Error handling is one of the hardest and ignored part of software development and if system is distributed then this becomes even harder.
Nice paper is written on Simple Testing Can Prevent Most Critical Failures topic.

Every developer should read this paper. I will try to summarized key take away from this paper but will suggest to read the paper to get more details about it.
Distributed system outage is common and some of the recent example are
Youtube was down on Oct,2018 for around 1+ hour
Amazon was down during Prime day on July,2018
Google services like Map,Gmail,Youtube were down numerous time in 2018
Facebook was also down apart from many data leak issues they are facing.
This paper talks about catastrophic failure that happened in distributed system like Cassandra, Hbase , HDFS, Redis, Map Reduce.
As per paper most of the errors are due to 2 reason
– Failure happens due to complex sequence of events
– Catastrophic error are due to incorrect handling
– I will include 3rd one on “ignoring of design pressure” which i wrote in design-pressure-on-engineering-team post
Example from HBase outage
1 – Load balancer Transfer region R from Slave A to Slave
2 – Slave B open region R
3 – Master delete current Zookeeper region R after it is owned by Slave B
4 – Slave B dies
5 – Region R is assigned to Slave C & Slave C open the region
6 – Master tries to delete Slave B znode on Zookeeper and because Slave b is down and whole cluster goes down due to wrong error handling code.
In above example sequence of event matters to reproduce issue.
HDFS failure when block is not replicated.
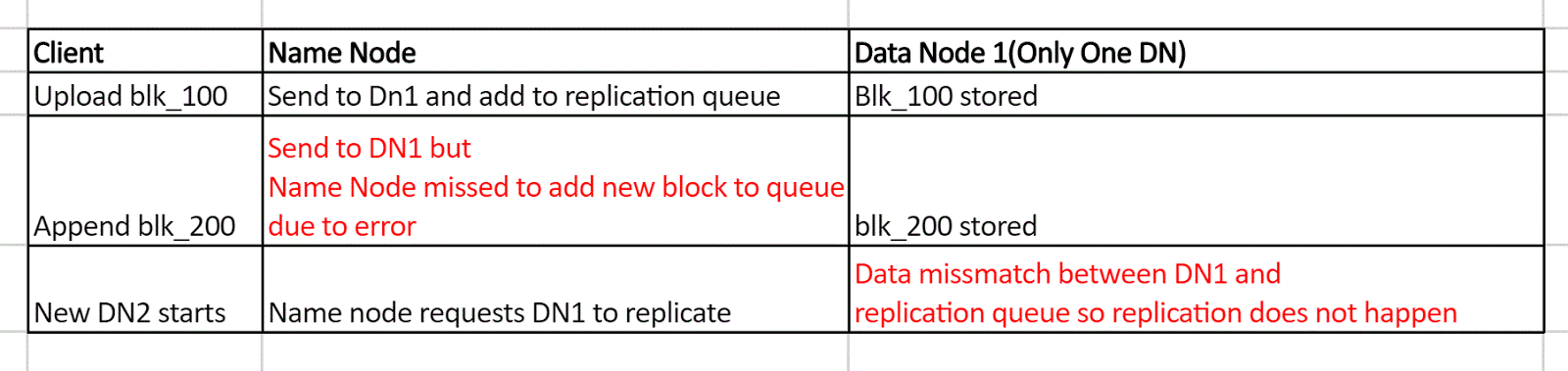
In this example also sequence of event and when new data node starts it exposes bug of system.
Paper has many more examples.
Root cause of error
92% of the catastrophic error happens due to incorrect error handling.
What this means is that error was deducted but error handling code was not good, does this sound like lots of project you have worked on !
1 – Error are ignored
This is reason of 25% of the failure, i think number will be high in many live system.
1 2 3 4 | eg of such errorcatch(RebootException e) {log.info("Reboot occurred....")} |
Yes this harmless looking log statement is ignoring exception and is very common anti pattern of error handling.
2 – Overcatch exception
This is also very common like having generic catch block and bringing down the whole system
1 2 3 | catch(Throwable e) {cluster.abort()} |
3 – TODO/FIXME in comments
Yes real distributed system in production also has lots of TODO/FIXME in critical section of code.
Some other example of error handling
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 | <i>} catch (IOException e) {</i><i> // will never happen </i><i> }</i><i>} catch (NoTransitionException e) {</i><i> /* Why this can happen? Ask God not me. */ </i><i> }</i><i>try { tableLock.release(); } </i><i>catch (IOException e) { </i><i> LOG("Can't release lock”, e); </i><i>} </i> |
4 – Feature development is prioritized
I think all the software engineers will agree to it. This is also called Tech Debt and i can’t think of better example than Knight Capital bankruptcy which was due to config & experimental code.
Conclusion
All the errors are complex to reproduce but better unit test will definitely catch these, this also shows that unit/integration test done in many system is not testing scenario like service going down and coming back again and how it impacts system.
Based on above example it will look like all error are due to java checked exception but it is not different in other system like C/C++ which does not have checked but everything is unchecked , it is developer responsibility to check for it at various places.
On side note language with no type system like Python makes it very easy to write code that will break at runtime and if you are really unlucky then error handling code will have some type error and it will get tested in production.
Also almost all product will have some static code tool(findbugs) integration but these tools does not give more importance to such error handling anti pattern.
Link to issues mention in paper
Please share about more anti pattern you have seen in production system.
Till then Happy unit testing.
| Published on Java Code Geeks with permission by Ashkrit Sharma, partner at our JCG program. See the original article here: Simple Testing Can Prevent Most Critical Failures Opinions expressed by Java Code Geeks contributors are their own. |
