Anthos Service Mesh makes it very simple for a service in one cluster to call service in another cluster. Not just calling the service but also doing so securely, with fault tolerance and observability built-in.
This is a fourth in a series of posts on service to service call patterns in Google Cloud.
The first post explored Service to Service call pattern in a GKE runtime using a Kubernetes Service abstraction
The second post explored Service to Service call pattern in a GKE runtime with Anthos Service mesh
The third post explored the call pattern across multiple GKE runtimes with Multi-Cluster Service
Target Call Pattern
There are two services deployed to two different clusters. The “caller” in “cluster1” invokes the “producer” in “cluster2”.
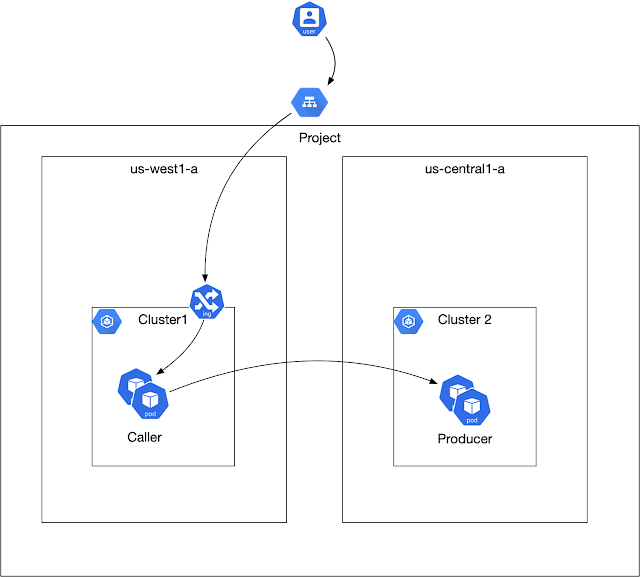
Creating Clusters and Anthos Service Mesh
The entire script to create the cluster is here. The script:
1. Spins up two GKE standard clusters
2. Adds firewall rules to enable ip’s in one cluster to reach the other cluster
3. Installs service mesh on each of the clusters
Caller and Producer Installation
The caller and the producer is deployed using the normal kubernetes deployment descriptors, no additional special resource is required to get the set-up to work, so for eg, the callers deployment looks like this:
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-caller-v1
labels:
app: sample-caller
version: v1
spec:
replicas: 1
selector:
matchLabels:
app: sample-caller
version: v1
template:
metadata:
labels:
app: sample-caller
version: v1
spec:
serviceAccountName: sample-caller-sa
containers:
- name: sample-caller
image: us-docker.pkg.dev/biju-altostrat-demo/docker-repo/sample-caller:latest
ports:
- containerPort: 8080
....Caller to Producer Call
The neat thing with this entire set-up is that from the callers perspective a call continues to be made to the dns name of a service representing the producer. So assuming that the producer’s service is deployed to the same namespace, then a dns name of “producer” should just work.
So with this in place, a call from the caller to producer looks something like this:
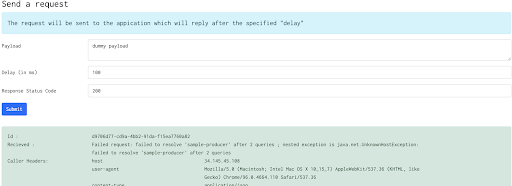
The call fails, with a message that the “sample-producer” host name in cluster1 cannot be resolved. This is perfectly okay as such a service has not been created in cluster1. Creating such a service:
apiVersion: v1
kind: Service
metadata:
name: sample-producer
labels:
app: sample-producer
spec:
ports:
- port: 8080
name: http
selector:
app: sample-producer
resolves the issue and a call cleanly goes through!! This is magical, see how the service in cluster 1 resolves the pods in cluster2!

Additionally the presence of x-forwarded-client-cert header in the producer indicates that the mTLS is being used during the call.
Fault Tolerance
So security via mTLS is accounted for, now I want to layer in some level of fault tolerance. This can be done by ensuring that the calls timeout instead of just hanging, and not making repeated calls to producer if it starts to be non responsive. This is typically done using istio configuration. Since Anthos service mesh is essentially a managed istio, the configuration for timeout looks something like this, using a VirtualService configuration
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: sample-producer-route
namespace: istio-apps
spec:
hosts:
- "sample-producer.istio-apps.svc.cluster.local"
http:
- timeout: 5s
route:
- destination:
host: sample-producer
port:
number: 8080
And circuit breaker, using a Destination Rule which looks like this:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: sample-producer-dl
namespace: istio-apps
spec:
host: sample-producer.istio-apps.svc.cluster.local
trafficPolicy:
tls:
mode: ISTIO_MUTUAL
outlierDetection:
consecutive5xxErrors: 3
interval: 15s
baseEjectionTime: 15s
All of it is just straight kubernetes configuration and it just works across multiple clusters.
Conclusion
The fact that I can treat multiple clusters as if they were a single cluster is I believe the real value proposition of Anthos Service Mesh, all the work around how to enable such a communication securely with fault tolerance is what the Mesh brings to the table.
My repository has all the sample that I have used for the post – https://github.com/bijukunjummen/sample-service-to-service
Published on Java Code Geeks with permission by Biju Kunjummen, partner at our JCG program. See the original article here: Service to Service call pattern – Using Anthos Service Mesh Opinions expressed by Java Code Geeks contributors are their own. |
