I was asked on Twitter recently how is it possible to refactor if one doesn’t understand how the code works. I replied that it is “learning by refactoring.” Then I tried to Google it and found nothing. I was surprised. To me refactoring seems to be the most effective and obvious way to study the source code. Here is how I usually do it, in nine object-oriented steps.

According to Wikipedia, code refactoring is “the process of restructuring existing computer code—changing the factoring—without changing its external behavior.” The goal of refactoring is to make code more readable and suitable for modifications.
Here is what I’m usually doing when I don’t know the code, but need to modify it. The techniques are sorted by the order of complexity, starting with the easiest one.
Remove IDE Red Spots
When I open the source code of Cactoos in IntelliJ IDEA, using my custom settings.jar, I see something like this:
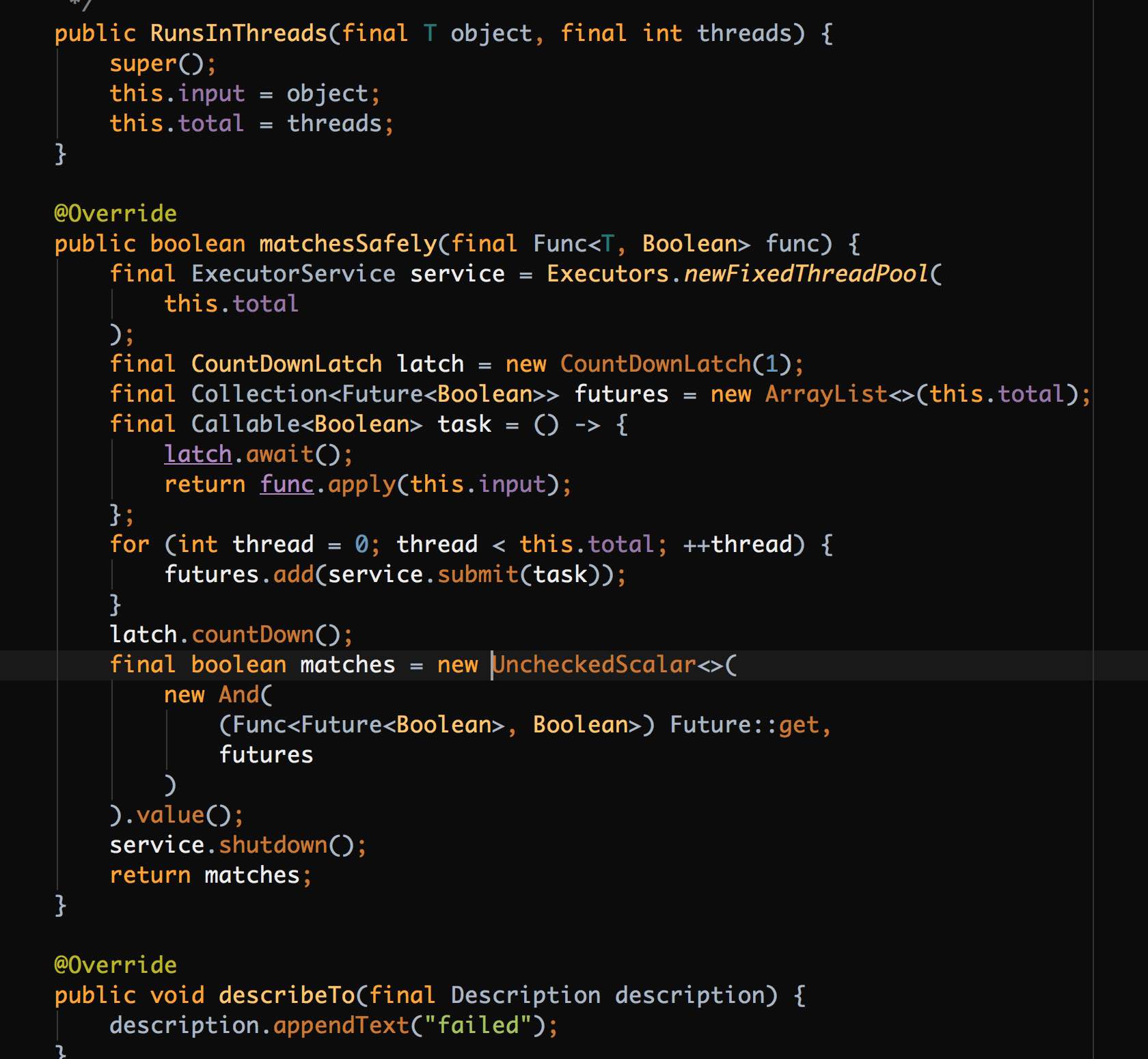
When I open the source code of, say, Spring Boot, I see something like this (it’s o.s.b.ImageBanner randomly picked out of a thousand other classes that look very similar):
See the difference?
The first thing I do, when I see someone else’s code, is to make it “red spots free” for my IDE. Most of those red spots are easy to remove, while others will take some time to refactor. While doing that I learn a lot about the crap program I have to deal with.
Remove Empty Lines
I wrote some time ago that empty lines inside method bodies are bad things. They are obvious indicators of redundant complexity. Programmers tend to add them to their methods in order to simplify things.
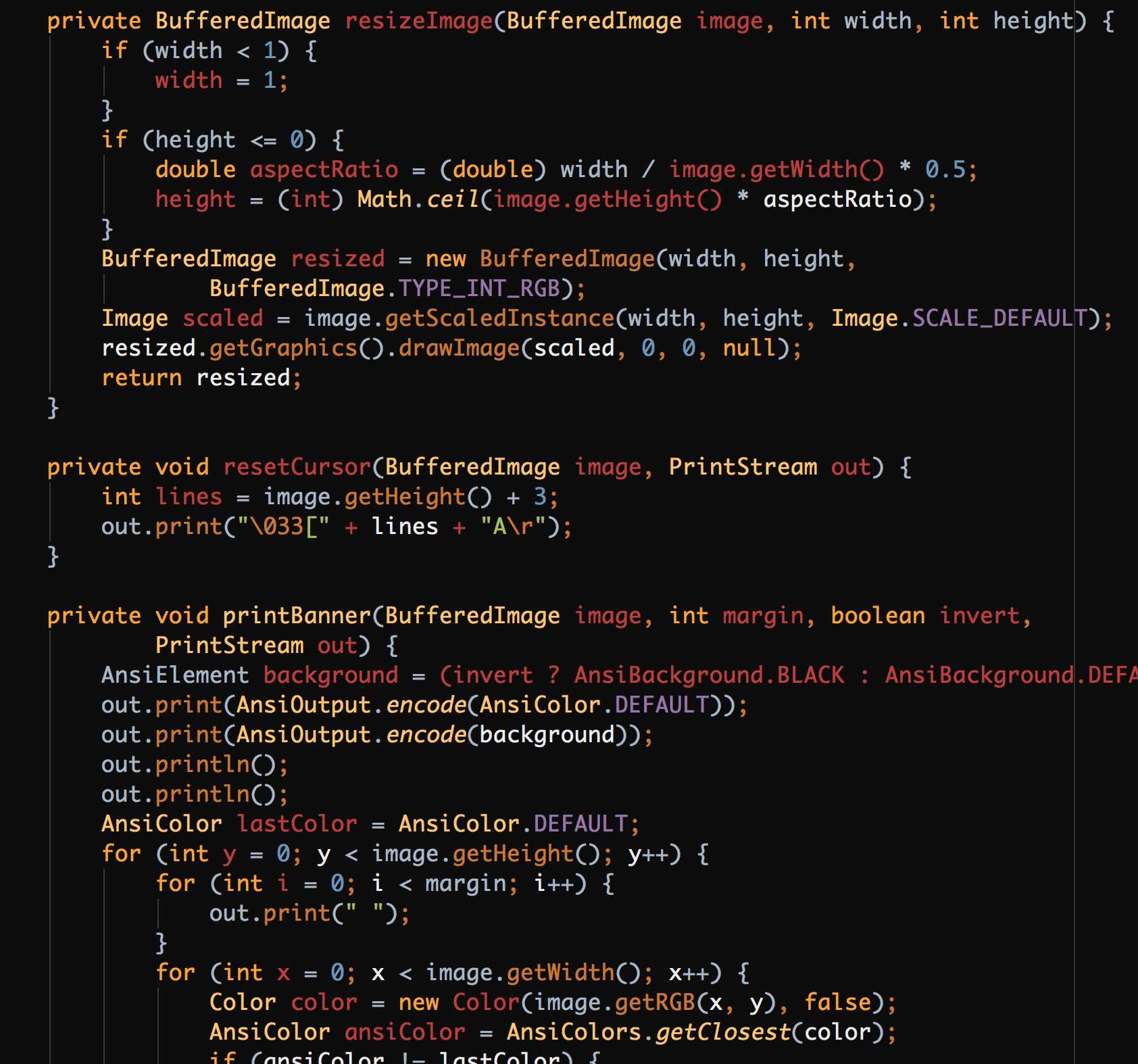
This is a method from the Apache Maven code base (class RepositoryUtils picked at random, but almost all other classes are formatted the same way):
<
Aside from being “all red” their code is full of empty lines. Removing them will make code more readable and will also help me understand how it works. Bigger methods will need refactoring, since without empty lines they will become almost completely unreadable. Hence, I compress, understand, and make them smaller mostly by breaking them down into smaller methods.
Make Names Shorter
I’m generally in favor of short one-noun names for variables and one-verb names for methods. I believe that longer “compound” names are an indicator of unnecessary code complexity.
For example, I found this method registerServletContainerInitializerToDriveServletContextInitializers (69 characters!) in the o.s.b.w.e.u.UndertowServletWebServerFactory class in Spring Boot. I wonder why the author skipped the couldYouPlease prefix and the otherwiseThrowAnException suffix.
Jokes aside, such long method names clearly demonstrate that the code is too complex and can’t be explained with a simple register or even registerContainer. It seems that there are many different containers, initializers, servlets, and other creatures that need to be registered somehow. When I join a project and see a method with this name I’m getting ready for big trouble.
Making names shorter is the mandatory refactoring step I take when starting to work with foreign or legacy code.
Add Unit Tests
Most classes (and methods) come without any documentation, especially if we are talking about closed-source commercial code. We are lucky if the classes have more or less descriptive names and are small and cohesive.
However, instead of documentation I prefer to deal with unit tests. They explain the code much better and prove that it works. When I don’t understand how the class works, I try to write a unit test for it. In most cases it’s not possible, for many reasons.
Remove Multiple Returns
I wrote earlier that the presence of multiple return statements in a single method is not something object-oriented programming should encourage. Instead, a method must always have a single exit point, just like those functions in functional programming.
Look at this method from the o.s.b.c.p.b.Binder class from Spring Boot (there are many similar examples there, I picked this one randomly):
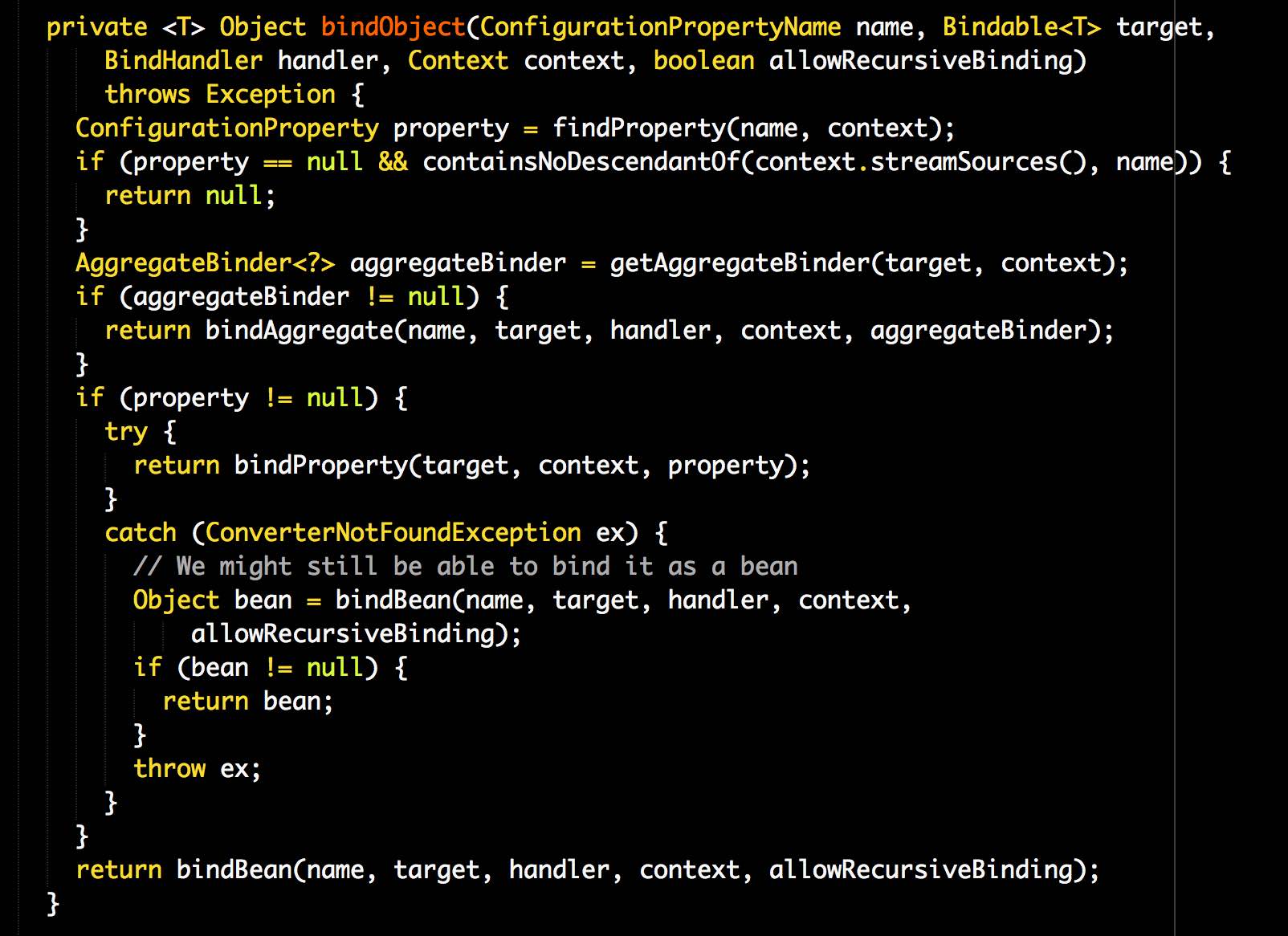
There are five return statements in such a small method. For object-oriented code that’s too much. It’s OK for procedural code, which I also write sometimes. For example, this Groovy script of ours has five return keywords too:
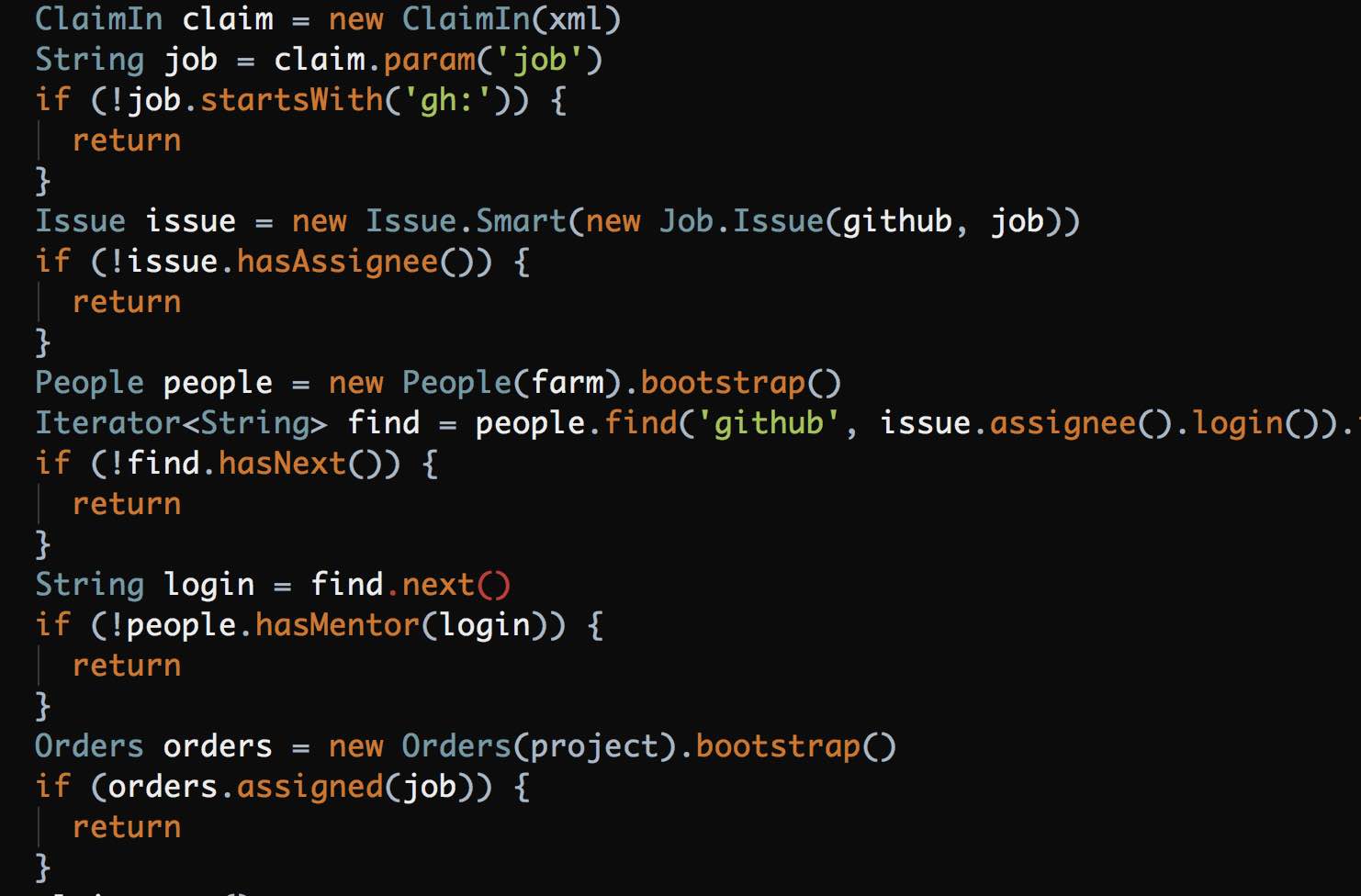
But this is Groovy and it’s not a class. It’s just a procedure, a script.
Refactoring and removing multiple return statements definitely helps make code cleaner. Mostly because without them it’s necessary to use deeper nesting of if/then/else statements and then the code starts to look ugly, unless you break it down into smaller pieces.
Get Rid of NULLs
NULLs are evil, it’s a well-known fact. However, they are still everywhere. For example, there are 4,100 Java files in Spring Boot v2.0.0.RELEASE and 243K LoC, which include the null keyword 7,055 times. This means approximately one null for every 35 lines.
To the contrary, Takes Framework, which I founded a few years ago, has 771 Java files, 154K LoC, and 58 null keywords. Which is roughly one null per 2,700 lines. See the difference?
The code gets cleaner when you remove NULLs, but it’s not so easy to do. Sometimes it’s even impossible. That’s why we still have those 58 cases of null in Takes. We simply can’t remove them, because they are coming from the JDK.
Make Objects Immutable
As I demonstrated some time ago, immutability helps keep objects smaller. Most classes that I see in the foreign code I deal with are mutable. And large.
If you look at any artifact analyzed by jpeek, you will see that in most of them approximately 80% of classes are mutable. Moving from mutability to immutability is a big challenge in object-oriented programming, which, if resolved, leads to better code.
This refactoring step of make things immutable is purely profitable.
Remove Static
Static methods and attributes are convenient, if you are a procedural programmer. If your code is object-oriented, they must go away. In Spring Boot there are 7,482 static keywords, which means one for every 32 lines of code. To the contrary, in Takes we have 310 static-s, which is one every 496 lines.
Compare these numbers with the statistics about NULL and you will see that getting rid of static is a more complex task.
Apply Static Analysis
This is the final step and the most complex one. It’s complex because I configure static analyzers to their maximum potential or even more. I’m using Qulice, which is an aggregator of Checkstyle, PMD, and FindBugs. Those guys are strong by themselves, but Qulice makes them even stronger, adding a few dozen custom-made checks.
The principle I use for static analysis is 0/100. This means that either the entire code base is clean and there are no Qulice complaints, or it’s dirty. There is nothing in the middle. This is not a very typical way of looking at static analysis. Most programmers are using those tools just to collect “opinions” about their code. I’m using them as guides for refactoring.
Check out this video, which demonstrates the amount of complaints Qulice gives for the spring-boot-project/spring-boot sub-module in Spring Boot (the video has no end, since I lost my patience in waiting):
When Qulice says that everything is clean, I consider the code base fully ready for maintenance and modifications. At this point the refactoring is done.
| Published on Java Code Geeks with permission by Yegor Bugayenko, partner at our JCG program. See the original article here: Nine Steps of Learning by Refactoring Opinions expressed by Java Code Geeks contributors are their own. |

settings.jar is not available, could you please upload it ?
They are attached to the original article: http://www.yegor256.com/2018/04/10/learning-by-refactoring.html