How Continuous Delivery Broke Your Application Reliability – and What You Need to Do to Fix It
More frequent deployments are great, but maintaining high-quality code while implementing them is a whole different story.
Everyone is talking about moving towards an automated workflow, and there’s no wonder. We all want to deploy more features and capabilities to our products and applications, and we want to do it as quickly as we can.
However, automation is not something that we should take lightly as it comes with some risks that shouldn’t be ignored. The main one being that moving faster than before means less time for quality assurance.
That’s why we need automation to work both ways; upgrading and improving our application, and also allowing us to learn and adapt according to how it performs with our users. We want to emphasize what’s essential for both dev teams and the users.
Faster Deployment != Better Code Quality
We want to make sure that dev teams are proud of what they do and build, while supplying users and customers with a great product.
The drive towards building a better product, shipping features and innovation faster than before in order to outrun the competition is what helps drive companies towards an automated workflow. And indeed, introducing Continuous Integration into the mix helps us merge and deploy code faster.
With frequent code releases come more frequent issues and errors in production. Now, it’s up to dev and QA teams to figure out how to be certain that everything is working as it should, as well as detect issues before they’re deployed into production.
Feedback Loop Shouldn’t End with QA
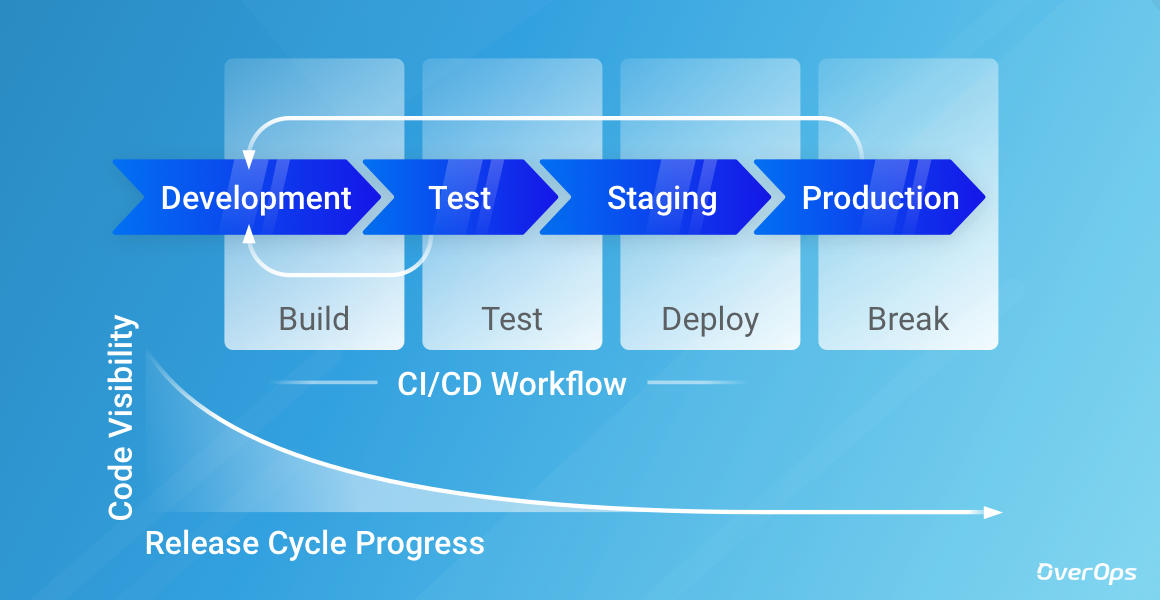
Looking at a small piece of the development process, after dev teams write and deploy the code, it’s time for QA to test it, whether through manual or automated testing methods. When they find issues, they report them back to the dev teams, who apply the needed fixes, re-integrate the code and so on.
In other words, we have a feedback loop between our testing and development stages. This is the backbone of every good development cycle, and it’s what helps us learn and improve over time.
But feedback loops are relevant to the whole development cycle, they don’t end with QA/dev deploying and testing elements in staging environments. As we all know, production tends to display unexpected and surprise-oriented behavior, some might even say that issues and bugs appear out of thin air.
Another feedback loop exists between production and development, helping dev teams understand how their code acts in the “real world” with real-time and real-user behavior. The feedback at this part currently comes from setting up alerts, searching through the logs, and in the worst case scenarios from customers complaining to support.
Unfortunately, our feedback loop isn’t good enough and there’s no running away from issues in production. Different environments act in different ways, and you’ll usually have your engineers spend more than 20% of their week trying to detect and solve these issues.
Feedback loops are critical, and the only way to get full visibility into your application across the software delivery supply chain is to have feedback loops in every step of the way, not just in QA. And we need to make sure that the information we’re getting is reliable, and it gives us the right information necessary to understand what’s going on.
Improving the Feedback, One Loop at a Time
The outside pressure to deploy faster creates gaps between QA and dev, leading to an inability to produce good code in shorter periods of time. When an issue is found it’s tossed back without the right information needed to fix it.
In some cases, dev teams will have to search through massive log files to detect a single issue that happened in production, trying to understand what the user did that led to it in the first place. This process is unavoidable due to the current lack of visibility to how the code and users act in production.
So we have an automated workflow, and our feedback loops are going around non-stop. But it’s not just about “making it work”, it’s about making it better and stronger with every chance we get. And the way to make CI and feedback loops more valuable, is by providing them reliable data every step of the way. This data should include:
- Execution stack and bytecode
- Complete variable state (overlayed on full source code)
- JVM State: Threads, environment variables
- Relevant log statements (including Debug and Trace in production)
- Event analytics (Frequency, failure rate, deployment, application)
And since this is crucial information, we have to make sure it’s reliable and actionable.
We can do that by setting up alerts that will catch errors as soon as they happen, adding endless logs to every function, and/or use different monitoring and detection tools. Inside the team, we can put an emphasis on code review between teams, validate performance in our pre-production environments, apply unit tests an so on.
However, all of these options are more of like bandaids than actual fixes, and while they do promote a better workflow, they might end up impacting the product’s performance. Not only that, these options won’t offer the complete context that we need in order to enhance and perfect the loop.
We’ve spoken to some of our enterprise customers such as banks, healthcare providers and others and learned that they too encounter this issue and need in their environment. And the bigger the organization is, the harder it gets to handle and solve these issues. Not to mention the cost of finding and fixing various issues and bugs in both staging and production.
Final Thoughts
Automated workflows are not enough, and while they help move development faster we need to make sure they are also promoting better code during that process. Improving the feedback loop by adding valuable information to the process is helpful not just for dev and ops teams, but for QA as well.
It will help empower the QA team, by allowing them to supply complete context to the developers. That way, QA can provide comprehensive data and help end the cycle of “cannot reproduce/recreate” as the main conversation between development and QA.
| Published on Java Code Geeks with permission by Hennn Idan, partner at our JCG program. See the original article here: How Continuous Delivery Broke Your Application Reliability – and What You Need to Do to Fix It Opinions expressed by Java Code Geeks contributors are their own. |
