Docs as Code
It is the first step to the right direction
The approach to treating your documentation the same way as program code is a step in the right direction, but it is far from state-of-the-art. The practice is detailed on many websites that advocate the use of docs-as-code (DAC). For example the Write the Docs community has a great article on docs-as-code. The article lists
- Issue Trackers
- Version Control (Git)
- Plain Text Markup (Markdown, reStructuredText, Asciidoc)
- Code Reviews
- Automated Tests
as required tools to this approach. Another example is docs-as-code, which is a toolset for documentation maintenance. They write
With docs-as-code, you treat your documentation the same way as your code.
You use…
your IDE to write it
your version control system to store and version it
your test-runner to test it
your build system to build and deploy it”
This is very much the same as the approach of Write the Docs.
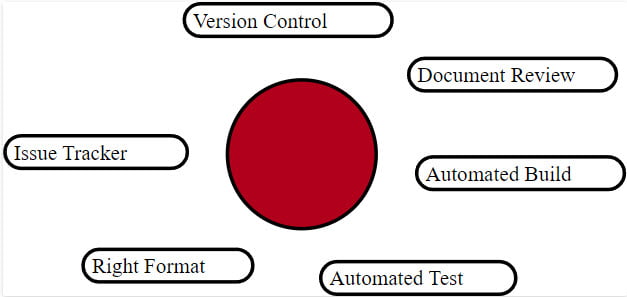
You have to have your documents in a format supported by the DAC tools. Use version control, document review, automated build, issue tracker, and automated tests. It is very much the same approach we use in code development.
Essentially it is a copy of the professional software development process’ coding part. Documentation, however, is not coding. While it is a good idea to reuse some parts of the coding methodology technics, there is more to it.

What docs-as-code Ignores
Coding is a transformation process converting documentation, namely the requirement documentation, into code. The requirement documentation may not be documentation in the classical sense. It may be some note, a list of wishes on a jot of paper. Still, the essence is to convert some human affine into machine affine. Some techniques try to support this process, but most of these techniques die when in production. For example, creating the documentation as UML and making it so precise that the code generation is automatic afterward is not feasible. You could do it in principle, but the cost of the effort is too high. It is cheaper to create the code than documentation that defines the functionality with mathematical precision.
Documenting an application is precisely the opposite direction.
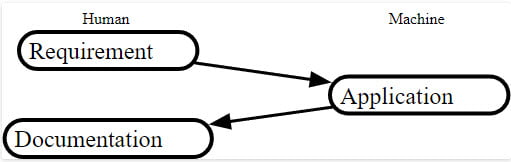
Something that failed in one direction does not necessarily fail when we try to go the other direction. You may not be able to jump from the river to the bridge, but the other way is very much possible.
When creating the program documentation, our source is precisely describing the functionality we want to document. After all, the code is the most precise documentation of the application functionality. We already have the precision, which was not feasible to have for the other way around.
The docs-as-code approach, as described by most articles, ignores it. However, it can be amended, and it should be. We can look at it as the next step in the docs-as-code evolution.
The next step
We can categorize documentation into two categories.
- Explanatory, and
- Reference
Sometimes a document belongs to one of the categories, but documents are a mix of the two most of the time. It may even happen that you cannot even tell if a sentence in a document belongs to one category or the other.
Creating an explanatory style text cannot be automated. It needs human effort to create sentences that are clear and easily understandable. The importance is demonstrated by the lack of them in this article, as you may have noticed.
However, creating the reference text is more or less a mechanical task. The documentarian (a term from write-the-docs) copies the key’s name to explain how to configure the system and writes a sentence around it. Copies some sample code from the unit tests into a code segment into the Asciidoc documentation and adds explanation. The reference is taken from the code verbatim in these examples, and the explanatory part is added.

You can automate the copy of the reference information. Most of the time, it is not automated.
The catch is that automation, just as in the case of tests, is more expensive than doing manual work once. It pays back when the actual operation (copy and paste) happens many times.
And it usually does. To be more precise, it is supposed to happen. However, the documentation maintenance misses the task in practice, and the document becomes stale. It is where the docs-as-code automated test may help. In principle, it is possible to create a test checking the documentation and find discrepancies between the names in the code and the documentation. It can be heuristic, or it can be exact. To do it the exact way, the documentation and/or the code needs meta-information helping the test to perform the consistency check.
Such a test can signal that the documentation may be outdated and need change. For example, it may give a warning, like
“The name of the field XYZ is not the same as in the documentation ZZZ. Change ZZZ in the documentation to XYZ”.
It is a foolish and outrageous error message. I immediately know that the program architecture is messed up when I see such an error message. If the test can tell me what to do with such precision, it could fix the problem with the same effort.
It is much better if we let the automated build copy the actual name instead of checking that the human did it correctly. To do that, the documentarian should put the meta-information into the documentation instead of the copied value. The meta-information is read by the automated build tool, and using that; it copies the actual value or values.
If the value changes, the build process will automatically change it.
Another advantage is the lesser possibility for error. If the documentarian makes a mistake copying the field’s name, the text will not complain. If he writes XXY instead of XYZ, the documentation will contain the wrong name unless some human review process discovers and fixes the bug. If the documentarian inserts the meta information and makes a mistake, the build process will likely fail. If instead of XYZ, I have to write {java:field com.javax0.jamal.api#XYZ} any simple typo will be detected. If there is a field com.javax0.jamal.api#XYZ it is unlikely to have also com.javax0.jamal.api#XXY.

With this approach, the docs-as-code workflow is extended. The documentation’s ” source code ” starts behaving as a source code. The automated build is no longer simply formatting and executing language checks. The goal is to automate everything that you can automate. It may not be cheaper than doing the work manually, but certainly less error-prone.
Tools
All the above theory is pleasant and attractive but worth nothing unless there are tools to implement them. My motivation writing this article is partly to advocate the use of the open-source tool Jamal. Although Jamal is a general-purpose macro language and can be used in many areas, its primary purpose is document maintenance support. It is a simple to write, non-intrusive macro language. Using it, you can insert meta-information into the documentation to be processed by the automated build. You can use it with any plain text document format, like Asciidoc, markdown, apt, etc. The latest releases also support the DOCX format to use it even with Microsoft Word.
The set of the macros is quite extensive, and it is easy to add your own. The documentation support module can gather information from the application’s source code as snippets. Snippets can then be transformed, extracted, and inserted into the documentation. Information from the code can be extracted using text tools using the source code text. However, in the case of Java applications, the document transformation may also collect information using reflection. It can be done because Jamal itself is a Java application.
It can be started on the command line as a maven plugin and a maven extension. It is also embedded as a doclet and a taglet to allow Jamal macros in the JavaDoc documentation.
You can use macros to check the consistency of the documentation and the code. You can mark some part of the code as a snippet, and the documentation related to the specific region may contain the hash code of the piece. When the part changes in the source code, the macro evaluation will automatically signal an error.
The application of Jamal is independent of build automation. It can be antora, jBake, or simply a maven project with different plugins. The application of Jamal is also independent of the documentation format. It can be Asciidoc, markdown, apt, etc., as long as the documentation format is text. Using the Word extension included in the command line version, it can even be Microsoft DOCX Word format.
Conclusion
Treating documentation as source code is a good idea and a good start. It can, and should, however, be extended to include more features. When you treat your documentation as a source code, you should not stop simply using built automation, automated testing, review processes, and versioning. You should also apply techniques like Don’t Repeat Yourself (DRY). Extra tools exist and seamlessly integrate with the already existing build and formatting tools to do that.
Published on Java Code Geeks with permission by Peter Verhas, partner at our JCG program. See the original article here: Docs as Code is not enough Opinions expressed by Java Code Geeks contributors are their own. |
