How to avoid the risks of mishandling application errors?
This one is going to be a bit scary. After all, we’re dealing with a deadly killer here. And some nasty log files. So hold on tight to your seats! We’re going to cover immediate and actionable advice for stopping swallowed exceptions once and for all.
In this post, our goal is to see what it takes to avoid the risks of mishandled errors, and we’re going to do this by understanding the negative impact of swallowed exceptions, and learning how to fix them.
We’re going to investigate and find the silent killer of Java applications. Hopefully, we’ll also have fun while doing it!
The time has come to figure it out.
Table of Contents
Identifying that we have a problem
- A hint of anxiety
- Searching through logs
- The application sickens
- Back to the drawing board
- Exception catch blocks
Investigating a better way to solve it
It all starts with a hint of release day anxiety
This scenario might feel familiar. Unfortunately.
New errors keep appearing on release day, and you’re trying to deal with them as fast as you can. The recent comic strip from monkeyuser.com demonstrates it pretty well:

The investigation has begun and the clock is ticking. Launch days induce anxiety for a reason. We hope at least this wasn’t a Friday. 5PM on a Friday.
Logs logs logs, the immediate suspect
To get started, let’s look at this typical log file.
Let’s say we know there’s something wrong with our application, because we received a lot of complaints from our users, or some business metric is trending down, and now we need to investigate what happened. Here’s a recent example of how this might look like when a reliability story hits the news.
We’ll need to look at massive amounts of unstructured data, trying to understand the story that this log file hides from us, and it’s probably going to be a tedious manual process. In this particular example we’re looking on a file with DEBUG and INFO level statements in it. But more often than not, in production, we’ll only have WARN and above turned on. In fact, we found that about ⅔ of the log data is deactivated in production, you can read more about it right here.
Even if you’re using a log management tool without relying on grepping your way through the console, it’s basically the same log data in a fancier interface.
And this is especially painful when it comes to knowing there’s a problem, before a significant portion of end users is negatively impacted. There is just too much noise out there to have an understanding of what’s important.
After the initial digging in the log file, we see that something just doesn’t feel right. No clues yet. Seems more like guesswork at this point.
The plot thickens and the application sickens
What’s more stressful than looking for the root cause of a production error in a noisy log file?
Not too many things. Well, maybe one thing can make this whole scenario even worse.
What if…
The error we’re looking for, is not even in the logs? ��
The silent killer we’re trying to capture got away and left no clues in the logs. But we still need to figure out what might have caused this.
“Could Not Reproduce” is not an answer we can accept. Not when it means hurting customers and losing revenue.
There must be a better way to solve this.

Back to the drawing board
Now that we’ve seen what’s the negative impact of hidden errors, let’s see how it connects back to exceptions. To dig in, we wanted to take a closer look at what developers do in exception catch blocks. We looked at a recent research paper from the University of Waterloo that used Github’s massive Java dataset to investigate that exact question:
“Analysis of Exception Handling Patterns in Java Projects: An Empirical Study”, the original research can be accessed right here, and we’ve also published an analysis to review the results that you can quickly read through to get the gist.
The research looked at over half a million Java projects that included 16M catch blocks and segmented these into groups.

Let’s see what the researchers found out.
What do developers do in exception catch blocks?
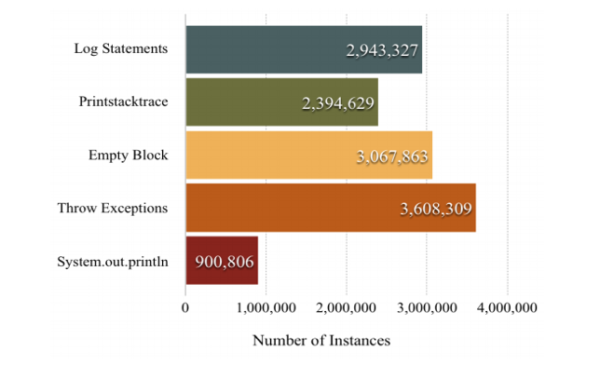
We see that it basically splits into 3 groups:
- Documenting what happened, through logging, printing a stack trace or printing out information to the console.
- Rethrowing an exception, probably a wider abstraction that one of the methods further up the call stack would know how to handle.
- And….. Unfortunately…. Nothing. An empty block. Swallowing the exception without any trace. And looks like it even happens at least as often as logging it. That’s… quite alarming to say the least.
Boom! Busted. Swallowed exceptions are a major factor that’s causing errors to go unnoticed. We found our killer.

Instead of doing the right thing by documenting exceptions with a logged error or warning, sometimes developers choose to ignore them. This could happen either because they’re thinking that it wouldn’t happen, or just ignoring it altogether trying to suppress and hide it.
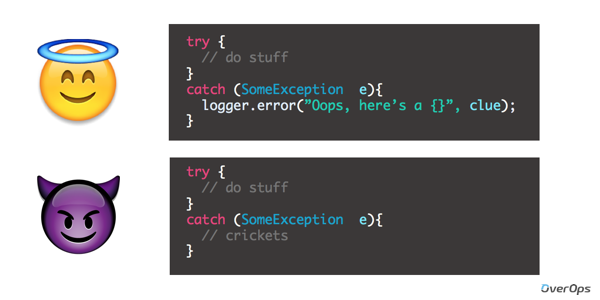
As a quick recap of what we’ve covered so far, we’ve seen that:
- Troubleshooting errors in unforeseen conditions is extremely hard with severe impact on users.
- Approximately 20% of error never make it to the logs.
- Swallowed exceptions are caught in empty catch blocks.
What should change going forward?
Now that we understand the negative impact of swallowed exceptions, let’s talk about what needs to be done to address them.
1. Code review guidelines
Basics first. It might be time refresh some code review guidelines. Make sure there are no empty catch blocks in future deployments, there’s no excuse for neglecting proper exception handling.
2. Logging refactor
This one might be a bit tougher and easier said than done since it would mean taking a deep dive into legacy code. Updating existing code to include meaningful logging statements, and trying to figure out what those empty catch blocks might mean.
One way to enforce these 2 solutions and uncover all empty catch blocks is to make sure code style inspections are turned on in your IDE. Here’s how it looks like in IntelliJ:

3. Continuous Reliability
Another approach that we use ourselves, is to implement a Continuous Reliability approach and automate root cause analysis. Swallowed exceptions or not, there are so many error conditions out there that it’s impossible to predict them all, and also to know which data you need to log to be able to troubleshoot them in the future.
We need to be more agile than ever, and it doesn’t necessarily mean that error prone code should be running loose in production. With Automated Root Cause (ARC) analysis, OverOps captures all known and unknown errors, 100% of exceptions, whether they were caught, uncaught, logged or not, and shows the complete source code and variable state that caused them. It
To see how it works in production and pre-production environments, check our next live demo, or try it out for yourself, it only takes a few minutes to install and analyze your first exception: start a free trial.

Final Thoughts
It’s 2018. Let’s make swallowed exceptions a thing of the past. No more empty catch blocks, and no more unknown errors. Does the scenario we described sounds familiar? Did you have other experiences with swallowed exceptions? Let us know in the comments section below!
| Published on Java Code Geeks with permission by Alex Zhitnitsky, partner at our JCG program. See the original article here: Swallowed Exceptions: The Silent Killer of Java Applications Opinions expressed by Java Code Geeks contributors are their own. |
