "2TOWORK-2", "typeName" : "METHOD", "type" : { "typeName" : "ADD", "value" : "2", "var1" : "WORK-2", "var2" : null } }, { "name" : "3GIVINGWORK-3", "typeName" : "METHOD", "type" : { "typeName" : "MULTI", "value" : "3", "var1" : "WORK-2", "var2" : "WORK-3" } }, { "name" : "C-PARA", "typeName" : "METHOD", "type" : { "name" : "C-PARA", "typeName" : "CALL" } } ] }, { "name" : "B-PARA", "typeName" : "FUNCTION", "methods" : [ { "name" : "PITOCONST-PI", "typeName" : "METHOD", "type" : { "name" : null, "typeName" : "MOVE", "varName" : "CONST-PI", "value" : "PI" } }, { "name" : "ZEROTOEDT-ID", "typeName" : "METHOD", "type" : { "name" : null, "typeName" : "MOVE", "varName" : "EDT-ID", "value" : "ZERO" } } ] }, { "name" : "C-PARA", "typeName" : "FUNCTION", "methods" : [ { "name" : "B-PARA", "typeName" : "METHOD", "type" : { "name" : "B-PARA", "typeName" : "CALL" } } ] } ]} |
DB2 Example
Now for a step in persistence, we translate simple DB2 programs to demo Java code that uses DB2 Express.
Here is the the example DB2 Cobol application:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | * --------------------------------------------------------------* Selects a single employee into a record's detail fields, and* then displays them by displaying the record.** Demonstrates Cobol-to-Java translation of a DB2 SELECT INTO* the detail fields of a parent record.** Java has no native notion of a record aggregate. A SQL* SELECT INTO similarly lacks a record construct.** Lou Mauget, January 31, 2017* -------------------------------------------------------------- IDENTIFICATION DIVISION. PROGRAM-ID. COBOLDB2. DATA DIVISION. WORKING-STORAGE SECTION. EXEC SQL INCLUDE SQLCA END-EXEC. EXEC SQL INCLUDE EMPLOYEE END-EXEC. EXEC SQL BEGIN DECLARE SECTION END-EXEC. 01 WS-EMPLOYEE-RECORD. 05 WS-EMPNO PIC XXXXXX. 05 WS-LAST-NAME PIC XXXXXXXXXXXXXXX. 05 WS-FIRST-NAME PIC XXXXXXXXXXXX. EXEC SQL END DECLARE SECTION END-EXEC. PROCEDURE DIVISION. EXEC SQL SELECT EMPNO, LASTNAME, FIRSTNME INTO :WS-EMPNO, :WS-LAST-NAME, :WS-FIRST-NAME FROM EMPLOYEE WHERE EMPNO=200310 END-EXEC. IF SQLCODE = 0 DISPLAY WS-EMPLOYEE-RECORD ELSE DISPLAY 'Error' END-IF. STOP RUN. |
This has been converted to a JSON syntax tree using our Antlr parser. The syntax tree JSON is transformed into the following Java application using the khs.transformer.CommandLine.java object.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | /** * Java source, file COBOLDB2.java generated from Cobol source, COBOLDB2.cbl * * @version 0.0.3 * @author Keyhole Software LLC */public class COBOLDB2 { private static Logger Log = LoggerFactory.getLogger("COBOLDB2"); // SQLCA private int sqlcode; // Level 05 private String v_ws_empno; // Level 05 private String v_ws_last_name; // Level 05 private String v_ws_first_name; // Level 01 private InItem[] v_ws_employee_record = new InItem[]{ () -> v_ws_empno, () -> v_ws_last_name, () -> v_ws_first_name }; // Procedure division entry: public static void main(String[] args) { try { COBOLDB2 instance = new COBOLDB2(); instance.m_procdiv(); } catch (Exception e) { e.printStackTrace(); } } private void m_procdiv () throws Exception { final String sql = "SELECT EMPNO, LASTNAME, FIRSTNME FROM EMPLOYEE WHERE EMPNO=200310"; final OutItem[] into = new OutItem[]{ s -> v_ws_empno = (String)s, s -> v_ws_last_name = (String)s, s -> v_ws_first_name = (String)s }; sqlcode = Database.getInstance().selectInto( sql, into ); if ( sqlcode == 0 ) { Display.display( v_ws_employee_record ); } else { Display.display( "Error" ); } // EXIT ... System.exit(0); }} |
The following steps describe how DB2 is set up in order to execute this application. The DB2 Express runs in a Docker container. There are no pooled connections. This is just a demo. ☺
Docker DB2 Express Container
Ensure you have access to Docker.
Use this Docker image for initial DB2 binding: https://hub.docker.com/r/ibmcom/db2express-c/
1 2 | docker run --name db2 -d -it -p 50000:50000 -e DB2INST1_PASSWORD=db2inst1-pwd -e LICENSE=accept -v $(pwd)/dbstore:/dbstore ibmcom/db2express-c:latest db2startdocker exec -it db2 bash |
Create running Docker DB2 Express container daemon, and log into a bash session as shown above.
Issue su db2inst1
Issue db2sampl (takes a while to create database “SAMPLE”).
1 2 3 4 5 6 7 8 | [db2inst1@6f44040637fc /]$ db2sampl Creating database "SAMPLE"... Connecting to database "SAMPLE"... Creating tables and data in schema "DB2INST1"... Creating tables with XML columns and XML data in schema "DB2INST1"... 'db2sampl' processing complete. |
At completion smoke-test the installation:
Run as Java: khs.transformer.CheckDb2Connection
The following displays on the console:
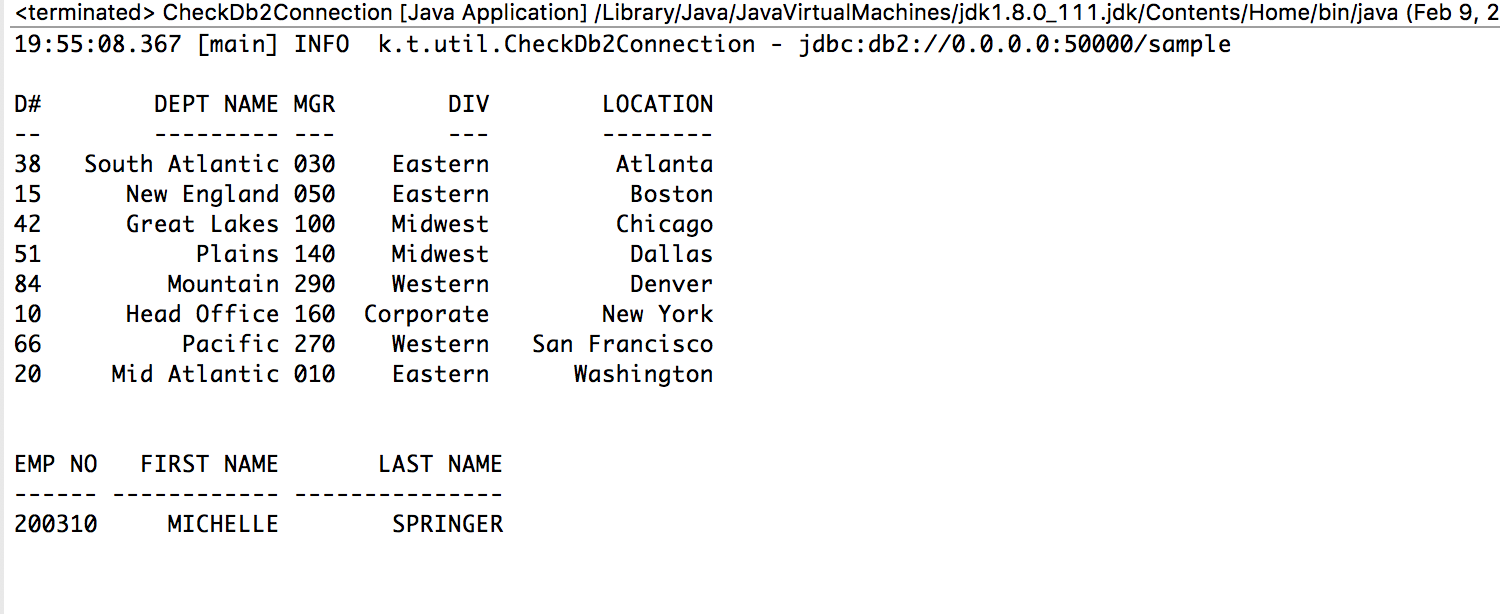
Once we have the DB installed and validated on the Docker container, we can execute our converted Cobol/DB2 to Java program – khs.res.db2demo.COBOLDB2.java. Once we execute that program we get the following output:
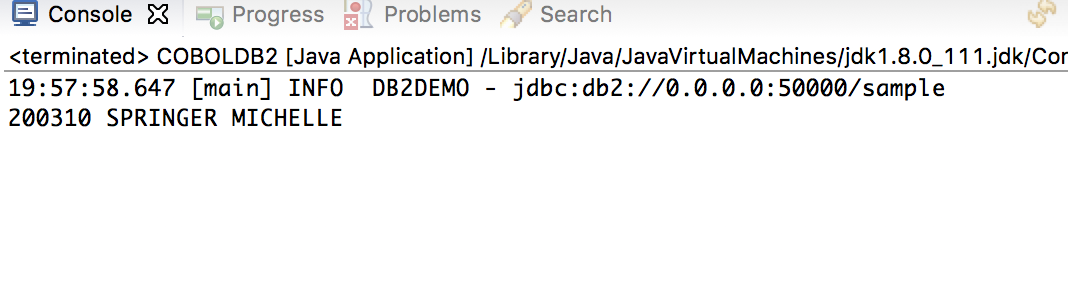
Basically Magic!
Again this is contrived, but we took a COBOL program that was converted into a JSON syntax tree, then ended up with a Java app that returned us data from the DB2 database – exactly what the COBOL program did!
In Conclusion
Hopefully, after this article and the above example we all have a better understanding of the Re-Platforming strategy. Whether or not this strategy is right for your organization is another conversation (one which we would love to have by the way – contact us).
The main point that I wanted to impress is that code transpiling is not a silver bullet for your legacy code werewolf, even if it sounds cool! I also wanted to inform you that, while fraught with peril, if approached correctly and with a robust tool (ahem – Keyhole Syntax Tree Transformer and Parse), it can be a very viable strategy.
“So, what have we accomplished here?”
In summary, we covered the following:
- A brief introduction to modernization
- Review of the Re-Platforming strategy for modernization
- A Re-Platforming example using the Keyhole Syntax Tree Transformer
- Additional closing thoughts on the value/risk of this strategy
We sure hope that you have enjoyed this as much as we have. Please, if you have questions or feedback please post them below or contact us directly.
Thank you, and remember to modernize responsibly!
Resources/References: This demo can be found here as well: https://github.com/in-the-keyhole/khs-syntax-tree-transformer
| Reference: | Adventures In Modernization: Strategy + Example Converting COBOL To Java from our JCG partner Dallas Monson at the Keyhole Software blog. |
