Abstract
While researching how to create a high availability (HA), session replicated, multi-machined Payara/GlassFish cluster I discovered I couldn’t find everything I needed in a single reference. I assumed this would be a common need and easy to find. Unfortunately my assumption was wrong. So the purpose of this post is to give a complete end-to-end example of a high availability (HA), session replicated, multi-machined Payara clustering. But I also say (almost) because, as with any technology, I’m sure there are other ways to do this. The way described in this post is from my research.
Requirements
I did all of the work for this post using the following major technologies. You may be able to do the same thing with different technologies or versions, but no guarantees.
- Java SE 8 – OpenJDK 1.8.0_91
- Java EE 7 – Payara 4.1.1.163
- VirtualBox 5.1.6
- Lubuntu 16.04
- Nginx 1.10.0
- NetBeans 8.2
- Maven 3.0.5 (Bundled with NetBeans)
Definitions
Throughout this post, the following words will have these specific meanings. Nothing here that requires a lawyer, but it’s good to make sure the definitions are set.
Machine: The word machine refers to something which is running its own operating system. It can be either real hardware like a laptop, desktop, server, or raspberry pi. Or it can be a VM run on something like VirtualBox or VMWare. Or it can be something that looks like a machine such as a Docker container.
Cluster: A cluster is a collection of GlassFish Server instances that work together as one logical entity. A cluster provides a runtime environment for one or more Java Platform, Enterprise Edition (Java EE) applications (Administering GlassFish Server Clusters, n.d.)
Cluster Node: A cluster node represents a host on which the GlassFish Server software is installed. A node must exist for every host on which GlassFish Server instances reside (Administering GlassFish Server Nodes, n.d.)
Cluster Node Instance: A GlassFish Server instance is a single Virtual Machine for the Java platform (Java Virtual Machine or JVM machine) on a single node in which GlassFish Server is running. The JVM machine must be compatible with the Java Platform, Enterprise Edition (Java EE). (Administering GlassFish Server Instances, n.d.)
Architecture
Since this post describes a Payara cluster across multiple machines, it’s important to know what role each machine will play in the cluster. It’s not wise to start installing software across multiple machines without a plan. This section will give an overview of:
- The Architecture Diagram
- Machine Roles
- Machine Network Configuration
- Machine User Configuration
- Machine Software Installation
How the machines actually get up and running will not be covered in this post. This is a task left up to you. Some options are: real hardware (Raspberry Pi), virtual machines (Virtual Box), containers (Docker), or the cloud (AWS). If you already have machines up and running, configured, and ready to go, you can skip this section and jump directly to Cluster Creation.
Architecture Diagram
Figure 1 shows a simple architecture diagram for the simple example application being built for this post. But even though it’s simple, it’s important to have. It prevents randomly installing software on machines until you “get it right”. Also, an important word being used here is simple. This architecture contains the minimal pieces needed for this example; it is by no means comprehensive or production ready. So, with that in mind, the next thing to do is to look at the pieces of this architecture in more detail.
Figure 1 – “Zone S” Diagram
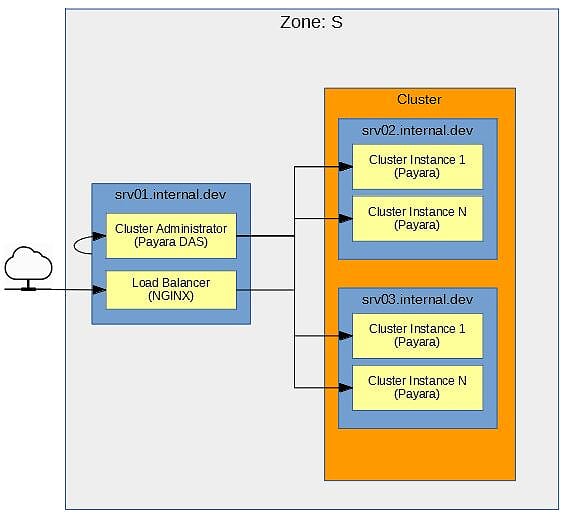
Zone: S All machines in a network should be assigned a zone. A zone groups together machines performing a similar function and also defines how machines between zones communicate with each other. This example shows Zone S. This zone will be for machines supporting application services.
srv[N].internal.dev The blue boxes represent machines in the zone. Each machine in the zone should have a clearly defined role, and, it’s best to not have a machine take on too many roles. The machines for this zone are named srv[N].internal.dev. The srv indicates the machine is a service machine part of Zone S. The [N] uniquely identifies the machine. Finally, the domain .internal.dev indicates this is a machine accessed internally within a development environment. The role of each machine is covered in the Machine Roles section.
Cluster The orange box represent a cluster within the zone. The cluster will be built with Payara. All machines participating in the cluster should be represented within the box.
Cluster Administrator, Cluster Instance, Load Balancer The yellow boxes represent what’s running on the machine. The role of the machine determines what runs on it. Next, you can look at the roles of the machines.
Machine Roles
So, what’s running on each machine in Zone S? Referring back to Figure 1, the machine roles are as follows:
srv01.internal.devThis machine has two roles. The first role is the Payara DAS for administering the cluster. The DAS is strictly dev-ops and internal-use only. It should not be accessible outside the zone. Also, as the DAS, no Java EE applications should be deployed to it. The second role is the NGINX load balancer. The load balancer is the entry point intoZone Swhen applications need to access the services deployed to the cluster in that zone.srv02.internal.devThis machine is a node in the Payara cluster. As shown, the node contains 2 instances.srv03.internal.devThis machine is a node in the Payara cluster. As shown, the node contains 2 instances.
Now that it’s clear the role of each machine, the next thing to look at is communication between the machines.
Machine Network Configuration
The names srv01, srv02 and srv03 will be the short hostnames of the machines. The contents of /etc/hostname on each machine will have this name. Here is the hostname for srv01:
$ cat /etc/hostname srv01
.internal.dev is the domain for these machines. The machines should be able to communicate with each other by either short hostname or by fully-qualified hostname.
NOTE This domain –
.internal.dev– will be critical later to properly configure the WAR for high-availability session replication across the cluster.
The easiest way to do this is through /etc/hosts. Configure /etc/hosts (on all the machines in the zone) to contain both short hostnames and fully-qualified hostnames.
$ cat /etc/hosts 127.0.0.1 localhost 10.0.2.16 srv01.internal.dev srv01 10.0.2.17 srv02.internal.dev srv02 10.0.2.18 srv03.internal.dev srv03
A simple ssh test should be used to verify communication between all the machines. Don’t skip this verification. Payara will use SSH for communication so it is best to verify and troubleshoot it now before Payara attempts to use it. I’ll leave the details for doing this test to you.
Now that all the machines can communicate to each other, the next thing to look at are Linux user accounts on the machines. Not too exciting, but very important.
Machine User Configuration
Each machine will need a payara user with a home directory at /home/payara. Thepayara user is used to run Payara. Nothing should be running as root. Simple enough.
Now that you got the basics of the machine configuration out of the way, it is time to start creating the Payara cluster.
Cluster Creation
Payara makes it easy to create a cluster. When using separate machines (verses typical examples which use the same machine for everything) there are a few additional steps. This section will give an overview of:
- Payara Installation
- Payara Domain Startup
- Payara DAS Security Configuration
- Payara Network Verification
- Cluster Creation
- Cluster Node Creation
- Cluster Node Instance Creation
- Cluster Startup
- Cluster Multicast Verification
This section is strictly focused on creating and configuring the cluster. This means that after reading this section you will have a cluster but it doesn’t mean your application is ready for high-availability and session replication. WAR Configuration will be discussed in the next section. It’s time to start building the cluster.
Payara Installation
Payara installation is nothing more than downloading the ZIP file and unzipping it. Of course go to Payara and find the download page. This post used Payara 4.1.1.163. It’s time to install Payara on all the machines in the zone.
- Download Payara 4.1.1.163
- Unzip Payara in
/home/payara. This will create/home/payara/payara41. - Create a symlink
$ln -s payara41 active - Put the Payara
bindirectories onto thepayaraLinux users’$PATH. Add the following line to/home/payara/.bashrc:
export PATH=/home/payara/active/bin:/home/payara/active/glassfish/bin:$PATH
Done! Simple enough. Next see if the Payara domain can start.
Payara Domain Startup
Use the asadmin tool to start the Payara domain. Execute the following command on srv01.internal.dev.
payara$ asadmin start-domain domain1
If all goes well, the domain will start. Verify it’s up and running by browsing to http://localhost:4848. Payara’s default configuration has no username/password protecting the DAS so you should get right in. Now that the DAS is running, the next thing to do is some security configuration.
Payara DAS Security Configuration
Now it’s time to configure some security that’s needed for communication between the machines in the cluster. All of these commands are executed on srv01.internal.dev.
NOTE All this configuration can also be done with the Payara GUI admin application http://localhost:4848 but that’s no fun! Command line is much for fun and hopefully allows automation.
The asadmin password Change the default Payara asadmin password. When executing this command for the first time, remember Payara has no default username/password so when prompted for the password, leave it blank. Execute the following command on srv01.internal.dev:
payara@srv01$ asadmin change-admin-password Enter admin user name [default: admin]>admin Enter the admin password> // Keep this blank when executing this for the first time Enter the new admin password> // Create a new password Enter the new admin password again> // Enter new password again
Restart the domain to make sure the changes are picked up. Execute the following command on srv01.internal.dev:
payara@srv01$ asadmin restart-domain domain1
Now verify the username/password by using asadmin to login to the DAS. The following command will login to the DAS and after login the asadmin command can be executed without requiring the username/password to be entered every time. This is a convenience, but of course a security risk. To login, execute the following command on srv01.internal.dev:
payara@srv01$ asadmin login Enter admin user name [Enter to accept default]> admin Enter admin password> ******* Login information relevant to admin user name [admin] for host [localhost] and admin port [4848] stored at [/home/payara/.gfclient/pass] successfully. Make sure that this file remains protected. Information stored in this file will be used by administration commands to manage associated domain. Command login executed successfully.
Secure admin Now you want to enable secure communication within the cluster. This basically means the Payara DAS will communicate with the cluster instances securely. This step isn’t necessary, but almost always a nice to have. Execute the following command on srv01.internal.dev:
payara@srv01$ asadmin enable-secure-admin
Restart the domain to make sure the changes are picked up. Execute the following command on srv01.internal.dev:
payara@srv01$ asadmin restart-domain domain1
That’s it for security configuration. The next thing to do is to validate communication from the machines in the Zone to the DAS before attempting to start creating the cluster.
Payara DAS Communication Verification
Try very hard not to skip this step. Most want to get right to cluster building and skip verification steps. This may save a little time, but, if something isn’t working properly it is easier to troubleshoot the problem in the verification step. So far, all work to start and configure the DAS has been on srv01. Now verify machines srv02 and srv03 are able to communicate with the DAS on srv01.
Execute the following on srv02.internal.dev and verify result as shown.
payara@srv02$ asadmin --host srv01 --port 4848 list-configs Enter admin user name> admin Enter admin password for user "admin"> server-config default-config Command list-configs executed successfully.
Execute the following on srv03.internal.dev and verify result as shown.
payara@srv03$ asadmin --host srv01 --port 4848 list-configs Enter admin user name> admin Enter admin password for user "admin"> server-config default-config Command list-configs executed successfully.
Successful execution on srv02 and srv03 will verify those machines can successfully communication with the DAS on srv01. Now that this has been verified, it’s time to create the cluster.
Cluster Creation
Now the cluster is going to be created. For this example, the cluster will be ingeniously named c1. In general, the cluster should be named appropriately, however, c1 will work well for this example. Execute the following on srv01.internal.dev.
payara@srv01$ asadmin create-cluster c1 Command create-cluster executed successfully.
That’s it! Pretty anti-climatic huh? The cluster is there, but nothing is in it. It is now time to fill the cluster with nodes. A cluster isn’t very useful without nodes.
Cluster Node Creation
The cluster nodes will be on machines srv02 and srv03. However, the commands to create the nodes are executed on srv01. The asadmin tool, when executed on srv01, will uses ssh to transfer the necessary files to srv02 and srv03. For convenience, first create a temporary password file to make SSH easier.
Temporary password file Recall that a payara Linux user was created on each of the machines. This is a normal Linux user which runs Payara to avoid running Payara as root. The temporary password file holds the unencrypted password of the payara Linux user on srv02 and srv03. It’s assumed the Linux password for the payara user is the same on all the machines. If this is not the case, then the temporary password file will need to be updated with the correct password for the payara user on machine srv[N] before an attempt is made to create a node on srv[N]
NOTE RSA/DSA key files can also be used. Refer to the
create-node-sshdocumentation for more info. http://docs.oracle.com/cd/E18930_01/html/821-2433/create-node-ssh-1.html#scrolltoc
Create cluster node on srv02 To create a node on srv02, execute the following command on srv01.internal.dev.
payara@srv01$ echo "AS_ADMIN_SSHPASSWORD=[clear_text_password_of_payara_usr_on_srv02]" > /home/payara/password payara@srv01$ asadmin create-node-ssh --nodehost **srv02.internal.dev** --sshuser payara --passwordfile /home/payara/password srv02-node
Create cluster node on srv03 To create a node on srv03, execute the following command on srv01.internal.dev.
payara@srv01$ echo "AS_ADMIN_SSHPASSWORD=[clear_text_password_of_payara_usr_on_srv03]" > /home/payara/password payara@srv01$ asadmin create-node-ssh --nodehost **srv03.internal.dev** --sshuser payara --passwordfile /home/payara/password srv03-node
Delete temporary password file After all the nodes are created, the temporary password file is no longer needed. It can be deleted at this point. Of course if more machines are added to the cluster and more nodes are needed, another temporary password file can be easily created.
Payara@srv01$ rm /home/payara/password
So now you got a cluster and nodes. Nodes are great. But nodes can’t do anything without instances. It’s the instances on the nodes that are able to run applications; it’s the actual Payara instance. So now it’s time to make some cluster node instances.
Cluster Node Instance Creation
Creating a node instance is basically creating Payara instances on the nodes. A node can have many instances on it. It all depends on the resources of the machine. The node instances will be created in the nodes on srv02 and srv03. However, the commands to create the node instances are executed on srv01. The asadmin tool, when executed on srv01, will create the node instances on srv02 and srv03.
Create node instances on srv02 Create 2 node instances on srv02. The node instances will be called srv02-instance-01 and srv02-instance-02. Execute the following command on srv01.internal.dev:
payara@srv01&$ asadmin create-instance --cluster c1 --node srv02-node srv02-instance-01 Command _create-instance-filesystem executed successfully. Port Assignments for server instance srv02-instance-01: ..... The instance, srv02-instance-01, was created on host srv02 Command create-instance executed successfully.
payara@srv01$ asadmin create-instance --cluster c1 --node srv02-node srv02-instance-02 Command _create-instance-filesystem executed successfully. Port Assignments for server instance srv02-instance-02: ..... The instance, srv02-instance-02, was created on host srv02 Command create-instance executed successfully.
If, after executing these commands, the message “Command create-instance executed successfully” is printed to the console then it is a pretty safe bet that everything worked OK. However, you should verify just to be sure. The verification process is done on srv02 and srv03. Successful verification means finding the /nodes directory. Execute the following on srv02.internal.dev.
payara@srv02$ cd /home/payara/active/glassfish payara@srv02$ ls bin common config domains legal lib modules nodes osgi
Create node instances on srv03 Create 2 node instances on srv03. Do everything exactly the same as in the previous heading but use srv03 instead of srv02.
There are now 4 Payara instances…
srv02-instance-01srv02-instance-02srv03-instance-01srv03-instance-02
spread across 2 nodes…
srv02-nodesrv03-node
on 2 different machines…
srv02srv03
on 1 logical Payara cluster
c1
Now, start everything up!
Cluster Startup
Starting the cluster c1 is really very easy. This is done from the srv01 machine and as the DAS starts all of the cluster instances, watch the console to make sure all 4 of them are started. Execute the following command on srv01.internal.dev.
payara@srv01$ asadmin start-cluster c1 0%: start-cluster: Executing start-instance on 4 instances. Command start-cluster executed successfully.
After the cluster is running, verify the cluster is running by listing the running clusters in the DAS. Also verify the node instances are running by listing the instances in the DAS Execute the following commands on srv01.internal.dev.
payara@srv01$ asadmin list-clusters c1 running Command list-clusters executed successfully.
payara@srv01$ asadmin list-instances srv02-instance-01 running srv02-instance-02 running srv03-instance-01 running srv03-instance-02 running Command list-instances executed successfully.
Congratulations! You now have a nice little 4 instance cluster. Now it’s time to deploy applications to it right? Wrong! Before deploying applications, it’s important to verify the multi-cast network communication between the nodes is working property to allow HttpSessions to be replicated across the cluster. Verify the multi-cast network communication next.
Cluster Multi-cast Verification
The whole point of having a cluster is to have a high-availability, session-replicated application. If one instance has a problem, another instance in the cluster (possibly on a different node) will take over seamlessly. But in order for this to actually happen, the cluster instances must be able to successfully communicate with each other. Payara has the validate-multicast tool to test this. However, the trick is in how to run validate-multicast. In order to run successfully, validate-multicast must be run on BOTH srv02 and srv03 AT THE SAME TIME! Execute the following on srv02.internal.dev AND srv03.internal.dev AT THE SAME TIME (Hafner, 2011)!
srv02.internal.dev Execute the following on srv02.internal.dev:
payara@srv02$ asadmin validate-multicast Will use port 2048 Will use address 228.9.3.1 Will use bind interface null Will use wait period 2,000 (in milliseconds) Listening for data... Sending message with content "srv02" every 2,000 milliseconds Received data from srv02 (loopback) Received data from srv03 Exiting after 20 seconds. To change this timeout, use the --timeout command line option. Command validate-multicast executed successfully.
srv03.internal.dev At the same time as srv02.internal.dev, also execute the following on srv03.internal.dev:
payara@srv03$ asadmin validate-multicast Will use port 2048 Will use address 228.9.3.1 Will use bind interface null Will use wait period 2,000 (in milliseconds) Listening for data... Sending message with content "srv03" every 2,000 milliseconds Received data from srv03 (loopback) Received data from srv02 Exiting after 20 seconds. To change this timeout, use the --timeout command line option. Command validate-multicast executed successfully.
When running both of these commands AT THE SAME TIME Communication between the instances should be successful. On the srv02 machine you should see “Received data from srv03” and on the srv03 machine you should see “Received data from srv02”. This validates that the multi-cast network communication used between the node instances for HttpSession replication is working properly.
Well that’s it! The cluster is now fully configured and up and running on multiple machines. I’m sure you are anxious to get your application deployed to the cluster. So dive in and see how to configure your WAR for a high-availability (HA), session-replicated environment.
WAR Configuration
Once a Payara cluster is configured and up and running, most think any application deployed to the cluster will take advantage of the cluster’s high availability (HA) and session replication. Unfortunately this is not the case. Your application must be developed and configured for a cluster. This section will give an overview of:
- HttpSession Serialization
- web.xml <distributable/>
- glassfish-web.xml cookieDomain
NOTE All of these configurations are needed. If just 1 is skipped, then session replication across the cluster will not work.
The first thing needed for you application is session serialization. This will be covered very briefly next.
Session Serialization
HttpSession serialization is a simple thing but something which most development teams pay very little attention to. Typically, application servers use serialization to replicate sessions across the cluster. If the objects in HttpSession are not able to be serialized, session replication will fail. So make sure ALL objects put into HttpSession are able to be serialized.
Session serialization is a critical configuration. If it is skipped, then session replication across the cluster will not work.
NOTE In a development environment, run your application with a
javax.servlet.Filterwhich attempts to serialize all objects inHttpSession. If you do adequate testing, this should catch any serialization problems.
Now that all the objects in HttpSession can be serialized, the next thing to look at is the web.xml configuration.
web.xml <distributable/>
Page 157 of the Servlet 3.1 specification defines the <distributable/> element for web.xml as “The <distributable/> indicates that this Web application is programmed appropriately to be deployed into a distributed servlet container.” This means <distributable/> must be added to web.xml so Payara knows the application will be running in a cluster and should be handled as such. Listing 1 shows an example.
Listing 1 – Distributable
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
version="3.1">
<display-name>clusterjsp</display-name>
<distributable/>
<servlet>
<display-name>HaJsp</display-name>
<servlet-name>HaJsp</servlet-name>
<jsp-file>/HaJsp.jsp</jsp-file>
</servlet>
<servlet>
<display-name>ClearSession</display-name>
<servlet-name>ClearSession</servlet-name>
<jsp-file>/ClearSession.jsp</jsp-file>
</servlet>
<session-config>
<session-timeout>30</session-timeout>
</session-config>
<welcome-file-list>
<welcome-file>HaJsp.jsp</welcome-file>
</welcome-file-list>
</web-app>The <distributable/> element is a critical configuration. If it is missing, then session replication across the cluster will not work.
The <distributable/> element is a configuration that’s needed for all Java EE servers. Payara has some of its own custom configuration as well. The next thing to look at is this server-specific configuration.
glassfish-web.xml cookieDomain
The glassfish-web.xml file is the Payara-specific configuration file for a web application. Unlike web.xml which is applicable to all Java EE servers, glassfish-web.xml only works for GlassFish or Payara EE servers. This means if you are deploying to a different EE server, you may or may not need to find the equivalent configuration for that server.
For Payara, glassfish-web.xml must be updated to add the cookieDomain property. Listing 2 shows the hierarchy of tags to properly set the cookieDomain value. As you can see in listing 2, the value is set to .internal.dev (Hafner, 2011). If you recall, this is the the domain you are using for the cluster architecture.
Listing 2 – cookieDomain
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE glassfish-web-app PUBLIC "-//GlassFish.org//DTD GlassFish Application Server 3.1 Servlet 3.0//EN" "http://glassfish.org/dtds/glassfish-web-app_3_0-1.dtd">
<glassfish-web-app error-url="">
<session-config>
**<cookie-properties>
<property name="cookieDomain" value=".internal.dev"/>
</cookie-properties>**
</session-config>
</glassfish-web-app>This cookieDomain property configuration is important because it allows the JSESSIONID cookie – which is what’s used to track a user’s session across the cluster node instances – to be passed to any cluster node instance on each web browser request. The easiest way see what’s happening here is to explain what happens if the cookieDomain property configuration is missing.
NOTE This is a little sneak preview of what’s to come, but that’s OK.
Suppose the cookieDomain property configuration is missing. A web browser then makes a request to the application running on one of the cluster node instances with the url http://srv02.internal.dev:28080/ferris-clusterjsp. When the application processes the request, it will create a JSESSIONID cookie and the domain value of that cookie will be (by default) the hostname used to access the application which in this case is srv02.internal.dev. Now another request is made to url http://srv03.internal.dev:28080/ferris-clusterjsp. It’s an instance of the cluster so you would expect that instance to find the session that’s already been created. But this won’t happen. It won’t happen because the JSESSIONID cookie was create with the domain value **srv02**.internal.dev so the web browser will not send this cookie on a request to http://**srv03**.internal.dev because the cookie belongs to srv02 and not srv03.
Now suppose the cookieDomain property configuration is configured as in Listing 2. What happens now? Well, a web browser makes a request to the application running on one of the cluster node instances with the url http://srv02.internal.dev:28080/ferris-clusterjsp. This time, however, when the application processes the request, it will create a JSESSIONID cookie and the domain value of that cookie will be the domain you configured it to be in Listing 2 which is .internal.dev. Now another request is made to url http://srv03.internal.dev:28080/ferris-clusterjsp. The web browser will send the JSESSIONID along with this request because the cookie belongs to .internal.dev and the request is going to http://srv03**.internal.dev**.
The cookieDomain property is a critical configuration. If it is missing, or if the domain you are using does not match the cookieDomain value, then session replication across the cluster will not work.
Congratulations. Your web application is configured and ready for deployment to the cluster. Deployment is easy to do, and you’ll do that next.
WAR Deployment
At this point, you’re finally ready to deploy your WAR. Well, not quite. Do you have a WAR? No? Well you’re in luck. The clusterjsp application is popular for testing clusters and session replication. I have my own fork of clusterjsp on my GitHub account which is already configured and ready to deploy to this example cluster. You can download my fork of clusterjsp at https://github.com/mjremijan/ferris-clusterjsp/releases. In this section, you will look at:
- The Payara
asadmin deploycommand - Verifying application deployed correctly across the cluster.
Deploy Command
First you have to download ferris-clusterjsp-1.1.0.0.war from my GitHub account. Next, deployed it to the cluster using the asadmin command. Execute the following on srv01.internal.dev:
$ asadmin deploy --force true --precompilejsp=true --enabled=true --availabilityenabled=true --asyncreplication=true --target c1 --contextroot=ferris-clusterjsp --name=ferris-clusterjsp:1.1.0.0 ferris-clusterjsp-1.1.0.0.war Application deployed with name ferris-clusterjsp:1.1.0.0. Command deploy executed successfully.
–force true Forces the webapp to be redeployed even if it has already been deployed.
–precompilejsp=true The ferris-clusterjsp application uses some simple JSP files, so have them precompiled at deployment.
–enabled=true Allows access to the application after it is deployed.
–availabilityenabled=true Allows for high-availability through session replication and passivation. The applies to stateful session beans as well, though those are typically not used much anymore.
–asyncreplication=true Perform session replication across the cluster in a separate asynchronous thread vs. the thread handling the user’s request.
–target c1 Deploy the application to cluster c1
–contextroot=ferris-clusterjsp Set the context root of the application to ferris-clusterjsp. This can also be defined in glassfish-web.xml.
–name=ferris-clusterjsp:1.1.0.0 Set the display name of the application as it appears in the Payara admin console. Typically it’s a good idea to include the version number in display name.
ferris-clusterjsp–1.1.0.0.war The name of the WAR file to deploy.
Now that the WAR is deployed, the next thing to do is to verify the application was successfully deployed and is running on all the cluster node instances.
Deploy Verification
When you execute the asadmin deploy command above, after a short amount of time you should see the “Command deploy executed successfully” message. If so, that’s good! The application was successfully deployed to the cluster. To verify it was successfully deployed, execute the following on srv01.internal.dev:
$ asadmin list-applications --long true --type web c1 NAME TYPE STATUS ferris-clusterjsp:1.1.0.0 <web> enabled Command list-applications executed successfully.
This asadmin command asks Payara to list all applications of type web on cluster c1. There should be 1 result, the ferris-clusterjsp:1.1.0.0 application and its status should be enabled. And just to be sure everything is up and running, look at the status of the node instances by executing the following on srv01.internal.dev.
$ asadmin list-instances c1 srv02-instance-01 running srv02-instance-02 running srv03-instance-01 running srv03-instance-02 running
This asadmin command tells you there are 4 instances in the c1 cluster and all 4 instances are running. The ferris-clusterjsp application is successfully running on the cluster. Next thing to do is to test it!
WAR Session Replication Testing
It is now time to see if session replication across the cluster is working. Doing so is not difficult, however, you will need to leave the command-line world and now start working with a browser. To test session replication is working properly, you will need to:
- Determine the link URLs to each individual cluster node instance running the application.
- Use a web browser to visit each link.
Links To Each Instance
The first thing you will need to do is find the URLs to access the ferris-clusterjsp application on each cluster node instance. Here is how you do it. The ferris-clusterjsp application is running on 4 cluster node instances, and each instance has its own URL. Get the list of links by following these steps:
- Open a web browser on
srv01.internal.dev. - Browse to the the Payara admin console at
http://localhost:4848. - Login (remember, you changed the admin password in Payara DAS Security Configuration).
- Click on the Applications tree node.
After clicking on the Applications tree node, you will see the ferris-clusterjsp:1.1.0.0 application listed. Figure 2 shows that in the Action column of the table is a hyperlink named Launch. Click it!
Figure 2 – The Launch link
Launch link
After clicking the Launch link, a new browser window will appear with all the links to the application across the cluster. Figure 3 shows 8 links. Each of the 4 cluster node instances are accessible by either HTTP or HTTPS.
Figure 3 – All the Links
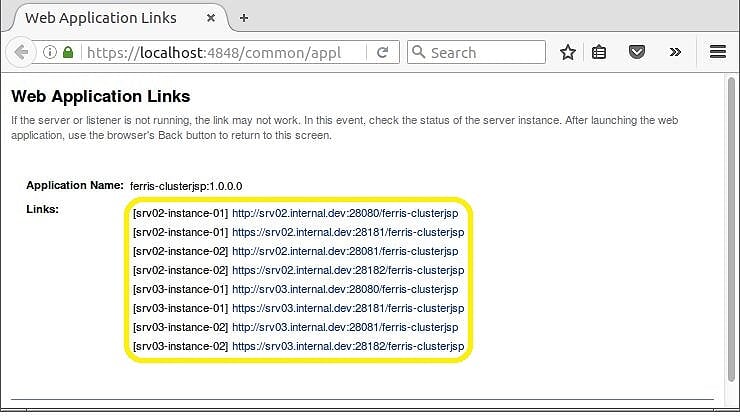
Now that you know all the links, you can directly access the ferris-clusterjsp application on each of the 4 instances. This will allow you to test if session replication is working. If your first request is to instance srv02-instance–01, you will be able to see your session on any of the other 3 instances. Hopefully it will work!
Testing Replication
To test if session replication is working, all you need to do is access the application on one of the cluster node instances, take note of the session ID value, then access the application on a different node instance and see if your session replicated. Start first with srv02-instance–01. Open a web browser and browse to http://srv02.internal.dev:28080/ferris-clusterjsp. The application will show information about the cluster node instance and about the your session. Your browser will look similar to Figure 4a.
Figure 4a – ferris-custerjsp on srv02-instance–01
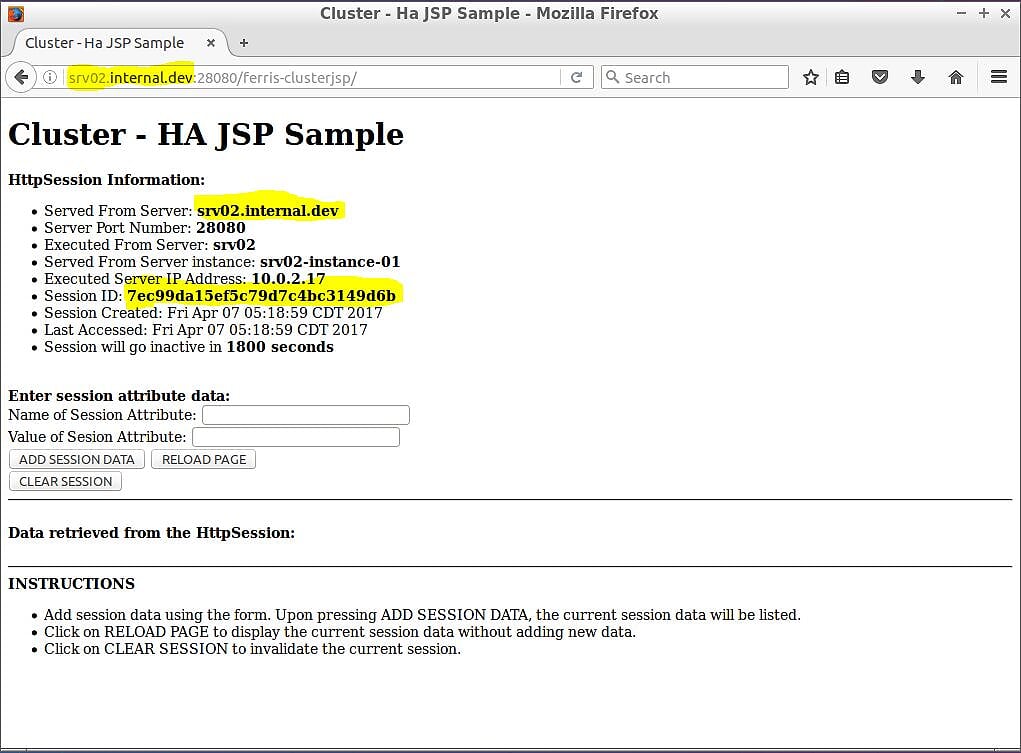
Figure 4a highlights a few pieces of information you will need to confirm session replication is working. First, the web browser URL is http://srv02.internal.dev:28080/ferris-clusterjsp and the host name of the URL matches the Served From Server information on the page. Also, the page shows you the session ID created for you – in this case 7ec99da15ef5c79d7c4bc3149d6b.
You now have a session on the application, and, if everything is working, that session should be replicated across the entire cluster. The only thing left to do to test this is to pick another cluster node instance and see if you get the same session. Pick srv03-instance–02 to test next. This cluster node instance is not only on a completely different physical machine, but it also switches protocol from HTTP to HTTPS. Open a web browser and browse to https://srv03.internal.dev:28182/ferris-clusterjsp. Figure 4b shows what should happen.
Figure 4b – ferris-custerjsp on srv03-instance–02
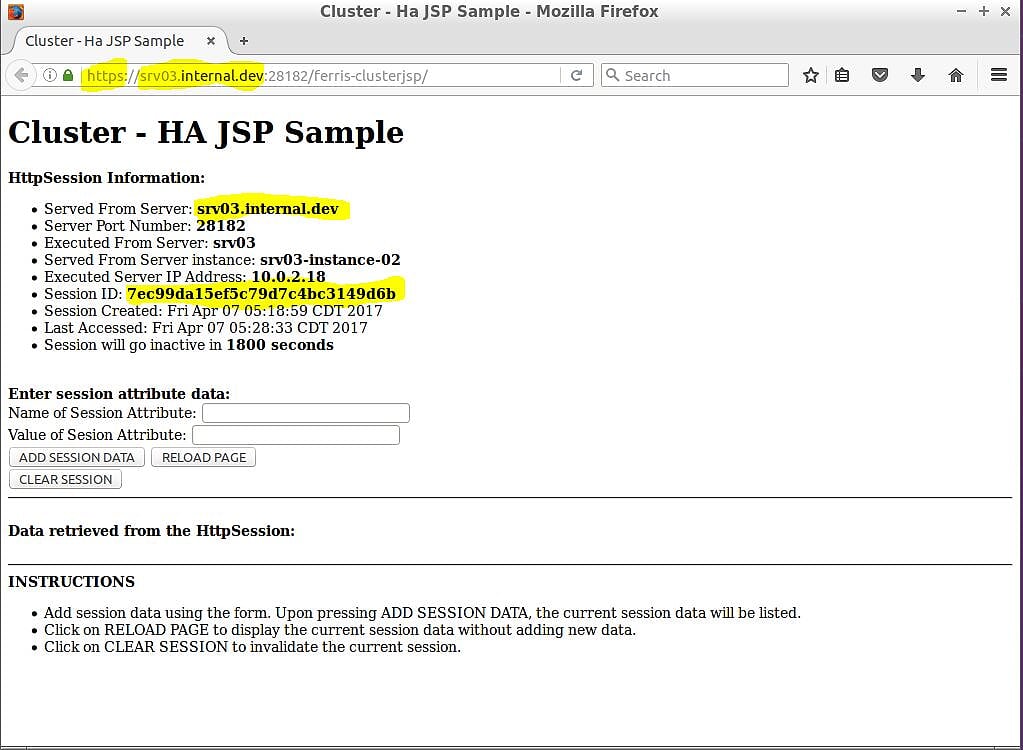
Figure 4b shows the results, and they look really good! Highlighted you can see the switch from HTTP to HTTPS (your web browser should have also forced you to accept the certificate). The web browser URL is https://srv03.internal.dev:28182/ferris-clusterjsp and the host name of the URL matches the Served From Server information on the page. But most importantly, you get the same session ID – in this case 7ec99da15ef5c79d7c4bc3149d6b.
Now you can have a little fun and test replication a bit more. Use the page to add some session attribute data and see if it replicates across the cluster. It doesn’t matter which cluster node instance you use use first. Pick one. Then go to the Enter session attribute data: section of the page and add session data as shown in Figure 5.
Figure 5 – Add session attribute data
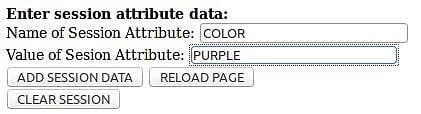
Click the ADD SESSION DATA button. Figure 6 shows the page will refresh and the session attribute data has been added.
Figure 6 – Session attribute data added

After the session attribute data has been added, go to your other browser and refresh the page. You’ll see the data has been replicated. Figure 7 shows web browsers side-by-side with identical replicated session attribute data.
Figure 7 – Browsers side-by-side with same data

Congratulations! You now have a fully functioning, multi-VM, session replicated cluster. But there is something still missing: High Availability (HA). For HA, you’ll need a load balancer. So the next thing to look at is load balancer configuration.
Load Balancer Configuration
Right now you have a great multi-vm, session replicated cluster, but it’s kind of useless because it’s not accessible yet. You have the links to access each individual cluster node instances, but, having the URL for 1 instance doesn’t give you High Availability (HA). What you need now is a load balancer – something that can take a request to a generic URL like http://srv.internal.dev and proxy that request to any of the active instances in the cluster. And, thanks to successfully setting up session replication across the cluster, it doesn’t matter which instance the load balancer proxies your request to because your session data will be the same across the cluster. For this post, you are going to use NGINX as the the load balancer. This section will look at:
- NGINX Installation
- NGINX Configuration
- NGINX Testing
NGINX Installation
Installing NGINX is simple. You should be able to use apt-get to do this. Execute the following command on srv01.internal.dev. Remember in the architecture diagram for the zone, srv01.internal.dev is the machine in the zone which will run the load balancer.
$ apt-get install nginx
That’s it. NGINX is now installed. To get it working with your cluster node instances you will need to do a little configuration, which is what you will do next.
NGINX Configuration
This NGINX configuration is very simple. There are 2 things you need to do. The first is you need to setup an upstream configuration that contains the host names and port numbers of all the cluster node instances. The second is to update the location to proxy requests to the upstream.
upsteam First, look at the upstream configuration. Assuming you installed NGINX on srv01.internal.dev, open the /etc/nginx/nginx.conf file for editing. Edit the file and add an upstream configuration as shown in the following example. The upstream configuration goes inside of the http configuration.
http {
upstream cluster_c1 {
server srv02.internal.dev:28080;
server srv02.internal.dev:28081;
server srv03.internal.dev:28080;
server srv03.internal.dev:28081;
}
}Restart NGINX to pick up the changes.
$ /etc/init.d/nginx restart
location Next, look at the location configuration. Assuming you installed NGINX on srv01.internal.dev, open the /etc/nginx/sites-available/default file for editing. Edit the file and update the location configuration to MATCH the following example. The location configuration goes inside of the server configuration.
server {
listen 80;
server_name localhost;
upstream cluster_c1 {
location / {
root html;
index index.html index.htm;
proxy_connect_timeout 10;
proxy_send_timeout 15;
proxy_read_timeout 20;
proxy_pass http://cluster_c1;
}
}Restart NGINX to pick up the changes.
$ /etc/init.d/nginx restart
NGINX Testing
By default, NGINX is configured to listen on port 80. You saw this in the previous section when you did the location configuration. If both NGINX and the Payara are up and running, here’s the easiest way to test.
- Open a web browser on
srv01.internal.dev. - Browse to
http://localhost
Because NGINX is configured as a proxy in front of Payara, the browser will show the Payara-is-now-running page as in Figure 8.
Figure 8 – Payara with localhost proxied through NGINX
That’s it. NGINX is now configured and working. That means you have the High Availability (HA) piece of the architecture ready to test. You can do that next.
WAR High Availablity (HA) Testing
You’re in the home stretch now. Here are all the pieces of the architecture so far:
- A Payara cluster able to support session replication.
- An application coded and configured to take advantage of session replication.
- A Payara cluster running multiple node instances.
- An NGINX load balancer configured to proxy requests to the cluster node instances.
Now it’s time to see if all the pieces work together. For these final tests, you need to have a web browser capable of sending requests through the NGINX load balancer. Remember 2 very important things:
- The load balancer is running on
srv01.internal.devon port 80. - The URL you use must end with
.internal.dev.
The easiest way to do this is to edit your testing machine’s hosts file and add a host to test the cluster. Assume the test hostname will be srv.internal.dev. Then add the following to your testing machine’s hosts file:
$ cat /etc/hosts 127.0.0.1 localhost 10.0.2.16 srv01.internal.dev srv01 10.0.2.17 srv02.internal.dev srv02 10.0.2.18 srv03.internal.dev srv03 10.0.2.16 srv.internal.dev
The first test you should do is to repeat the simple NGINX test. Only this time use the hostname you just saved in the hosts file. Perform the test by doing the following:
- Open a web browser on the testing machine.
- Browse to
http://srv.internal.dev
Because NGINX is configured as a proxy in front of Payara, the browser will show the Payara-is-now-running page as in Figure 9. The difference this time is the URL uses the hostname saved in the hosts file.
Figure 9 – Payara with srv.internal.dev proxied through NGINX
Now here comes the final test to make sure everything is working. Open a web browse to the ferris-clusterjsp application and see what happens. Perform the test by doing the following:
- Open a web browser on the testing machine.
- Browse to
http://srv.internal.dev/ferris-clusterjsp.
If everything goes OK, you will see the HA JSP Sample page handled by one of the cluster node instances. Figure 10 shows that srv03-instance-01 handled the first request.
Figure 10 – Payara with ferris-clusterjsp proxied through NGINX
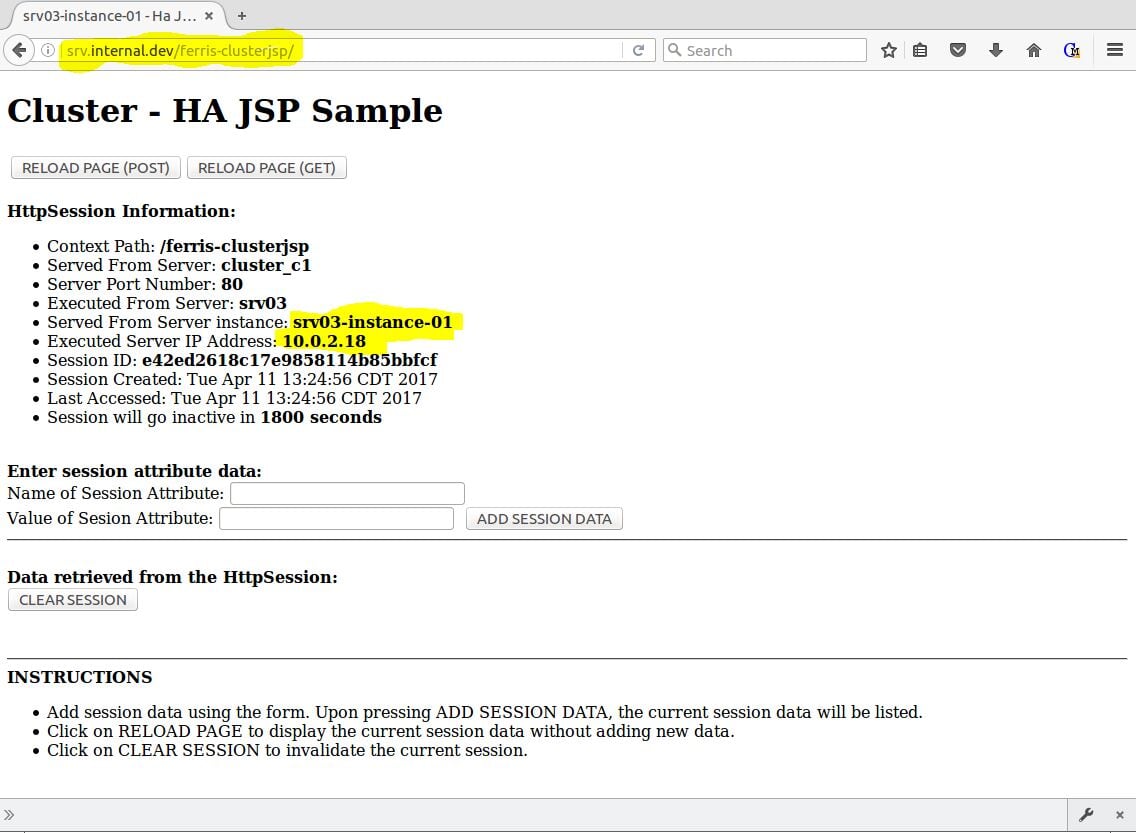
Now the exciting part. Keep testing! Keep reloading the page. As seen in Figure 11, you will see the Served From Server instance: and Executed Server IP Address: change as the NGINX load balancer proxies requests to different cluster node instances, but the Session ID will remain the same. Cool!
Figure 11 – Payara with ferris-clusterjsp proxied through NGINXFigure 11 – Payara with ferris-clusterjsp proxied through NGINX
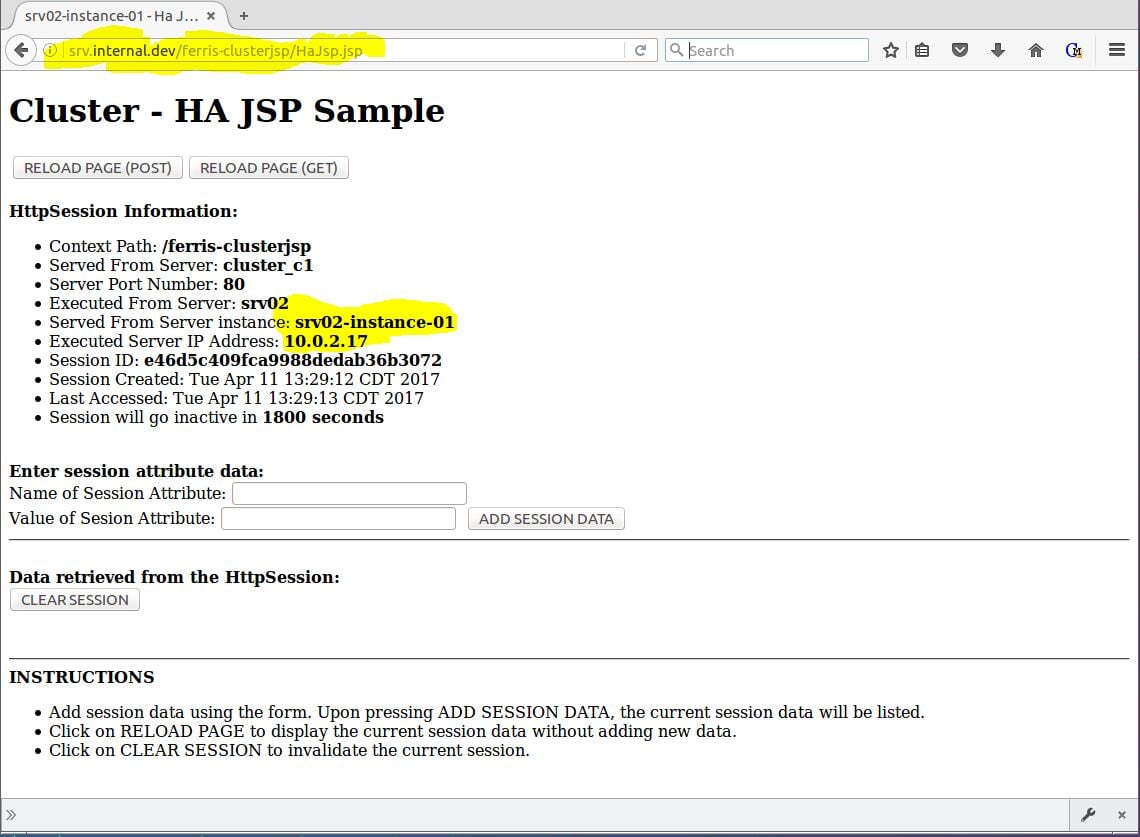
Now for an even more fun test. High Availability (HA) means if a cluster node instance goes down the application still keeps running and your users are not impacted. Try it! Shut down one of the cluster node instances and see what happens. Execute the following command on srv01.internal.dev:
bash $ asadmin stop-instance srv03-instance-01
This will stop the 1 instance of the cluster. Now go back to your browser and start reloading the page. While you are reloading, watch the Served From Server instance: value. Because srv03-instance-01 is now shut down, you’ll notice this instance will be skipped as the load balancer round-robins through the cluster instances. One instance of your cluster is stopped, but your application is still working fine. If you want to start the instance again, Execute the following command on srv01.internal.dev:
$ asadmin start-instance srv03-instance-01
This will restart the instance. Now go back to your browser and start reloading the page again. While you are reloading, watch the Served From Server instance: value. You’ll eventually notice srv03-instance-01 will come back! :)
Summary
My goal for this post was to consolidate in one place the instructions to create a high availability (HA), session replicated, multi-machined Payara/GlassFish cluster. Hopefully I accomplished that goal by giving instructions for the following:
- Creating a multi-machine architecture for a cluster
- Installing Payara
- Configuring the DAS for cluster communication
- Creating the cluster
- Creating the cluster nodes
- Creating the cluster node instances
- Configuring a WAR to use session-replication
- Configuring NGINX for load balancing & proxying.
- Testing everything at every step of the way to make sure it’s all working.
I hope you have found this post useful. And also please note the title of this post says “(almost)” for a good reason: this is not the only way to create a high availability (HA), session replicated, multi-machined Payara/GlassFish cluster. But it is A way.
References
Java Servlet 3.1 Specification (2013, May 28). Java Servlet 3.1 Specification for Evaluation [PDF]. Retrieved from http://download.oracle.com/otndocs/jcp/servlet-3_1-fr-eval-spec/index.html
Hafner, S. (2011, May 12). Glassfish 3.1 – Clustering Tutorial Part2 (sessions) [Web log post]. Retrieved from https://javadude.wordpress.com/2011/05/12/glassfish-3-1-%E2%80%93-clustering-tutorial-part2-sessions/.
Hafner, S. (2011, April 25). Glassfish 3.1 – Clustering Tutorial [Web log post]. Retrieved from https://javadude.wordpress.com/2011/04/25/glassfish-3-1-clustering-tutorial/
Mason, R. (2013, September 03). Load Balancing Apache Tomcat with Nginx [Web log post]. Retrieved from https://dzone.com/articles/load-balancing-apache-tomcat
Fasoli, U. (2013, August 17). Glassfish Cluster SSH – Tutorial : How to create and configure a glassfish cluster with SSH (Part 2) [Web log post]. Retrieved from http://ufasoli.blogspot.com/2013/08/
Fasoli, U. (2013, July 17). Glassfish asadmin without password [Web log post]. Retrieved from http://ufasoli.blogspot.fr/2013/07/glassfish-asadmin-without-password.html
Oracle GlassFish Server 3.1 Section 1: asadmin Utility Subcommands. (n.d.). Retrieved from https://docs.oracle.com/cd/E18930_01/html/821-2433/gentextid-110.html#scrolltoc
Camarero, R. M. (2012, January 21). clusterjsp.war [WAR]. Retrieved from http://blogs.nologin.es/rickyepoderi/uploads/SimplebutFullGlassfishHAUsingDebian/clusterjsp.war
Croft, M. (2016, June 30). Creating a Simple Cluster with Payara Server [Web log post]. Retrieved from http://blog.payara.fish/creating-a-simple-cluster-with-payara-server
Administering GlassFish Server Clusters. (n.d.) Retrieved from https://docs.oracle.com/cd/E26576_01/doc.312/e24934/clusters.htm#GSHAG00005
Administering GlassFish Server Nodes. (n.d.). Retrieved from https://docs.oracle.com/cd/E26576_01/doc.312/e24934/nodes.htm#GSHAG00004
Administering GlassFish Server Instances. (n.d.). Retrieved from https://docs.oracle.com/cd/E26576_01/doc.312/e24934/instances.htm#GSHAG00006
| Reference: | High Availability (HA), Session Replicated, Multi-VM Payara Cluster from our JCG partner Michael Remijan at the Michael Remijan blog. |

Thanks for the sharing but how to overcome when multi-cast is not available ? Any alternative ?
Greate guide, I wish I had found it before, right now i just need to apply only the last steps to complete it. However i will review all my configurations with your instructions, thanks for this compilation of information.
I have a question about cookie-properties tag. If the main domain will be srv01.internal.dev (or any other managed by nginx) then all cookies generated will use this unic domain right? if this is correct, then this tag is not used?
Yes, I believe that is the case. A proxy in front of the cluster is pretty much mandatory. So if all the requests go through an nginx proxy then from the browser point of view it never knows of any individual servers in the cluster and just the higher level domain.