What is Apache Kafka?
Apache Kafka is a distributed streaming system with publish and subscribe the stream of records. In another aspect it is an enterprise messaging system. It is highly fast, horizontally scalable and fault tolerant system. Kafka has four core APIs called,
Producer API:
This API allows the clients to connect to Kafka servers running in cluster and publish the stream of records to one or more Kafka topics .
Consumer API:
This API allows the clients to connect to Kafka servers running in cluster and consume the streams of records from one or more Kafka topics. Kafka consumers PULLS the messages from Kafka topics.
Streams API:
This API allows the clients to act as stream processors by consuming streams from one or more topics and producing the streams to other output topics. This allows to transform the input and output streams.
Connector API:
This API allows to write reusable producer and consumer code. For example, if we want to read data from any RDBMS to publish the data to topic and consume data from topic and write that to RDBMS. With connector API we can create reusable source and sink connector components for various data sources.
What use cases Kafka used for?
Kafka is used for the below use cases,
Messaging System:
Kafka used as an enterprise messaging system to decouple the source and target systems to exchange the data. Kafka provides high throughput with partitions and fault tolerance with replication compared to JMS.
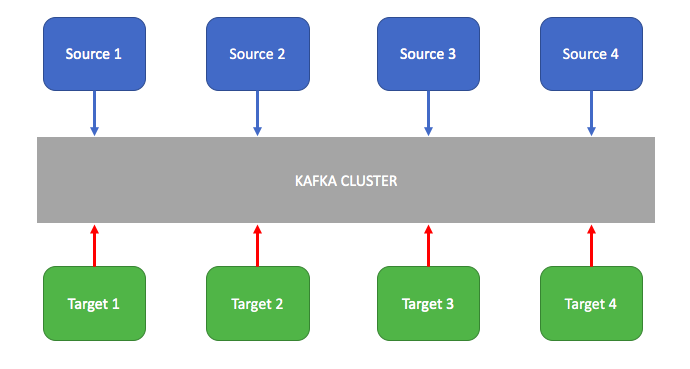
Web Activity Tracking:
To track the user journey events on the website for analytics and offline data processing.
Log Aggregation:
To process the log from various systems. Especially in the distributed environments, with micro services architectures where the systems are deployed on various hosts. We need to aggregate the logs from various systems and make the logs available in a central place for analysis. Go through the article on distributed logging architecture where Kafka is used https://smarttechie.org/2017/07/31/distributed-logging-architecture-for-micro-services/
Metrics Collector:
Kafka is used to collect the metrics from various systems and networks for operations monitoring. There are Kafka metrics reporters available for monitoring tools like Ganglia, Graphite etc…
Some references on this https://github.com/stealthly/metrics-kafka
What is broker?
An instance in a Kafka cluster is called as broker. In a Kafka cluster if you connect to any one broker you will be able to access entire cluster. The broker instance which we connect to access cluster is also known as bootstrap server. Each broker is identified by a numeric id in the cluster. To start with Kafka cluster three brokers is a good number. But there are clusters which has hundreds of brokers in it.
What is Topic?
A topic is a logical name to which the records are published. Internally the topic is divided into partitions to which the data is published. These partitions are distributed across the brokers in cluster. For example if a topic has three partitions with 3 brokers in cluster each broker has one partition. The published data to partition is append only with the offset increment.
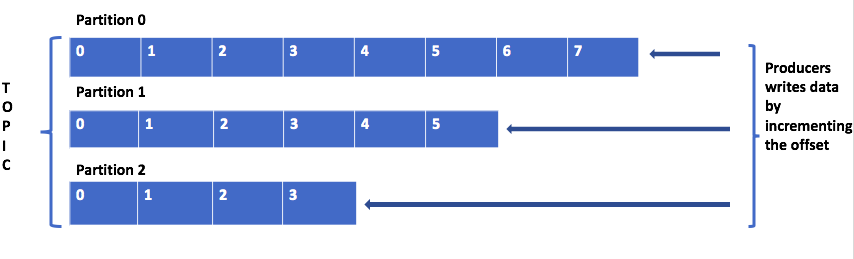
Below are the couple of points we need to remember while working with partitions.
- Topics are identified by its name. We can have many topics in a cluster.
- The order of the messages is maintained at the partition level, not across topic.
- Once the data written to partition is not overridden. This is called immutability.
- The message in partitions are stored with key, value and timestamp. Kafka ensures to publish the message to same partition for a given key.
- From the Kafka cluster, each partition will have a leader which will take read/write operations to that partition.
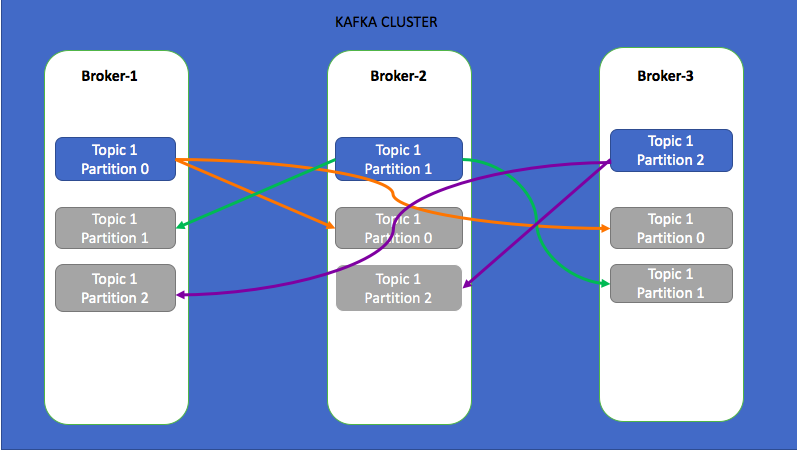
In the above example, I have created a topic with three partitions with replication factor 3. In this case as the cluster is having 3 brokers, the three partitions are evenly distributed and the replicas of each partition is replicated over to another 2 brokers. As the replication factor is 3, there is no data loss even 2 brokers goes down. Always keep replication factor is greater than 1 and less than or equal to number of brokers in the cluster. You can not create topic with replication factor more then the number of brokers in a cluster.
In the above diagram, for each partition there is a leader(glowing partition) and other in-sync replicas(gray out partitions) are followers. For partition 0, the broker-1 is leader and broker-2, broker-3 are followers. All the reads/writes to partition 0 will go to broker-1 and the same will be copied to broker-2 and broker-3.
Now let us create Kafka cluster with 3 brokers by following the below steps.
Step 1:
Download the Apache Kafka latest version. In this example I am using 1.0 which is latest. Extract the folder and move into the bin folder. Start the Zookeeper which is essential to start with Kafka cluster. Zookeeper is the coordination service to manage the brokers, leader election for partitions and alerting the Kafka during the changes to topic ( delete topic, create topic etc…) or brokers( add broker, broker dies etc …). In this example I have started only one Zookeeper instance. In production environments we should have more Zookeeper instances to manage fail-over. With out Zookeeper Kafka cluster cannot work.
1 | ./zookeeper-server-start.sh ../config/zookeeper.properties |
Step 2:
Now start Kafka brokers. In this example we are going to start three brokers. Goto the config folder under Kafka root and copy the server.properties file 3 times and name it as server_1.properties, server_2.properties and server_3.properties. Change the below properties in those files.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 | #####server_1.properties#####broker.id=1listeners=PLAINTEXT://:9091log.dirs=/tmp/kafka-logs-1#####server_2.properties######broker.id=2listeners=PLAINTEXT://:9092log.dirs=/tmp/kafka-logs-2######server_3.properties#####broker.id=3listeners=PLAINTEXT://:9093log.dirs=/tmp/kafka-logs-3M |
Now run the 3 brokers with the below commands.
1 2 3 4 5 6 7 8 | ###Start Broker 1 #######./kafka-server-start.sh ../config/server_1.properties###Start Broker 2 #######./kafka-server-start.sh ../config/server_2.properties###Start Broker 3 #######./kafka-server-start.sh ../config/server_3.properties |
Step 3:
Create topic with below command.
1 | ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 3 --topic first_topic |
Step 4:
Produce some messages to the topic created in above step by using Kafka console producer. For console producer mention any one of the broker address. That will be the bootstrap server to gain access to the entire cluster.
1 2 3 4 5 6 | ./kafka-console-producer.sh --broker-list localhost:9091 --topic first_topic>First message>Second message>Third message>Fourth message> |
Step 5:
Consume the messages using Kafka console consumer. For Kafka consumer mention any one of the broker address as bootstrap server. Remember while reading the messages you may not see the order. As the order is maintained at the partition level, not at the topic level.
1 | ./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first_topic --from-beginning |
If you want you can describe the topic to see how partitions are distributed and the the leader’s of each partition using below command.
1 2 3 4 5 6 7 | ./kafka-topics.sh --describe --zookeeper localhost:2181 --topic first_topic#### The Result for the above command#####Topic:first_topic PartitionCount:3 ReplicationFactor:3 Configs: Topic: first_topic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3 Topic: first_topic Partition: 1 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1 Topic: first_topic Partition: 2 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2 |
In the above description, broker-1 is the leader for partition:0 and broker-1, broker-2 and broker-3 has replicas of each partition.
In the next article we will see producer and consumer JAVA API. Till then, Happy Messaging!!!
| Published on Java Code Geeks with permission by Siva Janapati, partner at our JCG program. See the original article here: Introduction to Apache Kafka Opinions expressed by Java Code Geeks contributors are their own. |
