In a purist REST approach, all endpoints (except the starting endpoint) are opaque and their various details shouldn’t need to be published. Even if this approach is being used, the points in this article are relevant as Server logic will have to determine when something requires a end point or not.
Introduction
In a REST architecture an entity or a resource (for the rest of the article the term entity will be used) may or may not have its own address. For example, suppose we have an inventory application merchants use to sell their products. Immediately it is possible to see a Product entity. It’s URL will look something like: /product/{id}
Now, it is possible for the merchant selling the Products to add his / her own comments to the Products. For example, ”
Sells very well on Fridays” or “Consider changing price if product doesn’t start selling“. A Product can have 0..* Comments. As stated, the Product has its own address: /product/{id} for example /product/1231233
and a response payload like this
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 | { "id":"1231233", "type":"Beer", "comments": [{ "id":"1", "comment":"Sells very well on Fridays" }, { "id":"2", "comment":"Consider changing price if product doesn't start selling" }]} |
As can be seen, the payload returns a collection of Comment Objects. Should the individual comments each have their own address as well or is it okay that they are just embedded into the Product response? To help the answer this question the following should be considered.
Does the Entity have any meaning outside the Containing Entity Context?
If an Entity (for example Comment) has meaning outside their containing Entity (for example Product) then they should have their own address. For example, suppose the Entity was Student and the Student returned a list of Universities he / she had studied. These Universities have their own meaning outside the Student. So obviously the University should have its own address. In the Activity / Comments scenario, the Comments only exist for the activity. No other Entity will ever reference them or need to reference them. Therefore further aspects needs to be considered.
Is it desirable to perform actions on the individual entities?
Should the client be allowed to create, read, update or delete the individual entity? These have to be considered separately.
Writes: Create, Update, Delete
In the Product / Comments scenario, a Comment would never be created outside or without an Product. It is essentially added to an Product. This could be considered as a partial update to the Product. However, an update or delete to an existing Comment could also be considered a partial update to the Product. This creates complexity on how to differentiate between Create / Updates and Deletes of a Comment using a partial update on the Product. If this is required, it would be much simpler to create a contextual address for the Comment (which indicates the hierarchical nature of the Product / Comment) then allow the Client sent POST, PUT, PATCH, DELETES to that.
Example URL: /product/1231233/comment/1
Reads
In some scenarios the parent containing Entity may not return all the information about the child Entities. For example, again consider the Product –> Comment scenario. Suppose the comment was very large. This would mean the payload for the Product was also very large. In such cases, it might be more prudent for the Product to just return a summary of the Comment and if the client wants the full Entity to make an individual request. Similarly, if there’s a big performance cost to get an individual Entity (for example a 3rd party API has to be invoked to get all the information about the comment), it can make more sense to just send a URL link to the Entity rather the than the actual entity contents.
N+1 Problem
If individual Reads are required, be careful that the N+1 problem doesn’t then get introduced. For example, suppose a Product could have 100 Comments. the Product API will only return a summary of the Comment and a link to each individual comment if the client wants all the information. However, if the client wants every single comment, this means there will now be 100 HTTP requests. If this is a potential scenario, then a secondary endpoint which aggregates all the comments into the Product should be considered. This is similar to the API Gateway pattern.
Surface Area of Endpoints
In any architecture when contracts are published, if there are too many it can become very unwieldy for developers to understand. Most well known APIs (e.g. PayPal, Amazon, Twitter, Google) usually only have about 20 – 30 addresses. This is a good aim to have. If there are 5,000 different addresses it can become way too large and difficult to control etc.
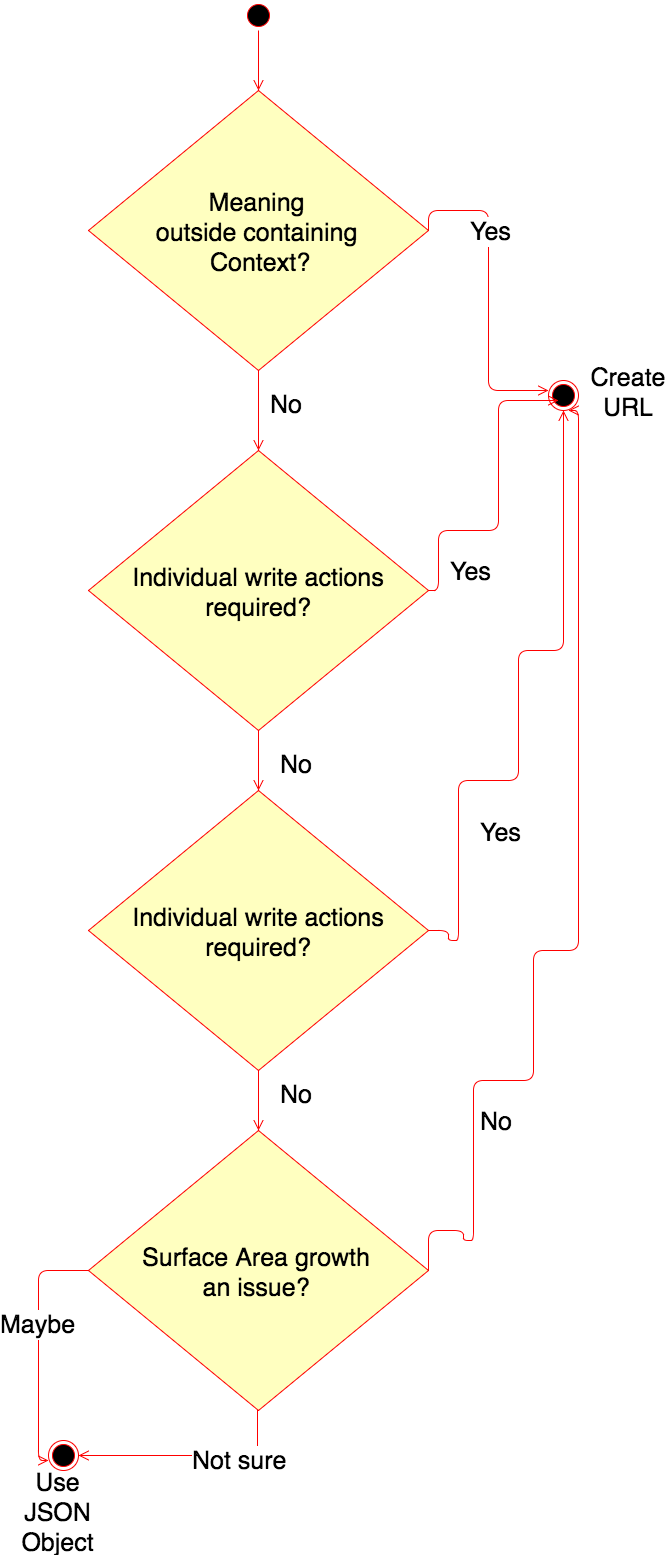
In summary, the decision diagram provides guidance on what you should do.
| Published on Java Code Geeks with permission by Alex Staveley, partner at our JCG program. See the original article here: When a REST Resource should get its own Address? Opinions expressed by Java Code Geeks contributors are their own. |
