Most performance issues can be solved in several different ways. Many of the solutions applicable are well-understood and familiar to most of you. Some solutions, like taking certain data structures off from the JVM-managed heap, are more complex. So if you are not familiar with the concept, I can recommend to proceed to learn how we recently reduced both the latency of our applications along with cutting our Amazon AWS bill in half.
I will start by explaining the context in which the solution was needed. As you might know Plumbr keeps an eye on each user interaction. This is done using Agents deployed next to application nodes processing the interactions.
While doing so, Plumbr Agents are capturing different events from such nodes. All the events are sent to central Server and are composed into what we call transactions. Transactions enclose multiple attributes, including:
- start and end timestamp of the transaction;
- identity of the user performing the transaction;
- the operation performed (add item to shopping cart, create new invoice, etc);
- the application where the operation belongs to;
In the context of particular issue we faced, it is important to outline that only a reference to the actual value is stored as an attribute of a transaction. For example, instead of storing the actual identity of the user (be it an email, username or social security number), a reference to such identity is stored next to the transaction itself. So transactions themselves might look like the following:
| ID | Start | End | Application | Operation | User |
|---|---|---|---|---|---|
| #1 | 12:03:40 | 12:05:25 | #11 | #222 | #3333 |
| #2 | 12:04:10 | 12:06:00 | #11 | #223 | #3334 |
These references are mapped with corresponding human-readable values. In such a way key-value mappings per attribute are maintained, so that the users with ID’s #3333 and #3334 could be resolved as John Smith and Jane Doe correspondingly.
These mappings are used during runtime, when queries accessing the transactions will replace the references with the human-readable reference data:
| ID | Start | End | Application | Operation | User |
|---|---|---|---|---|---|
| #1 | 12:03:40 | 12:05:25 | www.example.com | /login | John Smith |
| #2 | 12:04:10 | 12:06:00 | www.example.com | /buy | Jane Doe |
The Naive Solution
I bet anyone from our readers can come up with a simple solution to such a requirement with your eyes closed. Pick a java.util.Map implementation of your liking, load the key-value pairs to the Map and lookup the referenced values during the time of the query.
What felt easy turned out to be trivial when we discovered that our infrastructure of choice (Druid storage with lookup data residing in Kafka topics) already supported such Maps out-of-the box via Kafka lookups.
The Problem
The naive approach served us fine for some time. After a while, as the lookup maps increased in size, queries requiring the lookup values started to take more and more time.
We noticed this while eating our own dogfood and using Plumbr to monitor Plumbr itself. We started to see GC pauses becoming both more frequent and longer on the Druid Historical nodes servicing the queries and resolving the lookups.
Apparently some of the most problematic queries had to lookup more than a 100,000 different values from the map. While doing so, the queries got interrupted by GC kicking in and exceeding the duration of the formerly sub 100ms query to 10+ seconds.
While digging in for the root cause, we had Plumbr exposing heap snapshots from such problematic nodes, confirming that around 70% of the used heap after the long GC pauses was consumed by exactly the lookup map.
It also became obvious that the problem had another dimension to consider. Our storage layer builds upon a cluster of nodes, where each machine in the cluster servicing the queries runs multiple JVM processes with each process requiring the same reference data.

Now, considering that the JVMs in question ran with 16G heap and effectively duplicated the entire lookup map, it was also becoming an issue in capacity planning. The instance sizes required to support larger and larger heaps started to take the toll in our EC2 bill.
So we had to come up with a different solution, reducing both the burden to garbage collection and finding a way to keep the Amazon AWS costs at bay.
The Solution: Chronicle Map
Solution that we implemented was built on top of Chronicle Map. Chronicle Map is off-heap in memory key-value store. As our tests demonstrated, the latency to the store was also excellent. But the main advantage why we chose Chronicle Map was it’s ability to share data across multiple processes. So instead of loading the lookup values to each JVM heap, we could only use one copy of the map accessed by different nodes in the cluster:
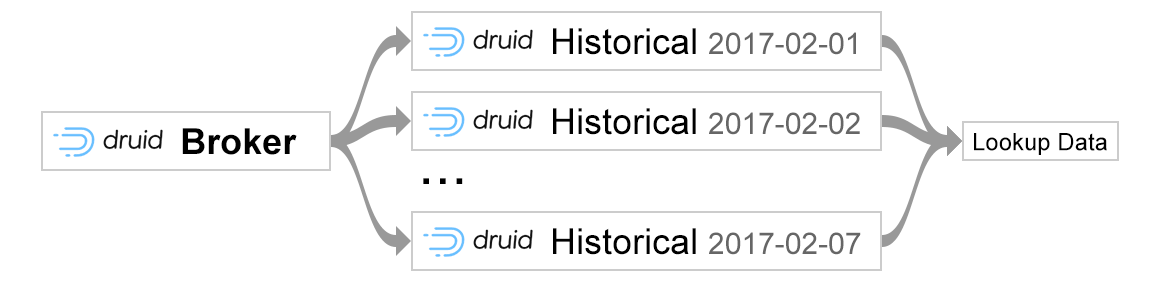
Before jumping into details, let me give you high level overview of Chronicle Map functionality that we found particularly useful. In Chronicle Map data can be persisted to the file system and then accessed by any concurrent process in a “view” mode.
So our goal was to create microservice that would have a role of a “writer”, meaning that it would persist all the necessary data in real time into the file system and role of the “reader” – which is our Druid data store. Since Druid doesn’t support Chronicle Map out of the box, we implemented our own Druid extension which is able to read already persisted Chronicle data files and replace identifiers with human-readable names during query time. Code below gives an example on how one may initialise Chronicle Map:
1 2 3 4 5 | ChronicleMap.of(String.class, String.class).averageValueSize(lookup.averageValueSize).averageKeySize(lookup.averageKeySize).entries(entrySize).createOrRecoverPersistedTo(chronicleDataFile); |
This configuration is required during initialisation phase to make sure Chronicle Map allocates virtual memory according to the limits you predict. Virtual memory pre allocation is not the only optimization made, if you are persisting data into the file system like we do, you will notice that Chronicle data files that are created are in fact sparse files. But this would be a story for a completely different post, so I will not dive into these.
In the configuration, you need to specify key and value types for the Chronicle Map you try to create. In our case all the reference data is in textual format, therefore we have type String specified for both the key and the value.
After specifying types of the key and value, there is more interesting part unique for the Chronicle Map initialization. As method names suggest both averageValueSize and averageKeySize requires a programmer to specify the average key and value size that is expected to be stored in the instance of Chronicle Map.
With method entries you give Chronicle Map the expected total number of data that can be stored in the instance. One may wonder what will happen if over time number records exceed predefined size? Apparently, if you go over the configured limit you might face performance degradation on the last-entered queries.
One more thing to consider when exceeding predefined entries size is that data can’t be recovered from the Chronicle Map files without updating the entries size. Since Chronicle Map during initialization precomputes required memory for the data files, naturally if the entries size remains the same and in reality file contains, let’s say 4x more entries, data won’t fit into the precomputed memory, therefore Chronicle Map initialization will fail. It’s important to keep this in mind if you want to gracefully survive the restarts. For example, in our scenario when restarting microservice that persists the data from Kafka topics, before initializing the instance of Chronicle Map, it dynamically computes the number entries based on amount of messages in the Kafka topic. This enables us to restart the microservice at any given time and recover already persisted Chronicle Map files with updated configuration.
Take-away
Different optimizations which enabled Chronicle Map instance to read and write data under microseconds started to have good effect immediately Already couple of days after releasing Chronicle Map based data querying we were able to see performance improvements:
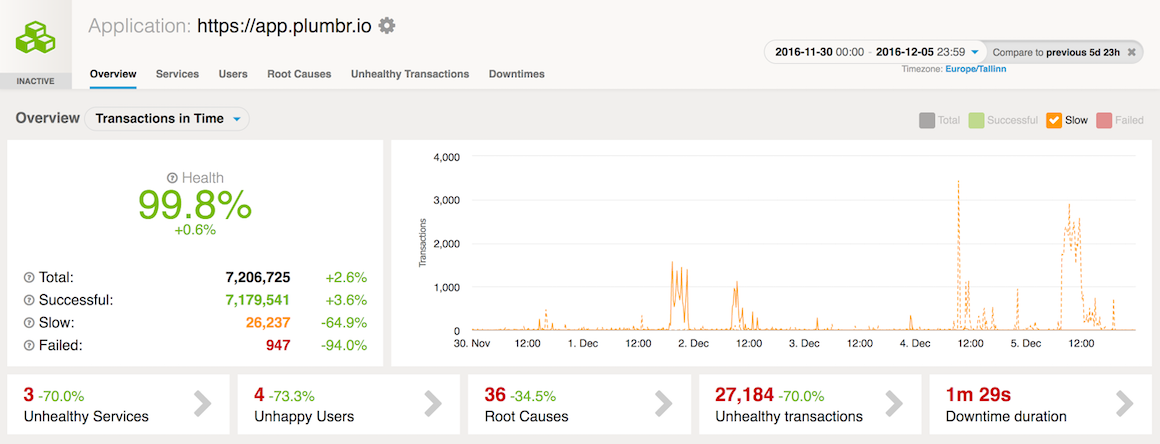
In addition, removing the redundant copies of the lookup map from each JVM heap allowed to cut our instance sizes for the storage nodes significantly, making a visible dent in our Amazon AWS bill.
| Reference: | Going off-heap to improve latency and reduce AWS bill from our JCG partner Levani Kokhreidze at the Plumbr Blog blog. |
