Eleven Patterns, Problems & Solutions related to Microservices and in particular Distributed Architectures
The wish to fulfil certain system quality attributes lead us to choose microservice architectures, which by their very nature are distributed, meaning that calls between the services are effectively calls to remote processes. Even without considering microservices, we distribute software in order to meet scalability and availabilty requirements, which also causes calls to be remote. By choosing to support such quality attributes, we automatically trade off others, typically data consistency (and isolation), because of CAP theorem. In order to attempt to compensate for that, so that data eventually becomes consistent, we introduce mechanisms to retry remote calls in cases where they fail, for example using the transactional outbox pattern (based either on CDC to tail changes to the command table, or building a polling mechanism such as here). This in turn forces us to make our interfaces idempotent, so that duplicate calls do not result in unwanted side effects. Retry mechanisms can also cause problems related to the ordering of calls, for example if the basis for a call has changed, because while the system was waiting to recover before retrying the call again, another call from a different context was successful. Ordering problems might also occur simply because we add concurrency to the system to improve performance. Data replication is another mechanism that we might choose in order to increase availability or performance, so that the microservice in hand does not need to make a call downstream, and that downstream service does not even need to be online at the same time. Replication can however also be problematic, if changes to the master have not yet been replicated. Replication, ordering and idempotency all have an effect on system complexity, clarity, reproducibility and our ability to undertand and reason about what is happening, or indeed did happen. Mostly, the effect of eventual consistency on isolation is not even addressed in microservice landscapes. At the end of this article, I have created a diagram which sums up these dependencies.
As you can see, there are a number of technical challenges that are introduced, just because a system is distributed. I recently undertook some self-study training and built “The Milk Factory” which is an attempt at building a event driven microservice architecture based on MVC across the entire landscape, that is, in backend services too. I did this because I wanted to explore the effects of an Event Driven Architecture (EDA) as well their reactive nature. In theory they are more loosely coupled, for example from a temporal point of view, in that the microservices do not all need to be online at the same time as is the case with a hierarchy of services communicating with synchronous HTTP calls. Not only does the asynchronous nature of an EDA improve availability, but it also has a positive effect in regard to back pressure, because a service that is already struggling with load will only fetch more work from the message infrastructure when it has the capacity to deal with it, rather than being bombarded with requests e.g. via HTTP, from upstream services that have no idea that it is struggling to cope with the load. While an EDA is often cited as also being more scalable, the question is, with regard to what? I do not address this point further, because HTTP based solutions built on cloud services like Kubernetes also scale well.
A Quick Note on MVC and Event Driven Architectures
In 2008 I wrote a blog article in which I posted the following picture:
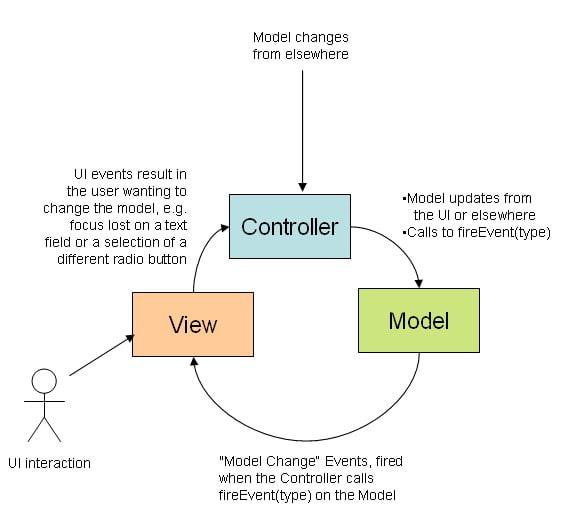
Note the clockwise nature of the arrows which is paramount to making MVC work well. Facebook came up with Flux a few years later which “is a system architecture that promotes single directional data flow through an application” [1]. While out running one day I came up with the idea of how to apply such a pattern to the entire landscape:
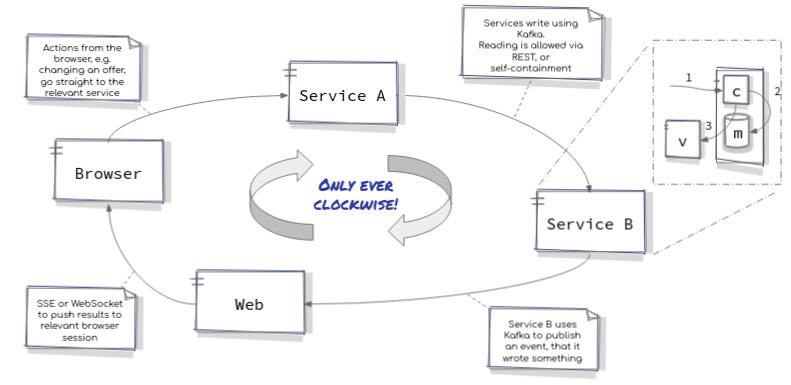
The Milk Factory Architectural Concept
The diagram above was the basis for my architecture and over the course of several months I developed a small set of Quarkus based microservices to implement a number of business processes around the sale and billing of contracts for ordering bespoke milkshakes. Consider the following diagram which shows the process used by The Milk Factory to create or modify an offer.
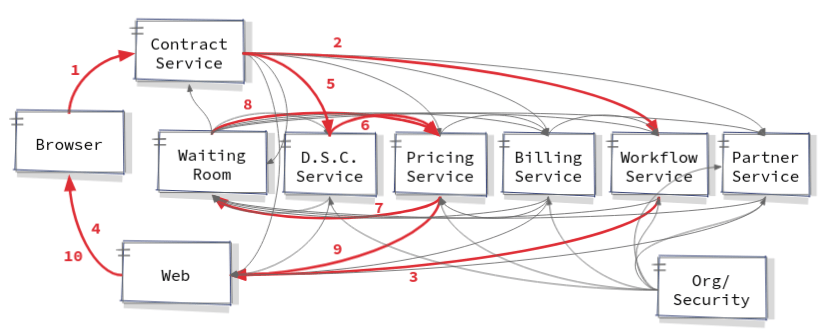
The first step is to send a request from the browser to the backend, implemented using an HTTP call (1). The contract service is responsible for the contract and it’s contents, so called “components” which are modelled as a tree containing the recipe for the milkshake, but also it’s packaging. Each component, say the milk, can have a configuration containing attributes like the fat content of the milk. The components and their configurations can then be referenced by rules in other microservices like the pricing microservice which will contain the rules used to provide a price for each component. The sum of a component’s children makes its base price, which can be affected by rules too. Ultimately the root component contains the total price for the contract. The contract microservice deals with the request made by browser, updates its state in the database, and produces messages in Kafka which downstream microservices can consume. These can either be in the form of commands or events. A command is typically sent from one microservice to another, to get some explicit work done by the receiver, for example to create a human task in the workflow system. An event is typically a simple message to the landscape, that something has happened, for example that the price of an offer was calculated. Microservices may choose to react to such events and may then produce further commands and/or events.
The next step (2) is an example of a command message, where the business logic in the contract service decides that a human task needs to be created, for example to do a background check on a potential customer. This command is consumed and processed by the workflow service which produces an event (3). This event is consumed by the “web” service which is a backend microservice, whose responsibility is to send the events that it receives to the relevant browsers (4). It does this using SSE in lieu of a WebSocket, because often SSE fulfils security requirements better than the latter. In order to be able to send messages to the correct browser instance, a session ID is propagated throughout the landscape with all the messages sent over Kafka or indeed HTTP (in both cases as a header). Individual browsers start a session with that backend service, some time before they make requests to other microservices. Note that this web backend service can be scaled, as long as individual instances subscribe to all Kafka partitions using a unique group ID, so that it does not matter to which instance a specific browser is attached.
At the same time as creating the command to create a human task, the contract service also produces an event to say that it has created or modified a contract (5). Although not shown explicitly on the diagram, this event is also sent to the browser, which can start to render the contract and its components. The DSC service handles discounts, surcharges and conditions and contains business rules which decide if a discount or surcharge applies and it attaches conditions as required. It consumes contract events (5) and publishes an event after persisting its data (6). This event is also sent to the browser, although not shown directly on the diagram, so that the browser can append such information to the rendered contract.
The pricing service consumes messages from the DSC service (6) and together with the contract data that was passed on in that same event, it is able to calculate the price of the contract. If say a technical exception were to occur, this could result in the service sending the original message to a “waiting room” service (7) which will forward the message back to the pricing service a short time later, so that it can be retried (8). Assuming the technical problem has been resolved, the pricing service can then recalculate the prices and publish them (9). These too make their way to the browser (10), which can now complete the rendering process by attaching a price and say VAT information to the offer. The user can now continue to modify the offer, or indeed choose to accept it and complete the sale.
Note that all attempts to write data are done using Kafka as the transport mechanism, rather than HTTP, except for the very first one from the browser. This is a design choice made primarily so that downstream services are not unknowingly bombarded with HTTP calls, but also so that the retry mechanism described above can be employed by all services, rather than just an orchestrator at the top of the call hierarchy.
While implementing The Milk Factory, I encountered a number of challenges, which are now listed together with potential solutions.
1. Synchronous albeit Asynchronous
Having a synchronous flow of calls makes the path through the landscape easier to understand, reflect upon and reason about. The term “synchonous” also makes us think of a coordinated and deterministic sequence of steps. This can be achieved by blocking the user from doing more than one thing at a time and waiting for all the relevant responses to arrive back at the browser before letting them continue to work. More precisely, we block the user from doing more than one action at a time (e.g. changing the configuration of a component in the contract), but we let events flow back to the browser as they happen, updating the relevant part of the screen accordingly (e.g. the changes to the contract details; discounts/conditions changed by business rules; prices; a list of human tasks). By updating the screen as events occur, the user is not blocked from viewing the contract until everything is ready, and this allows them to visualise and process the data as early as possible. But at the same time, we don’t want the user to start another action, before the model has become globally consistent.
2. Maintaining Order
When building an event driven architeture, it is necessary to design the queues / topics over which messages will flow. One option is to have a Kafka topic per microservice and type of data it publishes, for example a topic for discounts and surcharges, and a second topic for conditions, although these data are all published by the DSC component. Another option is to create a single Kafka topic for a whole group of related data. I chose to allow the contract, DSC and pricing services to use the same topic, and by using the contract ID as the Kafka record key, this ensures that the order of the records is maintained for a given contract. The browser will never receive pricing data before it receives the contract or discount data to which the price belongs. The same is true for data related to billing, partners, workflow (human tasks), etc.
By making the order in which records arrive determinstic, we reduce the system complexity and make it easier to reason about what is happening. The trade off that we need to make is that of concurrency and the ability to retry in the case of failure. We cannot have a deterministic order, and have two services process data related to one contract at the same time – in the case of The Milk Factory, this is OK because we need to let the DSC service run its business rules before we can calculate prices. The functional dependencies coming from business requirements automatically limit the amount of concurrency we can add to the system. We also cannot have a deterministic order, if we allow a retry mechanism to send data to “the back of the queue” in order for it to be attempted later.
As an alternative we could block all messages after the current failing one, until it can be processed, perhaps under the assumption that if the current message cannot be processed due to technical difficulties, then none of the others will be able to be processed either. But is it correct to block all other attempts, even those from other users related to other contracts, and effectively block all users and torpedo the system availability? Not if you choose availability over consistency, which is one of the reasons to distribute the services.
Ordering rears its ugly head in other circumstances too. Imaging a billing system that needs up to date partner and contract data in order to send a bill. If while designing the system we made the assumption that the partner data will be available before we process a contract, but the ordering is not guaranteed because e.g. different topics are used to transport the data, the billing system will end up in an erroneous state if partner data is missing. It can get even worse, e.g. the partner data is stale because an up to date address has not yet been received at the time that a contract message arrives. By guaranteeing the order, and guaranteeing that partner data will be received before contract data, we have less problems to solve and the system is simpler.
More information is available here and here.
3. Error Propagation back to the Source
When using synchronous HTTP, errors are propagated back to the original caller, even over a hierarchy of remote calls (modern Java EE / Microprofile Libraries map HTTP error codes into exceptions and vice versa). This may lead to an inconsistent state from a global perspective, but the important point is that the source of the original call receives an error and if a user is involved, they are informed. An event based architecture should not behave differently. Traditionally message based systems dump messages that cannot be successfully processed into a dead letter queue / topic, but this only puts the problem on hold until an administrator gets involved. In The Milk Factory any errors are sent to a special Kafka topic named “errors”, but this topic is subscribed to by the service which is connected to the browsers with SSE, and so the error can be propagated back to the correct browser and user, by means of the session ID (see above). The user experience is no different than when an error occurs during synchronous HTTP. Problems related to global inconsistencies need to be solved anyway, in distributed landscapes, and suitable mechanisms are listed below.
4. Timeouts and Time-to-Live (TTL)
If the response to a synchronous HTTP call takes too long, a timeout typically occurs, and depending upon whether the problem is handled locally or not, local transactions may be rolled back and the error returned to the client. Things get a little more complex, when a service which is supposed to process an event is unavailable, but the message has been uploaded to the message server. In a system which processes everything in the background, this is not necessarily a problem, as it probably doesn’t matter if the message is processed immediately, or in 5 hours (or perhaps even 5 days). In a system where an end user is waiting for something to happen, they are likely to start to retry their action and if they are still blocked, they will probably move on to do something that uses different processes. What should the system then do, when the service that was down becomes online and is able to process the messages? It is probably best to let it do that because this way, global data consistency can be achieved. There are however cases where it is not worth processing these messages or where doing so it more likely to lead to errors, because the chances are that other processes have already influenced the data upon which the current message is dependent. It can be worth adding a time-to-live header to messages, after which they are simply disposed. Note that optimistic locking strategies like JPA’s version column can help to ensure that the processing of messages which no longer match the underlying data are handled correctly, rather than simply letting the last message that is written “win” over all previous writes. Unfortunately, this topic is too complex to have a standard simple solution, and it really depends on your system and the data and processes being used and implemented, as to what the best solution is. Time-to-live mechanisms are still a handy tool in some cases.
5. Dependency Leaks and Encapsulation
Should a service be given all the data it depends on, to do it’s processing, or should it be given the freedom to go and fetch this data from downstream services on which it then depends? This question is related to the tell don’t ask problem, but also depends on your domain, the size of your microservices and non-functional requirements related to performance and resilience.
Imagine that a service has already called a couple of other services and as such already has access to data, or at least it could have, if those services return it during those calls. You might be tempted to pass that data on to a third service if it depends on it, because this will save remote calls from the third service to the others, improving performance and resilience but also saving you having to write adapters in the third service in order to call the others, as well as perhaps cumbersome consumer driven contract tests.
Now imagine a domain in which you are selling products, and some process steps are product specific. If you had made the above optimisations, you will now be asking yourself which data is necessary to provide to the third service. It’s dependencies start to leak out to the orchestrator which needs this knowledge. You might just have to provide all possible data, just in case the third service needs it, for example causing you to provide data relating to car insurance bonus protection, even though the product being sold is house insurance which doesn’t support a bonus system. It would actually be nice if the API could document and enforce what data must be provided, but as soon as it becomes product specific or as soon as it depends on other data, this becomes impossible without providing a specific interface, which too is a form of dependency leaking. So you may choose to trade off the performance, resilience and maintenance wins against the dependency loss.
The problem can become more complex when building an event driven architecture. If you choose to let services fetch data, do you want to allow them to do that with HTTP, or do you want to enforce all communication via messaging, so that you don’t unknowingly bombard services (see above)? I relaxed this design constraint in The Milk Factory and allowed HTTP for reading data, because using messaging to read data is overly complicated – you need to send commands out, receive events as responses, store the pending request somewhere and join all the responses to that request as they come in. Using HTTP to read is much simpler, and if a read fails, we just use retry mechanisms that we need to implement anyway (see below). Nonetheless, I still sent all of the data from the contract service to the DSC service, and both those sets of data to the pricing service (inside the DSC event), in order to reduce the number of fetches that are required. Every reduction in remote communication, reduces the number of places that errors can occur. One downside of sending all of a services data on to others, is that it appears to increase the coupling, because now all attributes are available to downstream services. This may not actually be the case if they do not use all that data, but you don’t easily know what fields are being used unless you have an overview of the entire landscape, so while initially the downstream service may only use a few, it’s free to start using more. You could also reverse this situation and only publish attributes which you know are used (or might be used, depending on say which product is being sold). That way, the coupling is kept to a minimum, but requires exposing further fields, as new requirements with more dependencies are implemented. The term “shared data model” has been used by colleagues to describe exposing data from one service to many, and been criticised for increasing coupling. While a common database for the landscape, as may have been the case in the 80-90s, is definitely such a shared model and bad, I would consider using a shared model with events, within the bounds of a well defined set of services which are closely coupled anyway.
6. Repair Processes
The moment that you build a distributed system without a global transaction manager, you can have the problem of inconsistent data, for example because two of three services have written their data, but the third cannot, regardless of whether for technical or functional (business) reasons. So the question arises of how the user can get his entities out of this inconsistent state? Typically you end up having to bulid process steps into the system, or explicitly allow for inconsistent erroneous states in the system. These mechanisms introduce extra complexity compared to a monolith.
Typically you will need to allow the user to fetch the entire state from all the microservices, and use validation to indicate to them which problems exist. They will then need to be able to carry out specific actions in order to make corrections. None of this may relate to the actual functional use cases, but is required to get from a globally inconsistent state back to a consistent and usable one, so that the user can continue and complete the process they have started.
In some situations, you may also consider building a self-healing mechanism into the system. Imagine a sales system like The Milk Factory where a user attempted to add a manual discount, which worked, but the pricing service failed to recalculate the latest price. You could build the system to recognise that the prices are not up to date (see below), and recalculate them, when the user reloads the offer. If the pricing failed due to a business exception, the error can then be displayed to the user, which might for example hint that they first need to set a specific attribute to a valid value, for the discount to become usable. When the user does this, not only is the new value for the attribute saved, but the system can then recalculate the prices without running into the business exception.
7. Prevention of further Process Steps
The time it takes for a number of nodes in a distributed system to become consistent is known as the convergence time. We speak about the time it takes for the nodes to converge. It can be very useful to block the user from executing further process steps while we wait for the system to converge and a globally consistent state to be reached. Imagine not blocking the user, and allowing them to send the customer an offer, before the latest price has been calculated. If there is no guarantee that the action to send the offer will not be processed after all events used to update the price, it is entirely possible that an offer will be sent to the user with the wrong price.
In The Milk Factory, the UI disables buttons once a process step is started, so that the user cannot start a second process step, without the first one being completed. For example, the offer cannot be sent to the customer, if the system is still updating the configuration of a milkshake contract.
This can become related to timeouts and time-to-live (see above), because we are blocking the user, and at some point, if a microservice is no longer responding, we will want to allow the user to continue doing something else. Note that at no time is the user blocked from leaving the current process, and for example searching for a different customer or contract, in order to do some work elsewhere. But what happens if the user leaves the current process because they cannot move forward, and then they return to the current sales case? How can the system know that the process step that the user wants to execute will be based on a consistent state and should be allowed? The next section describes the solution.
Note that blocking the user is precisely the kind of locking which occurs in distributed systems with ACID properties where a global transaction manager implementing say two phase commit is used, and is precisely the problem most often cited when convincing you that it is bad, and that you should build an eventually consistent system. On the one hand they are right, and if you find yourself building mechanisms like those described here, you might have a problem. On the otherhand, it is sometimes functionally necessary to build such mechanisms, because the business requirements demand it. Sending the customer an offer with the wrong price may not be acceptable. It does however get interesting when you start to ask the question, “why is it not acceptable”? If the price is too low, the customer won’t complain. They may however not quite trust your IT systems. In more complex systems, you can even argue that the customer may never know that the price offered is wrong. But watch out, if the price is recalculated while booking the contract or during the billing process, you might well end up with unhappy customers because the price they have to pay is not the price they were quoted.
8. Consistency Mechanisms
The Milk Factory uses a timestamp called the “sync timetamp” to allow it to work out if all parts of a contract are synchronized and the data is globally consistent. The timestamp is chosen by the contract service which acts as an orchestrator for all process steps relating to the creation and alteration of contract offers. It is propagated to all microservices within the contract domain, and persisted by them during each process step, even if the microservice doesn’t need to actually update its own business data in that process step. By comparing the timestamp across all services, we can ensure that the data is consistent. If we update for example a contract condition in the DSC service, we also update the sync timestamp in the contract and pricing services, even though this has no effect on the data held in the contract service, and might not affect the price.
This mechanism reduces the performance of the system, as well as reducing the resilience, because a simple alteration requires data processing from all microservices. At the same time, it allows us to guarantee that the offer is consistent before sending it to the customer, or booking it when the customer accepts it. This is a trade off, and one made, because global data consistency in particular financial data are more important at The Milk Factory, than performance and resilience. This is a business decision at the end of the day.
9. Isolation and Visibility of Partially Consistent Data
Should data that is not yet globally consistent, be visible to other technical components and processes? Should a user viewing a customer’s contract summaries, see an old price next to an updated payment frequency, where the surcharge for monthly billing has not yet been reflected in the price? Probably not, if they are going to confirm the price to the customer. Should a user viewing rooms in a hotel see that the room count has been reduced, even though the flight bookings are not yet confirmed? Almost definitely. So it really depends on the use cases and what the business’ requirements are.
Isolation is probably the hardest of the four ACID properties to get right in a distributed system. You can add mechanisms to the system, in an attempt to get isolation problems resolved, but they often lead to resource locking. There is a well known pattern called “try-confirm-cancel“, not too unrelated to two phase commit (2PC), whereby an orchestrating service tries to get work done by downstream services, and then either confirms that work, or cancels it, depending upon whether or not all tries were successful or not. Just like 2PC, if the system is not going to make tried changes visible to other processes, it effectively locks the related resources (data) until the confirmation or cancellation is executed. These locks are the same as those described above, which are typically slated as the reasons to move from an ACID based system to an eventually consistent one, in order to increase resilience, performance, availability, etc.
10. Automated Retry Mechanisms
In cases where technical errors lead to failure, it can be good to build automatic retries into the system. Netflix famously introduced Hysterix to address fault tolerance and the Microprofile now defines standard mechanisms for dealing with faults. This is one way to make the system self-healing (another is to build algorithms for detecting inconsistencies and then fixing them – something we do at my current customer’s site to compensate for an old AS400 system which allows users to persist wrong contract data).
In 2018 I published an article in which I described a mechanism for saving “commands” in a technical table, next to your business data, within the same transaction. This ensures that global data eventually becomes consistent, by ensuring that those commands are executed, and are retried until they succeed. I have also implemented an event sending mechanism which builds upon that, to guarantee that events are sent out into the landscape, if, and only if, the your microservice’s data is persisted. This mechanism is now known as the polling publisher pattern, an implementation of the transactional outbox pattern.
Combined with Kafka, this ensures that messages are sent to Kafka, but does not ensure that they are successfully processed on the consumer side. If an error happens during message consumption, you need to think about what to do with that incoming message. If you send it to a dead letter topic, what happens then? If you throw it away, you will certainly never be globally consistent.
The Milk Factory has a service called the waiting room, which I implemented after reading this article while searching for solutions on how to retry the consumption of a message after a technical failure downstream of the consumer, e.g. a database outage. It basically sends messages to a special topic if a technical error is encountered (determined by certain standard Java exceptions). The waiting room service sends the messages back to the component that just had the technical problem, in order to be retried. A retry count is propagated with the message and incremented accordingly and can be used to implement a backoff strategy in order to reduce the load on a service that is currently struggling. Note how a library is used in the business services, to encapsulate this technical solution, in order to separate business and technical concerns.
This works well, but introduces a further complexity into the system, namely the loss of ordering (see above). Automatic retries also require services to behave idempotently (see below).
11. Idempotency
Due to retry mechanisms, services need to behave idempotently, which here is used to mean that there should be no unexpected side effects due to processing a message multiple times. For example, if a technical error leads to a message about a discount being retried, a second and subsequent attempt to process the message should not result in the same discount being added to a contract multiple times, if the user only wanted it to be added once.
Idempotentcy in microservices is typically implemented by having the client generate a request ID for the current action which is propagated throughout the landscape with the instruction (command) to do something. Each time that command is processed, a service can check if it has already processed the request ID, and if it has, it should respond as though it has just successfully processed it for the first time. In an event driven architecture this will typically mean publishing relevant events, potentially multiple times, which drives the requirement for idempotent services even more, so that downstream services also cause no side effects. Note that you can use a unique database constraint and always attempt to process the event, without having to first check if it already has been processed (a performance gain). But in a Java EE container, the transaction will then be marked for rollback, and the container might write a log entry at say warn level, which is not actually something you want to be warned about, as it is “normal” in idempotent services and no administrator action is required. Note also that while checking the database for the request ID before writing might appear to work, it is not guaranteed to work if two instances of the microservice are concurrently processing the command for whatever reason – so the use of a unique constraint is more precise.
Sometimes you can avoid mechanisms like this request ID, if for example the commands are absolute. For example “add discount code XA1 to the offer“, combined with an implementation that only allows discount codes to exist zero or one time per offer. If the service always deletes the given codes before inserting them, within the same database transaction, then they will never exist more than one time, no matter how often the command is processed. Note again how there is a trade off made, this time between performance (deleting before inserting) and having to implement idempotency.
Why multiple Services?
This is a side note rather than a pattern. Consider The Milk Factory and how you could choose to put the price calculation algorithm into the same microservice as the contract details (and let’s ignore discounts, surcharges and contract conditions for the moment). That would have the awesome effect of ensuring that the price is always consistent with the contract details! Now let’s consider the recurring billing process which takes place periodically. Prices can change if they depend on say markets, or say discounts that themselves depend on the customer’s age or time. If the billing process needs to also recalculate prices, you end up with a dependency from the billing service to the contract service (which now includes pricing), and end up with a new discussion, namely can you not lump those two services together? Sure you can, but be aware that you are moving in the direction of a monolith and sticking concerns together that might be better left apart, especially when you think about all the other things that also influence microservice sizing and design. In The Milk Factory the pricing functionality is a common denominator of multiple processes and as such, is outsourced into its own microservice.
Help with Service Dependencies
This is not a pattern, but a very useful design technique, given to me by a wise colleague. Draw a matrix on a piece of paper and start to put your microservices on it. Draw the dependencies between services as arrows from one service requiring something, to another which provides that something. Arrows are only allowed to go from left to right, and from top to bottom. This means that you will need to start moving the services around in order to not break those rules. If you have arrows pointing from right to left, or bottom to top, then those dependencies are illegal and need to be resolved. That can be done by either cutting relevant parts of microservices out into separate components, or joining two services into a single service (although theoretically the same exercise should be repeated for package/class dependency within each service).
Conclusions
The following diagram shows how the non-functional requirements, quality attributes, the mechanisms listed above and side-effects are related to each other.
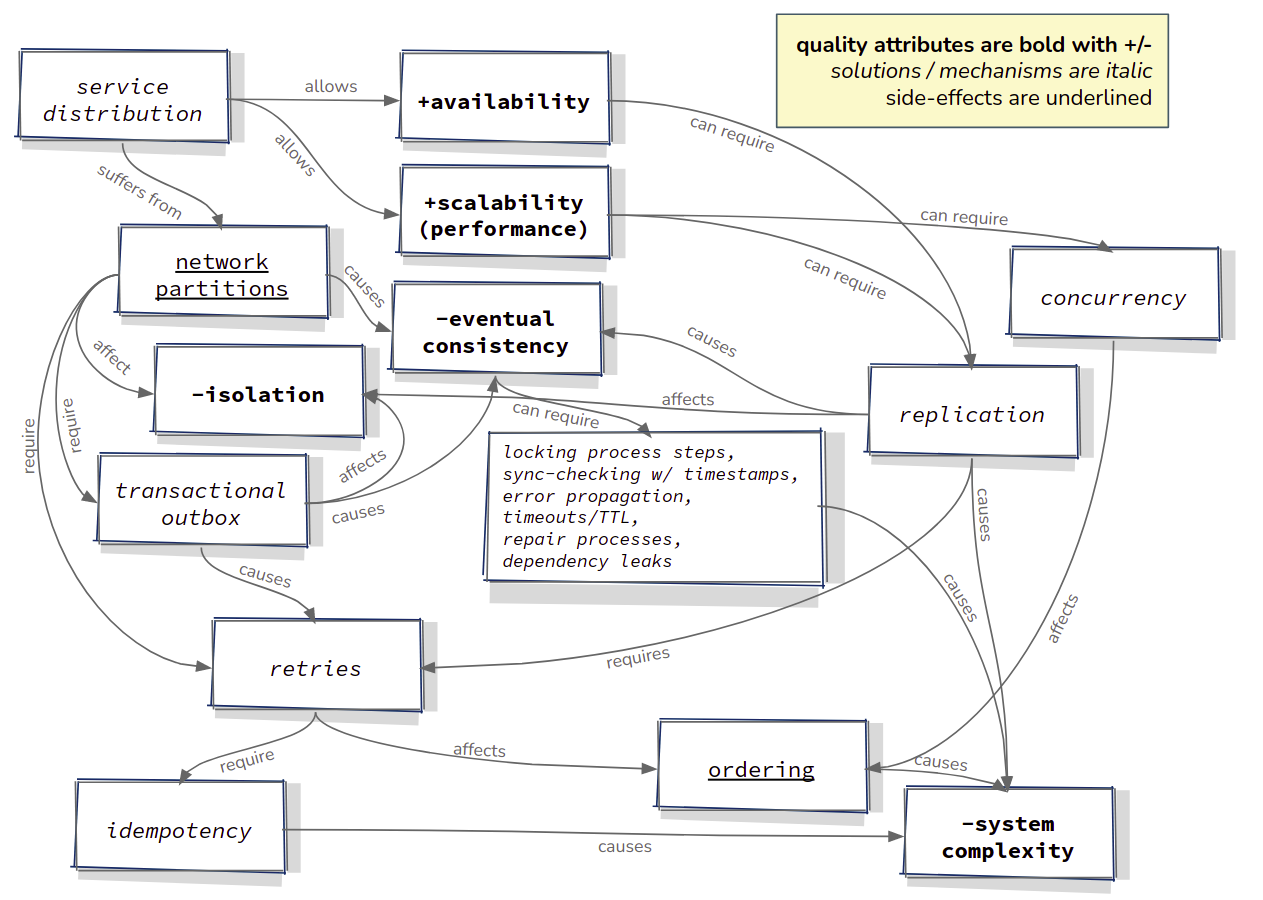
All of the patterns discussed above, their problems and solutions, and the trade offs that are discussed, are technical in nature. As an developer/architect of software systems that solve complex business problems, I don’t actually want to be faced with these technical issues, but I am forced to do so because of non-functional requirements that cause me to design distributed systems. During the design process we choose how to divide the business problem in to a multitude of (micro-)services. That “cutting” process can have a large effect on the number of points in a landscape where things like those discussed above, can go wrong. By reducing the number of microservices, we can reduce the number of points in the system where things can break. There are many criteria used in choosing how large to make a microservice, and they can be functional, technical or even organisational in nature. I recommend considering the following:
- If a business process step fits into a single microservice, that means that it can have ACID properties.
- Not all process steps will fit into a single microservice, meaning that you will encounter some of the patterns described above.
- A team of around 8 people with up to 5 developers, in a large organisation, should be developing somewhere between one and three microservices (and possibly maintaining one or two more, depending upon how often they change and their complexity).
- Put all of the mechanisms described above, and many more, into your toolbox and use them as required, like skilled craftspeople do with physical tools.
If you have encountered more patterns and/or would like them added, please get in touch by leaving a comment.
Published on Java Code Geeks with permission by Ant Kutschera, partner at our JCG program. See the original article here: Eleven Patterns, Problems & Solutions related to Microservices and in particular Distributed Architectures Opinions expressed by Java Code Geeks contributors are their own. |

I see no pictures or diagrams. I’ve tried in Chrome, Firefox, and Safari on Mac, and Edge on Windows.
Hello Linus,
Yes you were right. The problem has been fixed.
I still cant see them. Try the original: http://blog.maxant.co.uk