At OOP 2018 conference in Munich, I presented an updated version of my talk about building scalable, mission-critical microservices with the Apache Kafka ecosystem and Deep Learning frameworks like TensorFlow, DeepLearning4J or H2O. I want to share the updated slide deck and discuss a few updates about newest trends, which I incorporated into the talk.
The main story is the same as in my Confluent blog post about Apache Kafka Ecosystem and Machine Learning: How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka. But I focused more on Deep Learning / Neural Networks. I also discussed a few innovations in the ecosystem of Apache Kafka and trends in ML in the last months: KSQL, ONNX, AutoML, ML platforms from Uber and Netflix. Let’s take a look into these interesting topics and how this is related to each other.
KSQL – A Streaming SQL Language on top of Apache Kafka.
“KSQL is a streaming SQL engine for Apache Kafka. KSQL lowers the entry bar to the world of stream processing, providing a simple and completely interactive SQL interface for processing data in Kafka. You no longer need to write code in a programming language such as Java or Python! KSQL is open-source (Apache 2.0 licensed), distributed, scalable, reliable, and real-time. It supports a wide range of powerful stream processing operations including aggregations, joins, windowing, sessionization, and much more.” More details here: “Introducing KSQL: Open Source Streaming SQL for Apache Kafka“.
You can write SQL-like queries to deploy scalable, mission-critical stream processing apps (which leverage Kafka Streams under the hood). Definitely a highlight in the Kafka open source ecosystem.
KSQL and Machine Learning
KSQL is built on top of Kafka Streams and therefore allows to build scalable, mission-critical services. Machine Learning models including Neural Networks are embeddable easily by building a User Defined Function (UDF). I am preparing an example these days where I apply a Neural Network – more precisely an Autoencoder – for sensor analytics to detect anomalies – i.e. critical values in health checks – of hospital guests in real time to send an alert to the doctor.
Let’s now talk about some interesting new developments in the machine learning ecosystem.
ONNX – A Open Format to Represent Deep Learning Models
“ONNX is a open format to represent deep learning models. With ONNX, AI developers can more easily move models between state-of-the-art tools and choose the combination that is best for them.”
This sounds similar to PMML (Predictive Model Markup Language, see “What is PMML” on KDnuggets) and PFA (Portable Format for Analytics), two other standards to define and share machine learning models. However, ONNX differs in a few aspects:
- focuses on Deep Learning
- has several huge tech companies (AWS, Microsoft, Facebook) and hardware vendors (AMD, NVidia, Intel, Qualcomm, etc.) behind it
- supports many leading open source frameworks, already (including TensorFlow, Pytorch, MXNet)
ONNX is already GA in version 1.0 and production ready (as announced by Amazon, Microsoft and Facebook in December 2017). There is also a nice getting started guide for different frameworks.
ONNX and the Apache Kafka ecosystem
Unfortunately, ONNX has no Java support yet. Therefore, no support yet for embedding it into Kafka Streams Java API natively. Only via workaround like doing a REST call or embedding a JNI binding. But I am very sure this is only a matter of time, because the Java platform is so important in many enterprises to deploy mission-critical applications.
Right now, you could use Kafka’s Java API or other Kafka Clients. Confluent provides official clients for several programming languages, e.g. for Python or Go, which both are perfect for Machine Learning applications, too.
Automated Machine Learning (aka AutoML)
“Automated machine learning (AutoML) is a hot new field with the goal of making it easy to select different machine learning algorithms, their parameter settings, and the pre-processing methods that improve their ability to detect complex patterns in big data” as stated here.
With AutoML, you can build analytic models without any knowledge about Machine Learning. The AutoML implementations uses different implementations of Decision Trees, Clustering, Neural Networks, etc. to build and compare different models out-of-the-box. You just upload or connect your historical data set and click a few buttons to start the process. Maybe not perfect for every use case, but you can easily improve many existing processes without the need for a rare and expensive data scientist.
DataRobot or Google’s AutoML are two of many well-known cloud offerings in this space. H2O’s AutoML is integrated into its open source ML framework, but they also offer a nice UI-focused commercial product called “Driverless AI“. I highly recommend to spend 30min on any AutoML tool. It is really fascinating to see how AI tools develop these days.
AutoML and the Apache Kafka ecosystem
Most AutoML tools offer deployment of their models. You can access the analytic models e.g. via a REST interface. Not a perfect solution for a scalable, event-drive architecture like Kafka. The good news: Many AutoML solutions also allow to export their generated models so that you can deploy them into your application. For example, AutoML in H2O’s open source frameworks is just one of many options. You only use another operation in the programming language of your choice (R, Python, Scala, Web UI):
1 2 3 4 | aml <- h2o.automl(x = x, y = y, training_frame = train, leaderboard_frame = test, max_runtime_secs = 30) |
Similar to what you would do to build a Linear Regression, Decision Tree or Neural Network. The result is generated Java code which you can easily embed into your Kafka Streams microservice or any other Kafka application. AutoML enables you to build and deploy highly scalable machine learning without deep knowledge in ML.
ML Platforms: Uber’s Michelangelo; Netflix’ Meson
Tech giants are typically some years ahead of “traditional enterprises”. They already built years ago what you build today or tomorrow. ML Platforms are no difference. Writing the ML source code to train an analytic model is just a very small part of a real world ML infrastructure. You need to think about the whole development process. The following picture shows the “Hidden Technical Debt in Machine Learning Systems“:
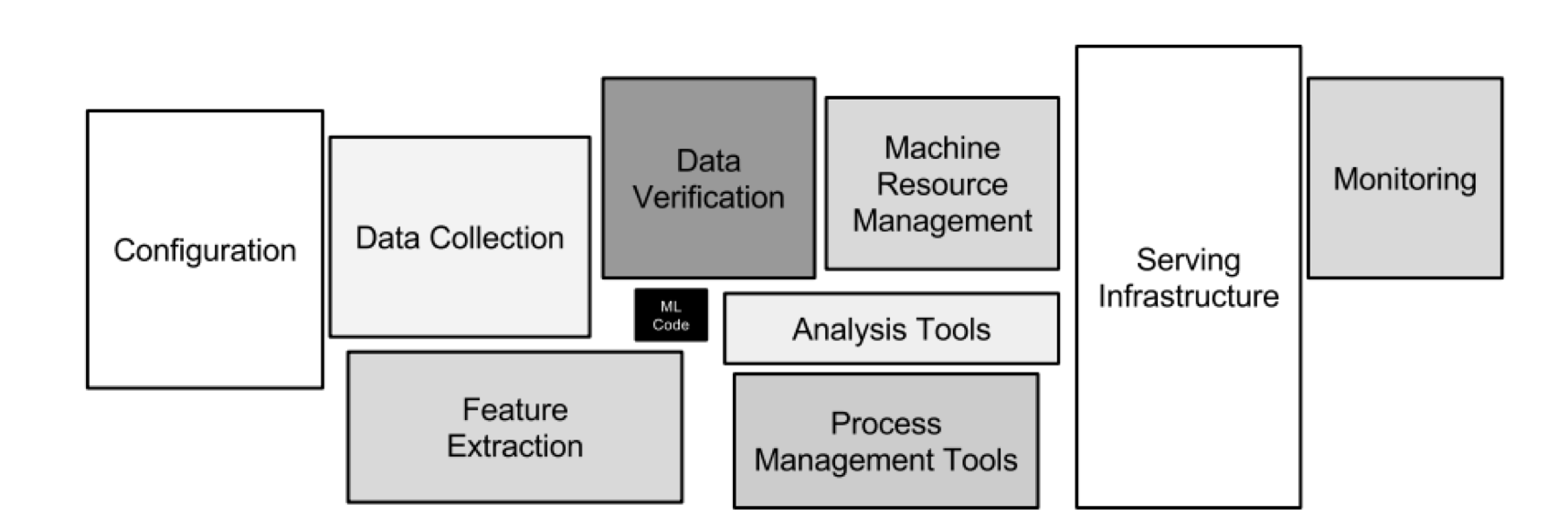
You will probably build several analytic models with different technologies. Not everything will be built in your Spark or Flink cluster or in a single cloud infrastructure. You might run TensorFlow on some big, expensive GPU in the public cloud to build powerful neural networks. Or use H2O to build some small, but very efficient and performant decision trees which do inference in a few microseconds… ML has many use cases.
That’s why many tech giants have built their own ML platforms, like Uber’s Michelangelo or Netflix’ Meson . These ML Platforms allow them to build and monitor powerful, scalable analytic models, but also to stay flexible to choose the right ML technology for each use case.
Apache Kafka ecosystem for ML Platforms
One of the reasons why Apache Kafka is so successful is the huge adoption by many tech giants. Almost all great Silicon Valley companies like LinkedIn, Netflix, Uber, Ebay, “you-name-it” blog and speak about their usage of Kafka as event-driven central nervous system for their mission-critical applications. Many focus on the distributed streaming platform for messaging, but we also see more and more adoption of add-ons like Kafka Connect, Kafka Streams, REST Proxy, Schema Registry or KSQL.
If you look at the above picture again, then think about Kafka: Isn’t it a perfect fit for a ML Platform? Training, monitoring, deployment, inference, configuration, A/B testing, etc. etc. etc. That’s probably why Uber, Netflix and many others use Kafka already as central component in their ML infrastructure.
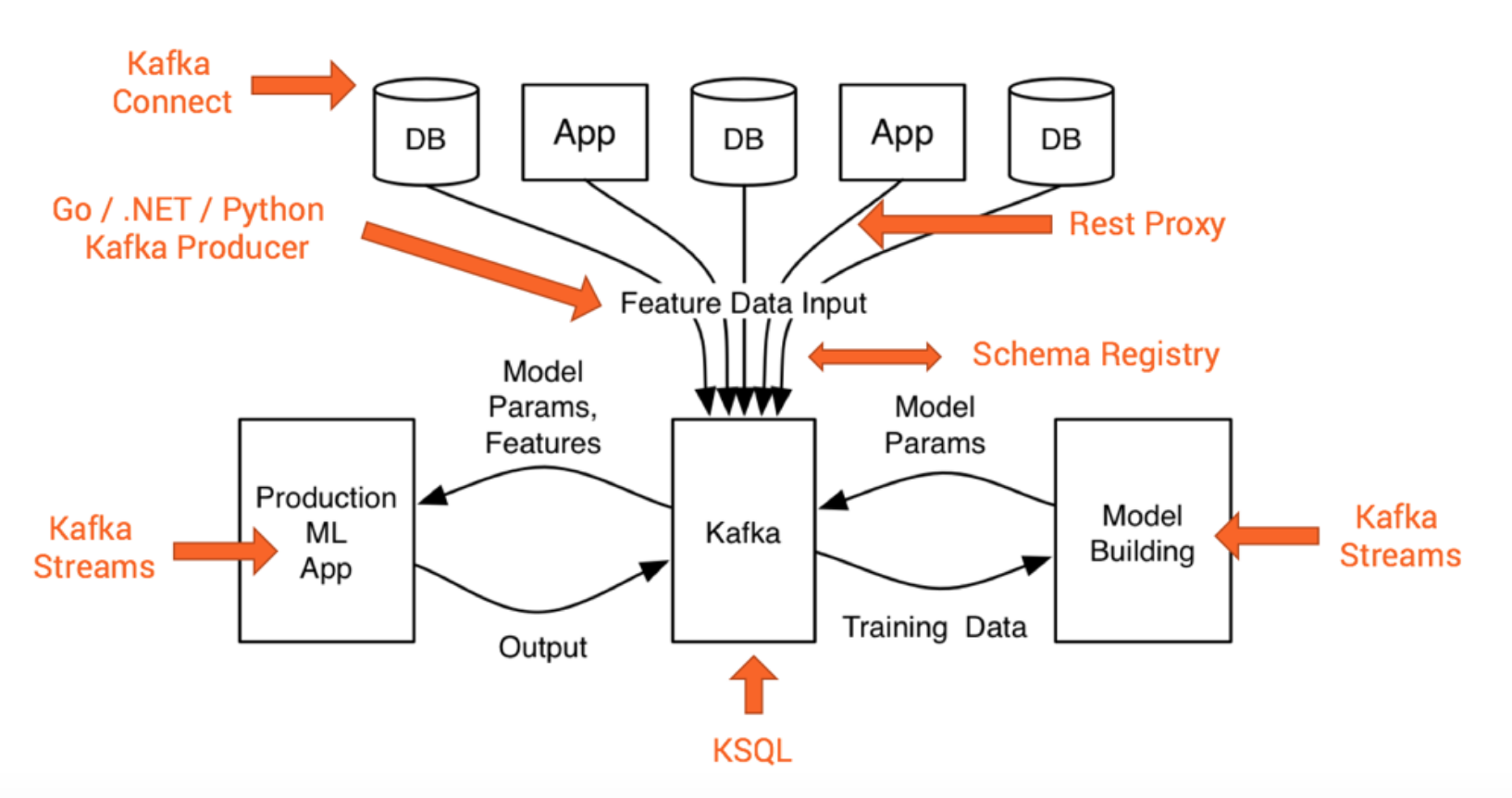
And again, you are not forced to use just one specific technology. One of the great design concepts of Kafka is that you can re-process data again and again from its distributed commit log. This means you can either build different models with one technology as Kafka sink (let’s say Apache Flink or Spark), or connect different technologies like scikit-learn for local testing, TensorFlow running on Google Cloud GPUs for powerful deep learning, an on premise installation of H2O nodes for AutoML, and some other Kafka Streams ML apps deployed in Docker containers or Kubernetes. All of these ML applications consume the data in parallel in their pace and how often they need to.
Here is a great example of how to automate training and deployment of a scalable ML microservice with Kafka and Kafka Streams. No need to add another big data cluster. That’s one of the key differences of using Kafka Streams or KSQL for your ML applications instead of other Stream Processing frameworks.
Apache Kafka and Deep Learning – Slide Deck from OOP
Finally, after all these discussions about the Apache Kafka ecosystem and new trends in Machine Learning / Deep Learning, here are my updated slides from my talk at OOP 2018 conference:
Machine Learning Trends of 2018 combined with the Apache Kafka Ecosystem from Kai Wähner
I have also built a few examples using Apache Kafka, Kafka Streams and different open source ML frameworks like H2O, TensorFlow and DeepLearning4j (DL4J). The Github project shows how easy it is to deploy analytic models to a highly scalable, fault-tolerant, mission-critical Kafka microservice. A KSQL demo will also come soon.
Please share your feedback. Do you already use Kafka in the Machine Learning space? What components in addition to Kafka core do you use? Feel free to contact me to discuss this in more detail.
| Published on Java Code Geeks with permission by Kai Waehner, partner at our JCG program. See the original article here: Machine Learning Trends of 2018 combined with the Apache Kafka Ecosystem Opinions expressed by Java Code Geeks contributors are their own. |

Nice Article, giving me the interest to explore on Kafka.