Once starting your play prototype application one of the priorities is to initialize your database and also manage the database schema changes.
Play provides us with evolutions. By utilizing evolutions we are able to create our database and to manage any futures changes to the schema.
To get started we need to add the jdbc dependency and the evolutions dependency.
1 2 | libraryDependencies += evolutionslibraryDependencies += jdbc |
Then we shall use a simple h2 database persisted on disk, as our play application default database.
We edit the conf/application.conf file and add the following lines.
1 2 | db.default.driver=org.h2.Driverdb.default.url="jdbc:h2:/tmp/defaultdatabase" |
Pay extra attention that our database location is at the tmp directory thus all change shall be deleted once we reboot our workstation.
Once we have configured our database we are ready to create our first sql statement.
Our scripts should be located at the conf/evolutions/{your database name} directory, thus in our case
/conf/evolutions/default.
Our first script ‘1.sql’, shall create the users table.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 | # Users schema# --- !UpsCREATE TABLE users ( id bigint(20) NOT NULL AUTO_INCREMENT, email varchar(255) NOT NULL, first_name varchar(255) NOT NULL, last_name varchar(255) NOT NULL, PRIMARY KEY (id), UNIQUE KEY (email));# --- !DownsDROP TABLE users; |
As we can see we got ups and downs. What do they stand for? As you have guessed ups describe the transformations while downs describe how to revert them.
So the next question would be, how this functionality comes in use?
Suppose you have two developers working on the 2.sql. Locally they have successfully migrated their database once they are done, however the merge result is far different than the file they executed on their database.
What evolutions do is detect if the file is different and reverts the old revision by applying downs and then applying the up to date revision.
Now we are all set to run our application.
1 | sbt run |
Once we navigate at localhost:9000 we shall be presented with a screen that forces us to run the evolutions detected.
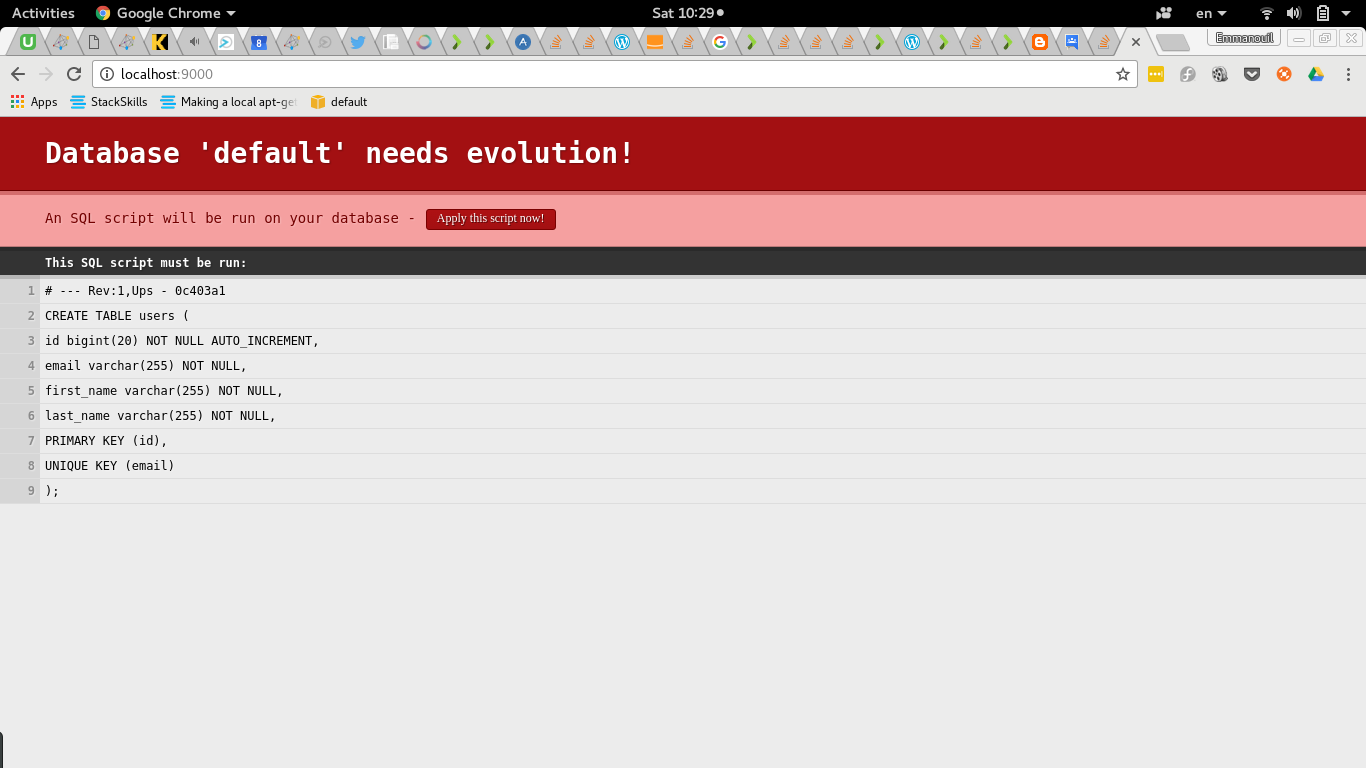
Let us go one step further and see what has been done to our database schema. We can easily explore a h2 database using dbeaver or your ide .
By issuing show tables the results contain one extra table.
1 2 3 4 5 | >SHOW TABLES;TABLE_NAME,TABLE_SCHEMAPLAY_EVOLUTIONS,PUBLICUSERS,PUBLIC |
The PLAY_EVOLUTIONS table keeps track of our changes
Id is the number of the evolution script that we created. The fields apply and revert are the ups and downs sql statements we created previously.
The field hash is used in order to detect changes to our file. In case of an evolution that has a different hash from the one applied the previous evolution is reverted and applies the new script.
For example let’s enhance our previous script and add one more field. The field username.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 | # Users schema# --- !UpsCREATE TABLE users ( id bigint(20) NOT NULL AUTO_INCREMENT, email varchar(255) NOT NULL, username varchar(255) NOT NULL, first_name varchar(255) NOT NULL, last_name varchar(255) NOT NULL, PRIMARY KEY (id), UNIQUE KEY (email));# --- !DownsDROP TABLE users; |
Once we start our application we will be presented with a screen that forces us to issue an evolution for our different revision. If we hit apply the users table shall contain the username field.
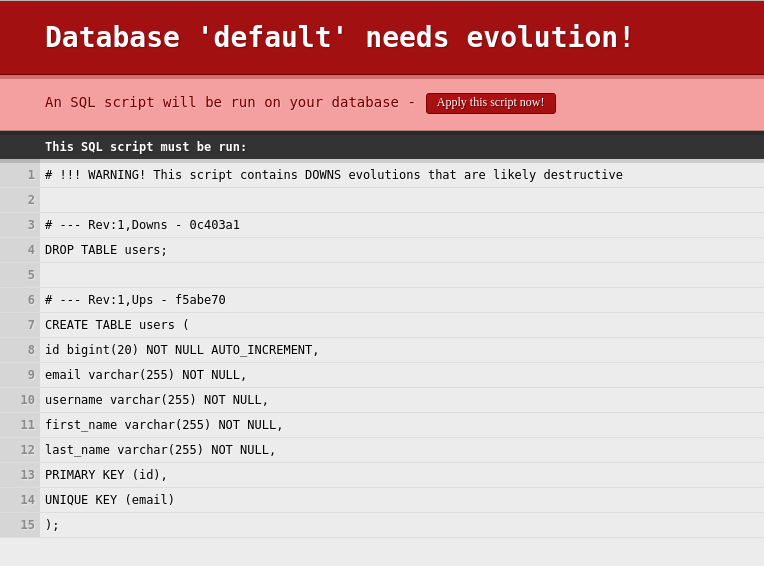
So the process of a new revision is pretty straight forward.
The hash from the new 1.sql file is extracted. Then a query checks if the 1.sql file has already been applied. If it has been applied a check is issued in case the hashes are the same. If they are not then the downs script from the current database entry is executed. Once finished the new script is applied.
| Reference: | Database Initialization with play and Scala from our JCG partner Emmanouil Gkatziouras at the gkatzioura blog. |
