When we build services architectures (Service Oriented Architecture, Microservices, the next incarnation, etc), we end up making a lot more calls over the network. The network is perilous. We try to build redundancy into our services so that we can experience failures in our system and still move forward and process customer requests. An important part of this puzzle of building redundant, resilient systems is smart, application-aware load balancing. Matt Klein recently wrote an awesome piece on modern load balancing that you should probably stop and go read right now.
The circuit-breaker pattern has been an important pattern for building large, resilient distributed systems – especially those targeted for running in the “cloud” as “microservices”. With a circuit-breaker implementation, we try to “short circuit” network calls to systems that seem to experience repetitive failures. Circuit breaking is a subset feature of smart, application-aware load balancing. You’re either explicitly load balancing, or it’s happening implicitly. Let’s look at some approaches to circuit breaking with Netflix Hystrix and how it compares with that of Envoy Proxy.
Circuit breaking
We use circuit-breaking functionality to help guard against partial or total cascading failures. We want to control/reduce/eliminate traffic to unhealthy systems so we don’t continue to overload them and prevent them from recovering. For example, if your search service calls out to the recommendation service for personalized search results, and the recommendation service is returning errors for many different calls, maybe we should stop calling it for a period of time? Maybe the more we retry, and the more stress we put on that system, we are causing it to degrade further? For a period of time, we may decide to just “fail fast” and not allow calls out to the recommendation service. This approach is similar in spirit to how a circuit breaker works in your electrical system for your house. If we experience faults, we should open the circuit to protect the rest of the system. The circuit-breaker pattern forces our application to deal with the fact our network calls can and do fail and help safeguard the overall system from cascading failures. It’s concerned with the perceived health of system components and whether we should route traffic to them.
Netflix OSS Hystrix
Netflix OSS released an implementation of circuit breaker back in 2012 called Netflix OSS Hystrix. Hystrix is a client-side Java library for getting circuit-breaking behavior. Hystrix provides the following behavior.
From “Making the Netflix API more resilient”:
- Custom fallback — in some cases a service’s client library provides a fallback method we can invoke, or in other cases we can use locally available data on an API server (eg, a cookie or local JVM cache) to generate a fallback response
- Fail silent — in this case the fallback method simply returns a null value, which is useful if the data provided by the service being invoked is optional for the response that will be sent back to the requesting client
- Fail fast — used in cases where the data is required or there’s no good fallback and results in a client getting a 5xx response. This can negatively affect the device UX, which is not ideal, but it keeps API servers healthy and allows the system to recover quickly when the failing service becomes available again.
The circuit-breaking functionality can be triggered in a couple different ways.
From “Making the Netflix API more resilient”:
- A request to the remote service times out
- The thread pool and bounded task queue used to interact with a service dependency are at 100% capacity
- The client library used to interact with a service dependency throws an exception
A flow chart of hystrix circuit breaking can be seen here:
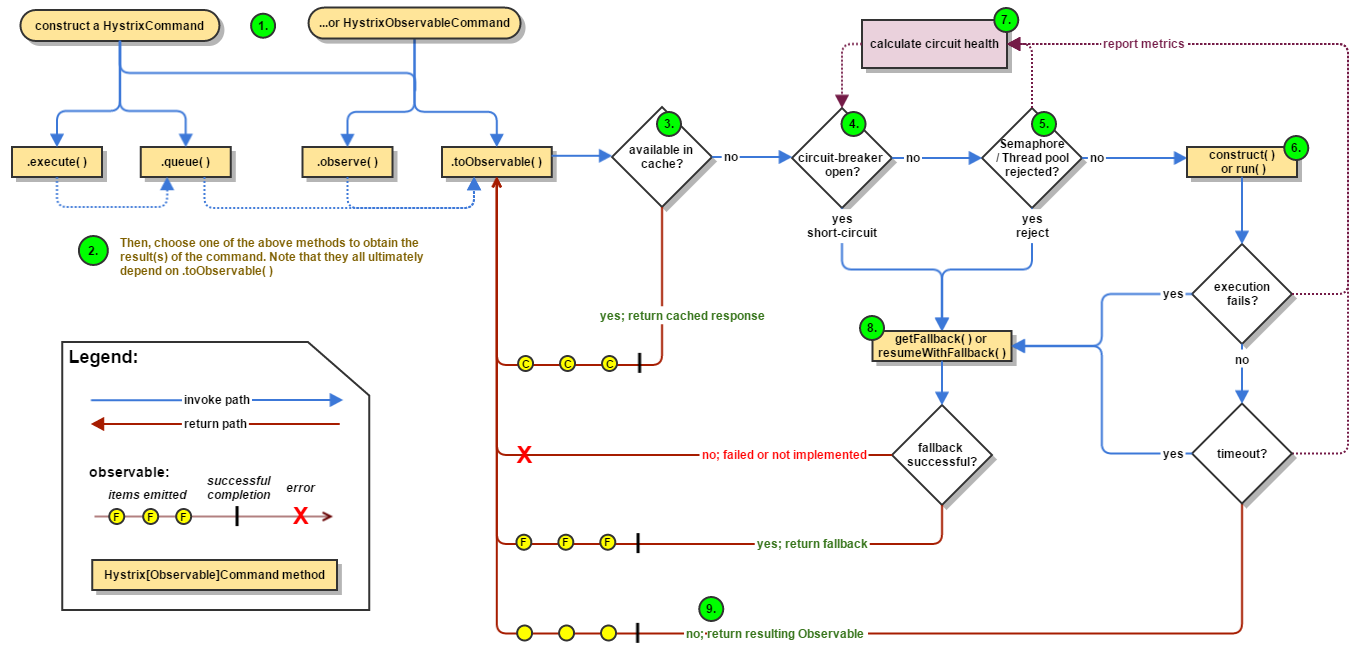
Netflix Hystrix allows very fine-grained control over network interaction. Hystrix allows us to treat the “upstream” cluster with which we interact with very precise configurations depending on the type of call we’re making. For example, if we’re calling the recommendation engine, we’re probably making lots of requests that don’t mutate data (non-write operations). If we are making queries, reading reference data, etc those circuit-breaking configurations may be more relaxed than calls that mutate/write data.
Another important consideration is that Hystrix, makes very apparent that it treats failures/timeouts no different, for the purposes of circuit breaking, where the failure occurred. That is, it could have occurred in the transport or in the client code itself. Hystrix detects circuit breaking thresholds irrespective of where the failure occurred.
Lastly, as I mentioned earlier: circuit breaking is really just a specialized feature of smart, application-aware load balancing. In this case, the “application-aware” part is literal: it’s a library in your application. Within the Netflix OSS ecosystem, you can also pair Hystrix with something like Netflix OSS Ribbon which is another application library for doing client-side load balancing.
Evolution of service mesh
As your services architecture becomes more heterogeneous, you’ll find it difficult (or impractical) to restrict service implementations to specific libraries, frameworks, or even languages. With the evolution of the service mesh, we’re seeing some of these resilience patterns, like circuit breaking, implemented as language/framework-independent solutions in the infrastructure. A service mesh can be defined as:
A decentralized application-networking infrastructure between your services that provides security, resiliency, observability, and routing control.
A service mesh may rely on different L7 (applicatio-level) proxies in its “data plane” to implement resiliency features like retries, timeouts, circuit breakers, etc. In this blog post, we’ll take a look at how Envoy Proxy approaches circuit breaking. Envoy Proxy is the default, out-of-the-box, proxy for Istio Service Mesh so the behavior as described here is applicable to Istio as well.
Envoy Proxy / Istio Service Mesh
Envoy treats its circuit-breaking functionality as a subset of load balancing and health checking. Envoy separates out its “routing” concerns (picking which cluster to talk to) from the communication to the actual backend clusters. This is an important consideration and is what lets Envoy move beyond coarse grained resilience configurations found in other load-balancer implementations. Envoy may have many different “routes” that try to map traffic to the proper backends. Those backends are described as “clusters” and each cluster can have its own cluster-specific configuration for load balancing. Each cluster also can have its own configuration for passive health checking (outlier detection). In fact, there are a handful of envoy configurations that, in concert, provide circuit-breaking functionality as described in the opening paragraph. Let’s take a look at each of these.
We can define an outbound cluster like this:
"clusters": [
{
"name": "httpbin_service",
"connect_timeout_ms": 5000,
"type": "static",
"lb_type": "round_robin",
"hosts": [
{
"url": "tcp://172.17.0.2:8080"
},{
"url": "tcp://172.17.0.3:8080"
}
],We can see in this example that we have a cluster named httpbin_service, we’re going to use round_robin load balancing and we’ll balance across two hosts. Let’s add Envoy’s circuit-breaker config
Circuit breaker
"circuit_breakers": {
"default": {
"max_connections": 1,
"max_pending_requests": 1,
"max_retries": 3
}Here we’re targeting HTTP 1.x workloads. We’re limiting the number of outbound connections to 1 and the number of max pending requests to 1. We’ve also defined a max number of retries. In some ways, this behavior of limiting the connection pool and number of requests is similar to the bulkhead that Netflix Hystrix can provide. If our application opens up more connections than these settings (in practice there’s some leeway – these are not hard limits ), we will see Envoy open the circuit for those calls and report these events in its reporting statistics. See this blog post that goes into detail
Outlier detection
So far, we see that what Envoy calls “circuit breaking” is actually something closer to a connection-pool bulkheads. To get the “open circuit” behavior, Envoy does something called outlier detection. Envoy keeps statistics about the operation of the different endpoints in its load-balancing pool for a particular cluster. If it detects abnormal behavior, it can eject that endpoint from the load-balancing pool. Let’s take a look at an example configuration for outlier detection:
"outlier_detection" : {
"consecutive_5xx": 1,
"max_ejection_percent": 100,
"interval_ms": 1000,
"base_ejection_time_ms": 60000
}This configuration says “if we have 1 5xx” error in our communication with a upstream host we should mark it as unhealthy and temporarily remove it from our load-balancing pool for this cluster. We’ve also configured max_ejection_percent to 100 meaning we are willing to eject any and all hosts that experience these failures. This setting is very environment specific and you’ll want to take care configuring it. Ideally, we will want to do everything we can to route to a host so as not to introduce partial or cascading failures. Envoy by default will set max_ejection_percent to 10.
We are also setting the ejection base period to 6000ms. The actual time that a host would be ejected from the load-balancing pool is this “base” setting multiplied by the number of times it’s been ejected. This allows us to more harshly penalize hosts that seem to be consistently less reliable.
Cluster panic
One thing we should also be aware of with Envoy outlier detection and load balancing. If too many hosts have been ejected by the outlier detection, we could reach a cluster-global “panic” mode which means the proxy will disregard what it believes is the health of the load-balancing pool and begin routing to all hosts again. This is an incredibly powerful baked-in feature. In distributed systems you have to be aware that some times your view of the world in “theory” is incorrect and it’s best to degrade to a mode that doesn’t encourage more cascading failure. On the other hand, you can control this panic percentage (default is if more than 50% of the load balancing pool is ejected, Envoy will panic) and increase the threshold for panic (> 50%) or even disable completely (setting it to 0). Setting it to 0 makes the behavior between Envoy’s circuit breaking functionality more similar to Netflix Hystrix.
Fine-grained circuit breaking policies
One of the benefits of a library approach is the fine-grained application aware circuit-breaking policies we can apply. Hystrix documentation uses the examples of different read/query/write invocations to a single upstream cluster. For example, from the Hystrix FAQ :
Often a single network route via a cluster of loadbalancers will serve many different types of functionality that end up in several different HystrixCommands. Each HystrixCommand needs the ability to set different throughput constraints, timeout values and fallback strategies.
With Envoy, we can accomplish the same surgical circuit-breaking policy via route matching specifying which exact cluster invocations we want to operate on and by specific cluster policies.
Fine-grained circuit-breaking with Istio
We can use Istio higher-level configuration to specify fine-grained clusters and circuit-breaking. In Istio, we use DestinationPolicies to configure load balancing and circuit-breaking policies. Here’s an example of a destiantion policy specifying circuit-breaking functionality in Istio:
metadata:
name: reviews-cb-policy
namespace: default
spec:
destination:
name: reviews
labels:
version: v1
circuitBreaker:
simpleCb:
maxConnections: 100
httpMaxRequests: 1000
httpMaxRequestsPerConnection: 10
httpConsecutiveErrors: 7
sleepWindow: 15m
httpDetectionInterval: 5mWhat to do when circuit is tripped?
The last piece to the circuit breaking puzzle is what happens when we reach our circuit-breaking thresholds. With Hystrix, the concept of fallbacks is built into the library and can be orchestrated by the library. In Hystrix we can do things like cache results, fallback to default values, or even take alternative paths by calling different services. We can also get very fine-grained detail about what failed and make application-specific decisions.
With a service mesh, at the moment without specialized libraries for failure context propagation, the failure reasons are more opaque. This doesn’t mean our application cannot take fallbacks (for both transport and client-specific errors). I’d argue it’s very important for the protocol of any application, whether using library-specific frameworks OR NOT) to always adhere to the promises it’s trying to keep for its clients. If it finds that it cannot complete its intended action, it should figure a way to gracefully degrade. Luckily, you don’t need application-specific frameworks for this. Most languages have built-in error and exception trapping and handling. Fallbacks should be implemented in these exception paths.
Recap
- Circuit breaking is a specialized behavior of load balancers
- Hystrix performs only the circuit-breaking features; load balancing can be paired with Ribbon (or any client-side load balancing library)
- Hystrix has the notion of “fallback” as a library/framework concern and makes that front-and-center
- Envoy has circuit breaking and outlier detection as part of its load balancing implementation
- Envoy “circuit breaking” is more like Hystrix bulkhead and “outlier detection” is more similar to Hystrix circuit-breaker
- Envoy has lots of default production/battle tested features like panic thresholds
- Service mesh lacks the ability to provide failure context back to the application (for now! stay tuned
| Published on Java Code Geeks with permission by Christian Posta, partner at our JCG program. See the original article here: Comparing Envoy and Istio Circuit Breaking With Netflix OSS Hystrix Opinions expressed by Java Code Geeks contributors are their own. |

{kind=link}
Did Christian move from RedHat