Because Java-based applications are often used in a wide variety of operating systems and environments, it is not uncommon for Java developers to run into issues related to character-based input and output. Blog posts covering these issues include The Policeman’s Horror: Default Locales, Default Charsets, and Default Timezones; Annotating JDK default data; Encoding issues: Solutions for linux and within Java apps; Silly Java Strings; Java: a rough guide to character encoding; and this post with too long of a title to list here.
Several enhancements have been made to Java over the years to reduce these issues, but there are still sometimes issues when the default charset is implicitly used. The book Java Puzzlers features a puzzle (Puzzle #18) describing the quirkiness related to the “vagaries of the default charset” in Java.
With all of these issues related to Java’s default charset, the presence of the draft JEP “Use UTF-8 as default Charset” (JDK-8187041) is welcome. In addition to potentially resolving issues related to the default charset, this JEP already provides a nice overview of what these issues are and alternatives to deal with these issues today. The JEP’s “Motivation” section currently summarizes why this JEP is significant: “APIs that use the default charset are a hazard for developers that are new to the Java platform” and “are also a bugbear for experienced developers.”
The issues with “default” charset are complicated by different uses of charsets and by difference approaches currently available in the JDK APIs that lead to more than one “default.” Here is a breakdown of the issues to be considered.
- The “default” charset describing the character set of file contents is potentially different than the “default” charset describing the character set of file paths.
- The Java system property
file.encodingspecifies the default charset for file contents and its setting is what is returned by java.nio.charsets.Charset.defaultCharset(). - The Java system property
sun.jnu.encodingspecifies the default charset for file paths and, according to this post, was “originally only used for Windows but now we have cases where it may different tofile.encodingon other platforms.” - Regarding these system properties (
file.encodingandsun.jnu.encoding), the draft JEP currently states (I added the highlight), “The value of these system properties can be overridden on the command line although doing so has never been supported.”
- The Java system property
- There are two types of “default” pertaining to character sets used for reading/writing file contents.
- Some JDK methods do not allow charset to be specified and always assume a “default” charset of UTF-8 only for that specific method and regardless of any locale or system configuration.
- Some JDK methods do not allow charset to be specified and assume a system-wide (“platform”) “default” charset (that associated with
file.encoding/Charset.defaultCharset()described above) that is based on locale and system configuration.
The draft JEP “Use UTF-8 as default Charset” will help address the issues related to different types of “default” when it comes to charset used by default for reading and writing file contents. For example, it will remove the potential conflict that could arise from writing a file using a method that uses the platform default and reading that file from a method that always uses UTF-8 regardless of the platform default charset. Of course, this is only a problem in this particular case if the platform default is NOT UTF-8.
The following Java code is a simple class that prints out some of the settings related to charsets.
Displaying Default Charset Details
package dustin.examples.charset;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.charset.Charset;
import java.util.Locale;
import static java.lang.System.out;
/**
* Demonstrate default Charset-related details.
*/
public class CharsetDemo
{
/**
* Supplies the default encoding without using Charset.defaultCharset()
* and without accessing System.getProperty("file.encoding").
*
* @return Default encoding (default charset).
*/
public static String getEncoding()
{
final byte [] bytes = {'D'};
final InputStream inputStream = new ByteArrayInputStream(bytes);
final InputStreamReader reader = new InputStreamReader(inputStream);
final String encoding = reader.getEncoding();
return encoding;
}
public static void main(final String[] arguments)
{
out.println("Default Locale: " + Locale.getDefault());
out.println("Default Charset: " + Charset.defaultCharset());
out.println("file.encoding; " + System.getProperty("file.encoding"));
out.println("sun.jnu.encoding: " + System.getProperty("sun.jnu.encoding"));
out.println("Default Encoding: " + getEncoding());
}
}The next screen snapshot shows the results of running this simple class on a Windows 10-based laptop without explicitly specifying either charset-related system property, with specification only of the file.encoding system property, and with specification of both system properties file.encoding and sun.jnu.encoding.
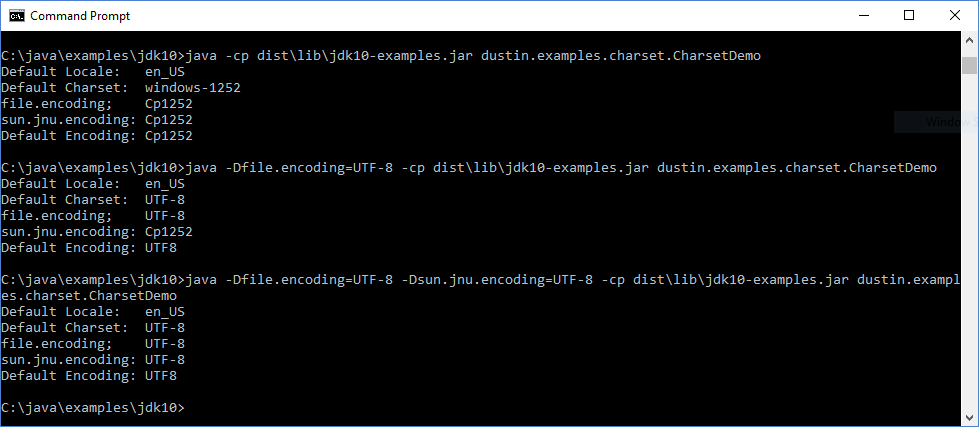
The image just shown demonstrates the ability to control the default charsets via properties. It also demonstrates that, for this Windows environment with a locale of en_US, the default charset for both file contents and file paths is windows-1252 (Cp1252). If the draft JEP discussed in this post is implemented, the default charset for file contents will be changed to UTF-8 even for Windows.
There is the potential for significant breakage in some applications when the default charset is changed to be UTF-8. The draft JEP talks about ways to mitigate this risk including early testing for an application’s susceptibility to the change by explicitly setting the system property file.encoding to UTF-8 beforehand. For cases where it is necessary to keep the current behavior (using a system-determined default charset rather than always using UTF-8), the current version of the draft JEP proposes supporting the ability to specify -Dfile.encoding=SYSTEM.
The JEP is in draft currently and is not associated with any particular JDK version. However, based on recent posts on the JDK mailing lists, I am optimistic that we’ll see UTF-8 as the default charset in a future version of the JDK in the not too distant future.
| Published on Java Code Geeks with permission by Dustin Marx, partner at our JCG program. See the original article here: Java May Use UTF-8 as Its Default Charset Opinions expressed by Java Code Geeks contributors are their own. |
