Introduction
In my previous posts here and here I showed you how to index data into Elasticsearch from a SQL DB using JDBC and Elasticsearch JDBC importer library. In the first article here I mentioned some of the shortcomings of using the importer library which I have copied here:
- No support for ES version 5 and above
- There is a possibility of duplicate objects in the array of nested objects. But de-duplication can be handled at the application layer.
- There can be a possibility of delay in support for latest ES versions.
All the above shortcomings can be overcome by using Logstash and its following plugins:
- JDBC Input plugin – For reading the data from SQL DB using JDBC
- Aggregate Filter plugin – this is for aggregating the rows from SQL DB into nested objects.
Creating Elasticsearch Index
I will be using the latest ES version i.e 5.63 which can be downloaded from Elasticsearch website here. We will create an index world_v2 using the mapping available here.
1 2 | $ curl -XPUT --header "Content-Type: application/json" http://localhost:9200/world_v2 -d @world-index.json |
or using Postman REST client as shown below:
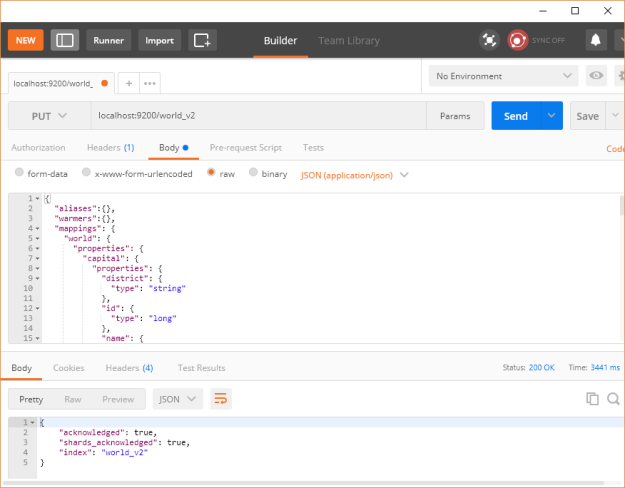
To confirm that the index has been created successfully, open this URL http://localhost:9200/world_v2 in the browser to get something similar to as shown below:

Creating Logstash Configuration File
We should be picking the equivalent logstash version which would be 5.6.3 and it can be downloaded from here. And then we need to install the JDBC input plugin, Aggregate filter plugin and Elasticsearch output plugin using the following commands:
1 2 3 | bin/logstash-plugin install logstash-input-jdbcbin/logstash-plugin install logstash-filter-aggregatebin/logstash-plugin install logstash-output-elasticsearch |
We need to copy the following into the bin directory to be able to run our configuration which we will define next:
- Download the MySQL JDBC jar from here.
- Download the file containing the SQL query for fetching the data from here.
We will copy the above into Logstash’s bin directory or any directory where you will have the logstash configuration file, this is because we are referring to these two files in the configuration using their relative paths. Below is the Logstash configuration file:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 | input { jdbc { jdbc_connection_string => "jdbc:mysql://localhost:3306/world" jdbc_user => "root" jdbc_password => "mohamed" # The path to downloaded jdbc driver jdbc_driver_library => "mysql-connector-java-5.1.6.jar" jdbc_driver_class => "Java::com.mysql.jdbc.Driver" # The path to the file containing the query statement_filepath => "world-logstash.sql" }}filter { aggregate { task_id => "%{code}" code => " map['code'] = event.get('code') map['name'] = event.get('name') map['continent'] = event.get('continent') map['region'] = event.get('region') map['surface_area'] = event.get('surface_area') map['year_of_independence'] = event.get('year_of_independence') map['population'] = event.get('population') map['life_expectancy'] = event.get('life_expectancy') map['government_form'] = event.get('government_form') map['iso_code'] = event.get('iso_code') map['capital'] = { 'id' => event.get('capital_id'), 'name' => event.get('capital_name'), 'district' => event.get('capital_district'), 'population' => event.get('capital_population') } map['cities_list'] ||= [] map['cities'] ||= [] if (event.get('cities_id') != nil) if !( map['cities_list'].include? event.get('cities_id') ) map['cities_list'] << event.get('cities_id') map['cities'] << { 'id' => event.get('cities_id'), 'name' => event.get('cities_name'), 'district' => event.get('cities_district'), 'population' => event.get('cities_population') } end end map['languages_list'] ||= [] map['languages'] ||= [] if (event.get('languages_language') != nil) if !( map['languages_list'].include? event.get('languages_language') ) map['languages_list'] << event.get('languages_language') map['languages'] << { 'language' => event.get('languages_language'), 'official' => event.get('languages_official'), 'percentage' => event.get('languages_percentage') } end end event.cancel() " push_previous_map_as_event => true timeout => 5 } mutate { remove_field => ["cities_list", "languages_list"] }}output { elasticsearch { document_id => "%{code}" document_type => "world" index => "world_v2" codec => "json" hosts => ["127.0.0.1:9200"] }} |
We place the configuration file in the logstash’s bin directory. We run the logstash pipeline using the following command:
1 | $ logstash -w 1 -f world-logstash.conf |
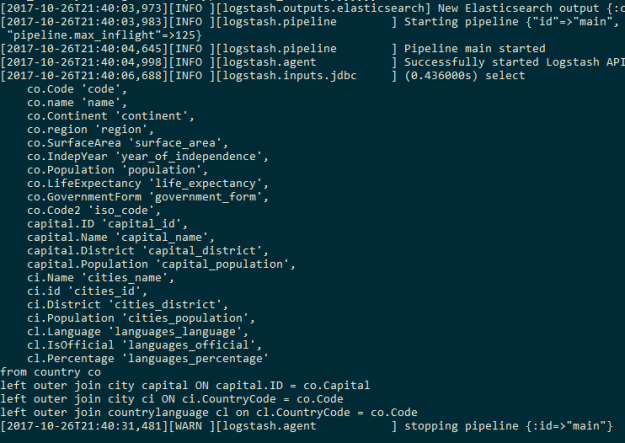
We are using 1 worker because multiple workers can break the aggregations as the aggregation happens based on the sequence of events having a common country code. We will see the following output on successful completion of the logstash pipeline:
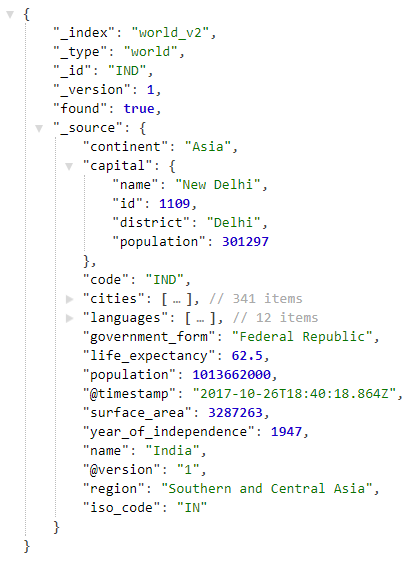
Open the following URL http://localhost:9200/world_v2/world/IND in the browser to view the information for India indexed in Elasticsearch as shown below:
| Published on Java Code Geeks with permission by Mohamed Sanaulla, partner at our JCG program. See the original article here: Aggregate and Index Data into Elasticsearch using Logstash, JDBC Opinions expressed by Java Code Geeks contributors are their own. |
