This article documents solving a meaningful event processing problem in a highly efficient manner through the reduction of waste in the software stack.
Java is often seen as a memory hog that cannot operate efficiently in low memory environments. The aim is to demonstrate what many think is impossible, that a meaningful java program can operate in almost no memory. The example processes
2.2 million csv records per second in a 3MB heap with zero gc on a single thread in Java.
You will learn where the main areas of waste exist in a java application and the patterns that can be employed to reduce them. The concept of zero cost abstraction is introduced, and that many optimisations can be automated at compile time through code generation. A maven plugin simplifies the developer workflow.
Our goal is not high performance, that comes as a by-product of maximising efficiency. The solution employs Fluxtion which uses a fraction of the resources compared with existing java event processing frameworks.
Computing and the climate
Climate change and its causes are currently of great concern to many. Computing is a major source of emissions, producing the same carbon footprint as the entire airline industry. In the absence of regulation dictating computing energy consumption we, as engineers, have to assume the responsibility for producing efficient systems balanced against the cost to create them.
On a panel session from infoq 2019 in London, Martin Thompson spoke passionately about building energy efficiency computing systems. He noted controlling waste is the critical factor in minimising energy consumption. Martin’s comments resonated with me, as the core philosophy behind Fluxtion is to remove unnecessary resource consumption. That panel session was the inspiration for this article.
Processing requirements
Requirements for the processing example are:
- Operate in 3MB of heap with zero gc
- Use standard java libraries only, no “unsafe” optimisations
- Read a CSV file containing millions of rows of input data
- Input is a set of unknown events, no pre-loading of data
- Data rows are heterogeneous types
- Process each row to calculate multiple aggregate values
- Calculations are conditional on the row type and data content
- Apply rules to aggregates and count rule breaches
- Data is randomly distributed to prevent branch prediction
- Partition calculations based on row input values
- Collect and group partitioned calculations into an aggregate view
- Publish a summary report at the end of file
- Pure Java solution using high level functions
- No JIT warm-up
Example position and profit monitoring
The CSV file contains trades and prices for a range of assets, one record per row. Position and profit calculations for each asset are partitioned in their own memory space. Asset calculations are updated on every matching input event. Profits for all assets will be aggregated into a portfolio profit. Each asset monitors its current position/profit state and record a count if either breaches a pre-set limit. The profit of the portfolio will be monitored and loss breaches counted.
Rules are validated at asset and portfolio level for each incoming event. Counts of rule breaches are updated as events are streamed into the system.
Row data types
href="https://github.com/gregv12/articles/blob/article_may2019/2019/may/trading-monitor/src/main/java/com/fluxtion/examples/tradingmonitor/AssetPrice.java" target="_blank" rel="noopener noreferrer">AssetPrice - [price: double] [symbol: CharSequence]
Deal - [price: double] [symbol: CharSequence] [size: int]
Sample data
The CSV file has a header lines for each type to allow dynamic column position to field mapping. Each row is preceded with the simple class name of the target type to marshal into. A sample set of records including header:
Deal,symbol,size,price AssetPrice,symbol,price AssetPrice,FORD,15.0284 AssetPrice,APPL,16.4255 Deal,AMZN,-2000,15.9354
Calculation description
Asset calculations are partitioned by symbol and then gathered into a portfolio calculation.
Partitioned asset calculations
asset position = sum(Deal::size) deal cash value = (Deal::price) X (Deal::size) X -1 cash position = sum(deal cash value) mark to market = (asset position) X (AssetPrice::price) profit = (asset mark to market) + (cash position)
Portfolio calculations
portfolio profit = sum(asset profit)
Monitoring rules
asset loss > 2,000 asset position outside of range +- 200 portfolio loss > 10,000
NOTE:
- A count is made when a notifier indicates a rule breach. The notifier only fires on the first breach until it is reset. The notifier is reset when the rule becomes valid again.
- A positive deal::size is a buy, a negative value a sell.
Execution environment
To ensure memory requirements are met (zero gc and 3MB heap) the
Epsilon no-op garbage collector is used, with a max heap size of 3MB. If more than 3MB of memory is allocated throughout the life of the process, the JVM will immediately exit with an out of memory error.
To run the sample: clone from git and in the root of the trading-monitor project run the jar file in the dist directory to generate a test data file of 4 million rows.
git clone --branch article_may2019 https://github.com/gregv12/articles.git cd articles/2019/may/trading-monitor/ jdk-12.0.1\bin\java.exe -jar dist\tradingmonitor.jar 4000000
By default the tradingmonitor.jar processes the data/generated-data.csv file. Using the command above the input data should have 4 million rows and be 94MB in length ready for execution.
Results
To execute the test run the tradingmonitor.jar with no arguments:
jdk-12.0.1\bin\java.exe -verbose:gc -Xmx3M -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC -jar dist\tradingmonitor.jar
Executing the test for 4 million rows the summary results are:
Process row count = 4 million Processing time = 1.815 seconds Avg row exec time = 453 nano seconds Process rate = 2.205 million records per second garbage collections = 0 allocated mem total = 2857 KB allocated mem per run = 90 KB OS = windows 10 Processor = Inte core i7-7700@3.6Ghz Memory = 16 GB Disk = 512GB Samsung SSD PM961 NVMe
NOTE: Results are from the first run without JIT warmup. After jit warmup the code execution times are approx 10% quicker. Total allocated memory is 2.86Mb which includes starting the JVM.
Analysing Epsilon’s output we estimate the app allocates 15% of memory for 6 runs, or 90KB per run. There is a good chance the application data will fit inside L1 cache, more investigations are required here.
Output
The test program loops 6 times printing out the results each time, Epsilon records memory statistics at the end of the run.
jdk-12.0.1\bin\java.exe" -server -XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC -Xmx3M -verbose:gc -jar dist\tradingmonitor.jar
[0.011s][info][gc] Non-resizeable heap; start/max: 3M
[0.011s][info][gc] Using TLAB allocation; max: 4096K
[0.011s][info][gc] Elastic TLABs enabled; elasticity: 1.10x
[0.011s][info][gc] Elastic TLABs decay enabled; decay time: 1000ms
[0.011s][info][gc] Using Epsilon
[0.024s][info][gc] Heap: 3M reserved, 3M (100.00%) committed, 0M (5.11%) used
[0.029s][info][gc] Heap: 3M reserved, 3M (100.00%) committed, 0M (10.43%) used
.....
.....
[0.093s][info][gc] Heap: 3M reserved, 3M (100.00%) committed, 1M (64.62%) used
[0.097s][info][gc] Heap: 3M reserved, 3M (100.00%) committed, 2M (71.07%) used
portfolio loss gt 10k count -> 792211.0
Portfolio PnL:-917.6476000005273
Deals processed:400346
Prices processed:3599654
Assett positions:
-----------------------------
[1.849s][info][gc] Heap: 3M reserved, 3M (100.00%) committed, 2M (76.22%) used
MSFT : AssetTradePos{symbol=MSFT, pnl=484.68589999993696, assetPos=97.0, mtm=1697.0247000000002, cashPos=-1212.3388000000632, positionBreaches=139, pnlBreaches=13628, dealsProcessed=57046, pricesProcessed=514418}
GOOG : AssetTradePos{symbol=GOOG, pnl=-998.6065999999155, assetPos=-1123.0, mtm=-19610.1629, cashPos=18611.556300000084, positionBreaches=3, pnlBreaches=105711, dealsProcessed=57199, pricesProcessed=514144}
APPL : AssetTradePos{symbol=APPL, pnl=-21.881300000023202, assetPos=203.0, mtm=3405.1017, cashPos=-3426.9830000000234, positionBreaches=169, pnlBreaches=26249, dealsProcessed=57248, pricesProcessed=514183}
ORCL : AssetTradePos{symbol=ORCL, pnl=-421.9756999999504, assetPos=-252.0, mtm=-4400.4996, cashPos=3978.5239000000497, positionBreaches=103, pnlBreaches=97777, dealsProcessed=57120, pricesProcessed=513517}
FORD : AssetTradePos{symbol=FORD, pnl=112.14559999996254, assetPos=-511.0, mtm=-7797.8089, cashPos=7909.9544999999625, positionBreaches=210, pnlBreaches=88851, dealsProcessed=57177, pricesProcessed=514756}
BTMN : AssetTradePos{symbol=BTMN, pnl=943.8932999996614, assetPos=-1267.0, mtm=-19568.9417, cashPos=20512.83499999966, positionBreaches=33, pnlBreaches=117661, dealsProcessed=57071, pricesProcessed=514291}
AMZN : AssetTradePos{symbol=AMZN, pnl=-557.0849999999355, assetPos=658.0, mtm=10142.214600000001, cashPos=-10699.299599999937, positionBreaches=63, pnlBreaches=114618, dealsProcessed=57485, pricesProcessed=514345}
-----------------------------
Events proecssed:4000000
millis:1814
...
...
portfolio loss gt 10k count -> 792211.0
Portfolio PnL:-917.6476000005273
Deals processed:400346
Prices processed:3599654
Assett positions:
-----------------------------
MSFT : AssetTradePos{symbol=MSFT, pnl=484.68589999993696, assetPos=97.0, mtm=1697.0247000000002, cashPos=-1212.3388000000632, positionBreaches=139, pnlBreaches=13628, dealsProcessed=57046, pricesProcessed=514418}
GOOG : AssetTradePos{symbol=GOOG, pnl=-998.6065999999155, assetPos=-1123.0, mtm=-19610.1629, cashPos=18611.556300000084, positionBreaches=3, pnlBreaches=105711, dealsProcessed=57199, pricesProcessed=514144}
APPL : AssetTradePos{symbol=APPL, pnl=-21.881300000023202, assetPos=203.0, mtm=3405.1017, cashPos=-3426.9830000000234, positionBreaches=169, pnlBreaches=26249, dealsProcessed=57248, pricesProcessed=514183}
ORCL : AssetTradePos{symbol=ORCL, pnl=-421.9756999999504, assetPos=-252.0, mtm=-4400.4996, cashPos=3978.5239000000497, positionBreaches=103, pnlBreaches=97777, dealsProcessed=57120, pricesProcessed=513517}
FORD : AssetTradePos{symbol=FORD, pnl=112.14559999996254, assetPos=-511.0, mtm=-7797.8089, cashPos=7909.9544999999625, positionBreaches=210, pnlBreaches=88851, dealsProcessed=57177, pricesProcessed=514756}
BTMN : AssetTradePos{symbol=BTMN, pnl=943.8932999996614, assetPos=-1267.0, mtm=-19568.9417, cashPos=20512.83499999966, positionBreaches=33, pnlBreaches=117661, dealsProcessed=57071, pricesProcessed=514291}
AMZN : AssetTradePos{symbol=AMZN, pnl=-557.0849999999355, assetPos=658.0, mtm=10142.214600000001, cashPos=-10699.299599999937, positionBreaches=63, pnlBreaches=114618, dealsProcessed=57485, pricesProcessed=514345}
-----------------------------
Events proecssed:4000000
millis:1513
[14.870s][info][gc] Total allocated: 2830 KB
[14.871s][info][gc] Average allocation rate: 19030 KB/sec
Waste hotspots
The table below identifies functions in the processing loop that traditionally create waste and waste avoidance techniques utilized in the example.
| Function | Source of waste | Effect | Avoidance |
|---|---|---|---|
| Read CSV file | Allocate a new String for each row | GC | Read each byte into a flyweight and process in allocation free decoder |
| Data holder for row | Allocate a data instance for each row | GC | Flyweight single data instance |
| Read col values | Allocate an array of Strings for each column | GC | Push chars into a re-usable char buffer |
| Convert value to type | String to type conversions allocate memory | GC | Zero allocation converters CharSequence in place of Strings |
| Push col value to holder | Autoboxing for primitive types allocates memory. | GC | Primitive aware functions push data. Zero allocation |
| Partitioning data processing | Data partitions process in parallel. Tasks allocated to queues | GC / Lock | Single thread processing, no allocation or locks |
| Calculations | Autoboxing, immutable types allocating intermediate instances. State free functions require external state storage and allocation | GC | Generate functions with no autoboxing. Stateful functions zero allocation |
| Gathering summary calc | Push results from partition threads onto queue. Requires allocation and synchronization | GC / Lock | Single thread processing, no allocation or locks |
Waste reduction solutions
The code that implements the event processing is generated using Fluxtion. Generating a solution allows for a zero cost abstraction approach where the compiled solution has a minimum of overhead. The programmer describes the desired behaviour and at build time an optimised solution is generated that meets the requirements. For this example the generated code can be viewed here.
The maven pom contains a profile for rebuilding the generated files using the Fluxtion maven plugin executed with the following command:
mvn -Pfluxtion install
File reading
Data is extracted from the input file as a series of CharEvents, and published to the csv type marshaller. Each character is individually read from the file and pushed into a CharEvent. As the same CharEvent instance is re-used no memory is allocated after initialisation. The logic for streaming CharEvents is located in the CharStreamer class. The whole 96 MB file can be read with almost zero memory allocated on the heap by the application.
CSV processing
Adding a @CsvMarshaller to a javabean notifies Fluxtion to generate a csv parser at build time. Fluxtion scans application classes for the @CsvMarshaller annotation and generates marshallers as part of the build process. For an example see AssetPrice.java which results in the generation of AssetPriceCsvDecoder0. The decoder processes CharEvents and marshalls the row data into a target instance.
The generated CSV parsers employ the strategies outlined in the table above avoiding any unnecessary memory allocation and re-using object instances for each row processed:
- A single re-usable instance of a character buffers stores the row characters
- A flyweight re-usable instance is the target for marshalled column data
- Conversions are performed directly from a CharSequence into target types without intermediate object creation.
- If CharSequence’s are used in the target instance then no Strings are created, a flyweight Charsequence is used.
For an example of waste free char to target field conversion see the upateTarget() method in a AssetPriceCsvDecoder:
Calculations
This builder describes the asset calculation using the Fluxtion streaming api. The declarative form is similar to the Java stream api, but builds real time event processing graphs. Methods marked with the annotation
@SepBuilder are invoked by the maven plugin to generate a static event processor. The code below describes the calculations for an asset, see
FluxtionBuilder:
@SepBuilder(name = "SymbolTradeMonitor",
packageName = "com.fluxtion.examples.tradingmonitor.generated.symbol",
outputDir = "src/main/java",
cleanOutputDir = true
)
public void buildAssetAnalyser(SEPConfig cfg) {
//entry points subsrcibe to events
Wrapper<Deal> deals = select(Deal.class);
Wrapper<AssetPrice> prices = select(AssetPrice.class);
//result collector, and republish as an event source
AssetTradePos results = cfg.addPublicNode(new AssetTradePos(), "assetTradePos");
eventSource(results);
//calculate derived values
Wrapper<Number> cashPosition = deals
.map(multiply(), Deal::getSize, Deal::getPrice)
.map(multiply(), -1)
.map(cumSum());
Wrapper<Number> pos = deals.map(cumSum(), Deal::getSize);
Wrapper<Number> mtm = pos.map(multiply(), arg(prices, AssetPrice::getPrice));
Wrapper<Number> pnl = add(mtm, cashPosition);
//collect into results
cashPosition.push(results::setCashPos);
pos.push(results::setAssetPos);
mtm.push(results::setMtm);
pnl.push(results::setPnl);
deals.map(count()).push(results::setDealsProcessed);
prices.map(count()).push(results::setPricesProcessed);
//add some rules - only fires on first breach
pnl.filter(lt(-200))
.notifyOnChange(true)
.map(count())
.push(results::setPnlBreaches);
pos.filter(outsideBand(-200, 200))
.notifyOnChange(true)
.map(count())
.push(results::setPositionBreaches);
//human readable names to nodes in generated code - not required
deals.id("deals");
prices.id("prices");
cashPosition.id("cashPos");
pos.id("assetPos");
mtm.id("mtm");
pnl.id("pnl");
}
The functional description is converted into an efficient imperative form for execution. A generated event processor, SymbolTradeMonitor is the entry point for AssetPrice and Deal events. Generated helper classes are used by the event processor to calculate the aggregates, the helper classes are here.
The processor receives events from the partitioner and invokes helper functions to extract data and call calculation functions, storing aggregate results in nodes. Aggregate values are pushed into fields of the results instance, AssetTradePos. No intermediate objects are created, any primitive calculation is handled without auto-boxing. Calculation nodes reference data from parent instances, no data objects are moved around the graph during execution. Once the graph is initialised there are no memory allocations when an event is processed.
An image representing the processing graph for an asset calculation is generated at the same time as the code, seen below:

A similar set of calculations is described for the portfolio in the FluxtionBuilderbuilder class buildPortfolioAnalyser method, generating a PortfolioTradeMonitor event handler. The AssetTradePos is published from a SymbolTradeMonitor to the PortfolioTradeMonitor. The genertated files for the portfolio calculations are located here.
Partitioning and gathering
All calculations, partitioning and gathering operations happen in the same single thread, no locks are required. Immutable objects are not required as there are no concurrency issues to handle. The marshalled events have an isolated private scope, allowing safe re-use of instances as the generated event processors control the lifecycle of the instances during event processing.
System data flow
The diagram below shows the complete data flow for the system from bytes on a disk to the published summary report. The purple boxes are generated as part of the build, blue boxes are re-usable classes.
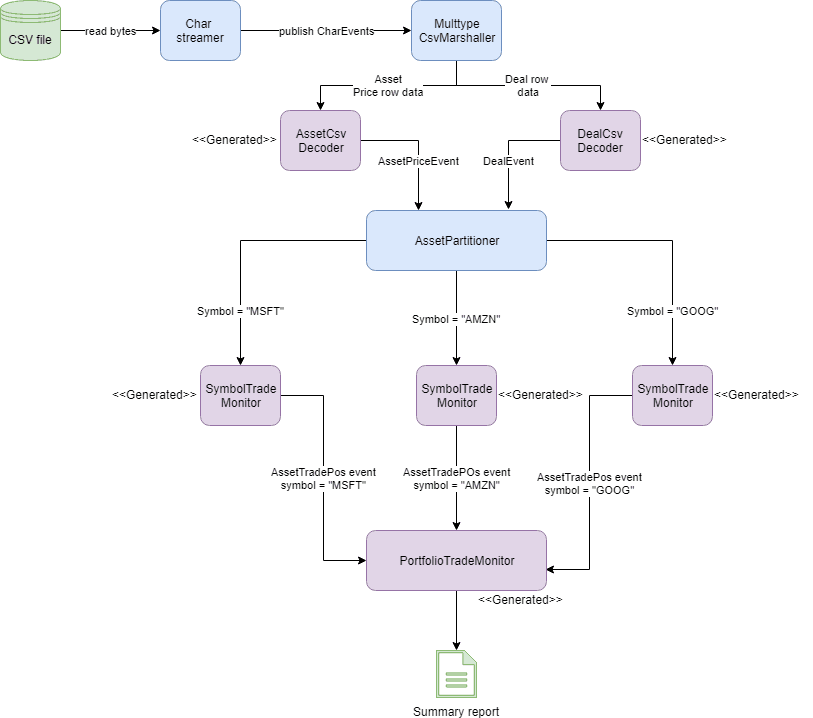
Conclusion
In this article I have shown it is possible to solve a complex event handling problem in java with almost no waste. High level functions were utilised in a declarative/functional approach to describe desired behaviour and the generated event processors meet the requirements of the description. A simple annotation triggered marshaller generation. The generated code is simple imperative code that the JIT can optimise easily. No unnecessary memory allocations are made, and instances are re-used as much as possible.
Following this approach high performance solutions with low resource consumption are within the grasp of the average programmer. Traditionally only specialist engineers with many years of experience could achieve these results.
Although novel in Java this approach is familiar in other languages, commonly known as zero cost abstraction.
With today’s cloud based computing environments resources are charged per unit consumed. Any solution that saves energy will also have a positive benefit on the bottom line of the company.
Published on Java Code Geeks with permission by Greg Higgins, partner at our JCG program. See the original article here: Waste free coding Opinions expressed by Java Code Geeks contributors are their own. |
