In my previous Microservice Tutorial , I have shown How We can use Hystrix as a circuit Breaker and how to give our service a breathing room to recover itself.
In this tutorial, we will take a deep dive into Hystrix architecture and we will eventually get to know How it manages resiliency in a complex system.
Let assume there are more than 100 Microservices in a complex system and to perform any business functionality more or less it depends on 5-10 underlying Microservices(approximately).
Generally, there are three types of services found in aforesaid Microservice based architecture:
- Core Services
- Aggregator service
- Edge Service
Where the Edge service takes the request from UI/client, it forwards to an Aggregator service. Then the Aggregator service fans out the request and sends the calls to core-services and Eventually collects responses from Core services and sends back to the Edge Service, which actually sends the response to UI/Client.
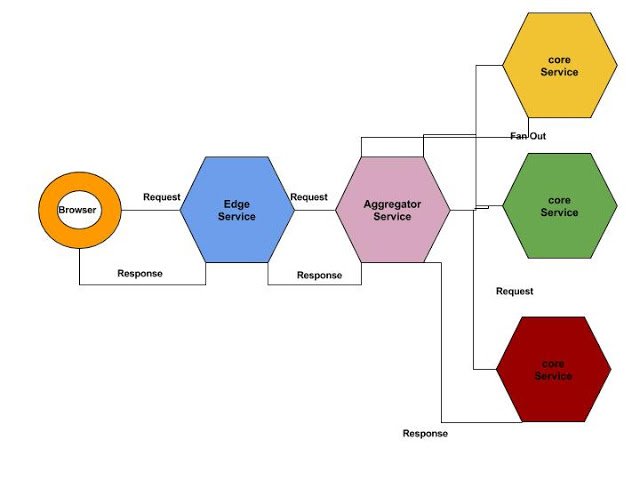
Imagine that we have a complex microservice based system where a single incoming request distribute over than 10 dependent services. One request splits to 10 internal requests (Fans out) and goes to individual core service. There are 100 concurrent requests per seconds in a peak time.
So, there are 100*10 = 10000 internal requests will be created per second. Think about the load of the system. Even a minute of delay response from one of the core services can create a bottleneck as in web server (Tomcat, Jetty) there are fixed numbers of Threads in the Thread pool.
60*100*1=6000 requests are waiting for an individual service for a minute. So, we can assume that failure is inevitable even if you have 99.99% of uptime for a service, because when we do a service call we have to depend on two external entities Network and Socket and the sad part is that the control of the Network is not in developers hand. To make the system resilience we have to deal with this phenomena and have to plan according to it.
Now let’s see the options we have to deal the above scenario.
Non Blocking request: If Requests are not waiting for the service irrespective of the service is available or not, only then all requests will be either served or rejected. If we follow this, then there will be no requests in the waiting queue as if the service is not available or does not response is getting delayed immediately, that request will be rejected and a fallback/default response will be provided to the caller service.
So request has been short-circuited and the fallback path invoked — dependent service gets a chance to recover itself. We know Hystrix do this stuff for us. But it is not an easy task to implement. Internally a complex flow has been maintained by Hystrix to offer Resilient Microservice Architecture.
We will discuss that workflow now.
Deep Dive to Hystrix Workflow
ThreadPool: Hystrix maintains a Thread pool so that when a service calls to another service –The call will be assigned to one of the thread from that Thread pool. Basically, to handle the concurrency It offers Worker Threads. Each Thread has a timeout limit. If the response is not returned within the Thread time out mentioned, then the request will be treated as a failure and fallback path will be invoked.
Network and Socket Timeout: When a Service call to another service, two things are happening: the data travels through Network and service talks each other via socket. When data travels through Network it has to cross multiple hops so if a hop is slow or down then we can feel network slowness. So we have to calculate an average time for a request/response travel time as well as Socket read/write time to calculate thread timeouts in an optimum way.
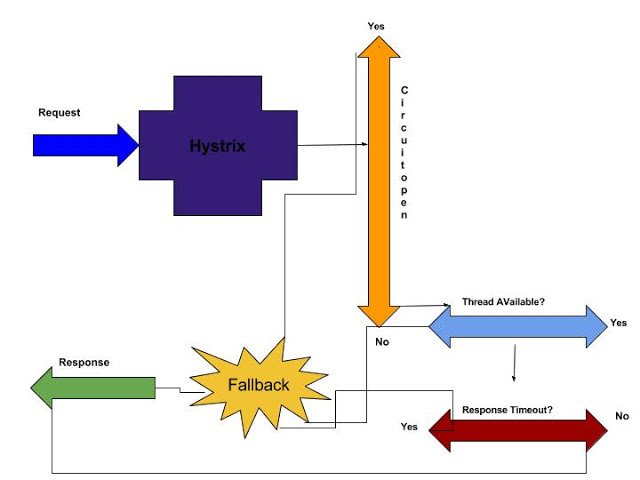
Hystrix Workflow:
- when a service calls a dependent service, Hystrix steps in and checks if Hystrix Circuit is open or not. If it is open then it returns to the fallback path.
- If Circuit is not open then, Hystrix checks if all the worker Threads in the pools are in use. If so, it returns immediately and the fallback path is invoked.
- If threads are available in pools, then it assigns one free thread and it waits for the response from the dependent service. If response time is greater than thread timeout then it again invokes fallback path.
- If all is well, then the actual response is back to the caller service.
- If, for a certain amount of time (default 10 sec), 50% of the request is failed then Hystrix opens the circuit.
It is very important to choose Thread pool and Thread time out wisely, unless necessary implications are coming into the picture. if Thread pool count is large, let’s say it is greater than the database connection thread pool, then in spite of the hystrix all the Connection are consumed by the service again. If the Thread pools count is less, then we can’t serve many requests concurrently because maybe that will cause a performance hit. So choose the Thread pool count based on your system configuration.
This is the same for Timeouts. If the timeout is big then there will be more incoming requests in the queue. But if Timeout is short then all calls are timeouts, even if your service is healthy, because the average response time of your service is greater than the Timeout.
Conclusion
Nowadays whatever the architecture (Microservices/Monolith) you opt for your project, resiliency is the foremost criteria. It is not an add on feature good to have it, is the first class citizen now.
So Resiliency is mandatory — when you are planning and developing your project also think about Resilience spend time on it. Think how you can offer a Resilient Architecture. There are many strategies to achieve resilience like Request Timeout, Maximum Retries, failing rate etc. So while developing your project Identify the resource intensive areas try to build it in that fashion, so that there is no resource hogging happens. Also, provide a Fallback mechanism so you can avoid cascade failures and eventually achieve a robust system.
| Reference: | Deep Dive to Hystrix Resiliency Maintenance from our JCG partner Shamik Mitra at the Make and Know Java blog. |
