One aspect of Apache Kafka that makes it superior to other event streaming projects is not its technical features and performance characteristics, but the ecosystem that surrounds it. The number of books, courses, conference talks, Kafka service providers, consultancies, independent professionals, third-party tools and developer libraries that make up the Kafka landscape is unmatched by competing projects.
While this makes Kafka a de facto standard for event streaming and provides assurance that it will be around for a long time to come, at the same time, Kafka alone is just a cog in the wheel and does not solve business problems on its own. This raises the question of which Kafka distributions are best suited to our use cases and which ecosystem will enable the highest productivity for our development teams and organizational constraints. In this post, we will try to navigate the growing ecosystem of Kafka distributions and give you some thoughts on where the industry is heading.
Kafka for Local Development
If you are new to Kafka, you may assume that all you need is a Kafka cluster, and you are done. While this statement might be correct for organizations with a low level of Kafka adoption where Kafka is a generic messaging infrastructure, it does not represent the picture in the organizations with a higher level of event-streaming adoption where Kafka is used heavily by multiple teams in multiple sophisticated scenarios. The latter group needs developer productivity tools that offer rapid feedback during development of event-driven applications, high levels of automation, and repeatability in lower environments, and depending on the business priorities a variety of hybrid deployment mechanisms from edge to multiple clouds in production.
The very first thing a developer team working heavily with stream processing applications would want is being able to start a short-lived Kafka quickly on their laptop. That is true regardless if you practice test-driven development and mock all external dependencies, or a rapid prototyping technique. As a developer, I want to quickly validate that my application is wiring up and functioning properly with an in-memory database or messaging system. Then I want to be able to do repeatable integration testing with a real Kafka broker. Having this rapid feedback cycle enables developers to iterate and deliver features faster and adapt to changing requirements. The good news is that there are a few projects addressing this need. The ones that I’m most familiar with are Quarkus extension for Kafka and EmbeddedKafka from Spring in the Java ecosystem. The easiest way to unit test Kafka applications is with smallrye-messaging that replaces the channel implementation with in-memory connections. This has nothing to do with Kafka, but shows how using the right streaming abstraction libraries can help you unit test applications rapidly. Another option is to start an in-memory Kafka cluster in the same process as the test resource through EmbeddedKafkaCluster to use that for a quick integration test. If you want to start a real Kafka broker as a separate process as part of the resource, Quarkus can do that through Dev Services for Kafka. With this mechanism, Quarkus will start a Kafka cluster in less than a second using containers. This mechanism can validate Kafka-specific aspects of your application and ensure it is working as expected on the local machine. The cool thing about Dev Services is that it can also start a schema registry (such as Apicurio), relational databases, caches, and many other 3rd party service dependencies. Once you are done with the “inner-loop” development step, you want to commit your application to a source control system and run some integration tests on the central build system. You can use Test Containers to start a Kafka broker from a Java DSL (or librdkafka mock for C), and allow you to pick specific Kafka distributions and versions. If your application passes all the gates, it is ready for deployment into a shared environment with other services where a continuously running Kafka cluster is needed.
In this post, we are focusing only on the Kafka broker distributions and not the complete Kafka ecosystem of tools and additional components. There are other monitoring and management tools, and services that help developers and operations teams with their daily activities which we leave for another post.
Self-managed Kafka
Since our application has not reached production or a performance testing environment that requires production-like characteristics, all we want is to have a Kafka installation that is reliable enough for various teams to integrate and run some tests without involving a lot of effort to manage. Another characteristic of such an environment is to be low cost without the cost overhead of data replication and multi-AZ deployment. Many organizations have Kubernetes environments where each development team has their isolated namespace and shared namespaces for CI/CD purposes with all the shared dependencies deployed. Strimzi project – origicnally created by Red Hat has everything needed to automate and operate a Kafka cluster on Kubernetes for development and production purposes. The advantage of using Strimzi for the lower environments is that it can be managed through a declarative Kubernetes API which is used by developers to manage the applications they develop and other 3’rd party dependencies. This allows developers to use the same Kubernetes infrastructure to quickly create a Kafka cluster for individual or team uses, a temporary project cluster, or a longer living shared cluster, repeatedly through automation pipelines and processes w/o going to depend on other teams for approval and provisioning of new services.

Self-managed Kafka clusters are not used only for development purposes, but for production too. Once you get closer to a production environment, the characteristics required from the Kafka deployment change drastically. You want to be able to provision production-like Kafka clusters for application performance testing and DR testing scenarios. A production environment is not usually a single Kafka cluster either, it can be multiple clusters optimized for different purposes. You may want a self-managed Kafka cluster to deploy on your edge clusters that run offline, on-premise infrastructure that may require a non-standard topology or public cloud with a fairly standard multi-AZ deployment. And there are many self-managed Kafka platforms from Red Hat, Confluent, Cloudera, TIBCO, to name a few. The main characteristic of a self-managed cluster is the fact that the responsibility to manage and run the Kafka cluster resides within the organization owning the cluster. With that, a self-managed cluster also allows customization and configuration of the Kafka cluster, bespoke tuning to suit your deployment needs. For these and any other odd use cases that are not possible with Kafka as a Service model, the self-managed Kafka remains a proven path.
Kafka as a Service
Each organization is different, but some of the common criteria for production Kafka clusters are things such as the ability to deploy on multiple AZs, on-demand scaling, compliance and certifications, a predictable cost model, open for 3rd party tools and services integrations, and so forth. Today, Kafka is over a decade old and there are multiple mature Kafka as a Service offerings able to satisfy many production needs. While these offerings vary in sizing options, the richness of the user interface, Kafka ecosystem components, and so forth, a key difference is whether Kafka is treated as an infrastructure component or treated as its own event-streaming category with its event-streaming abstractions.
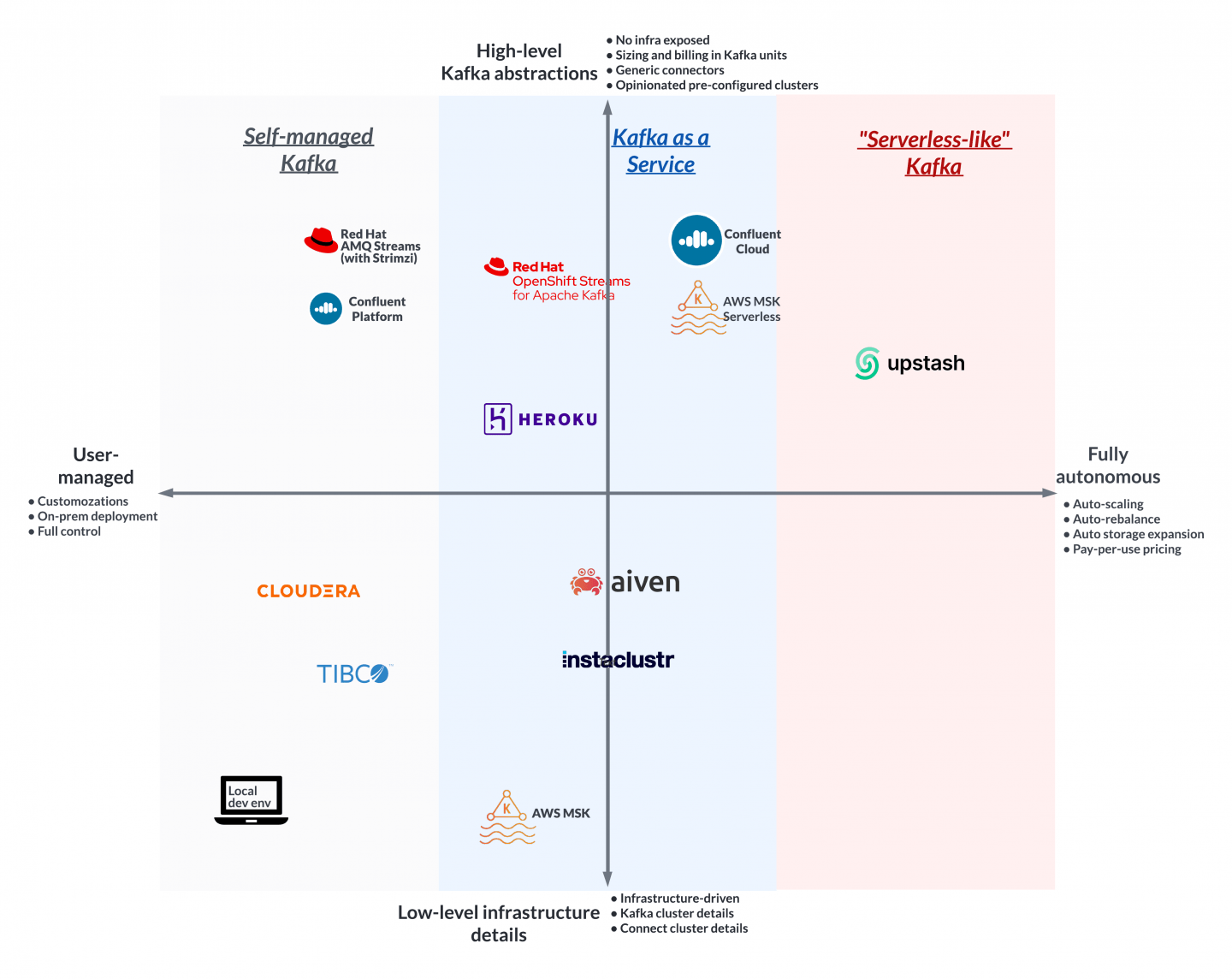
Based on the abstraction criteria we can see that some SaaS providers (such as AWS MSK, Heroku, Instaclustr, Aiven) focus on infrastructure details such as VM sizes, the number of cores and memory, storage types, broker, Zookeeper, Kafka Connect details, and so forth. Many critical decisions about the infra choice, capacity matching to Kafka, Kafka cluster configurations, Zookeeper topology, are left for the user to decide. These services resemble infrastructure services that happen to run Kafka on top, and that is reflected in the VM-based sizing and pricing models. These services have a larger selection of sizing options and can be preferred by teams that have infrastructure inclination and preference to know and control all aspects of a service (even a managed service).
Other Kafka as a Service providers (such as Confluent Cloud, AWS MSK Serverless, Red Hat Openshift Streams for Apache Kafka, Upstash) go the opposite “Kafka-first” direction where the infra, the management layer (typically Kubernetes based), and Kafka cluster details are taken care of, and hidden. With these services, the user is dealing with higher level, Kafka-focused abstractions such as Streaming/Kafka/Topic-like units of measure (which represents normalized multi-dimensional Kafka capacity) rather than infrastructure capacity; availability guarantees instead of deployment topology of brokers and Zookeeper; connectors to external systems as an API (regardless of the implementation technology) instead of Kafka Connect cluster deployment and connector deployments. This approach exposes what is important for a Kafka user and not the underlying infrastructure or implementation choices that make up a Kafka service. In addition, these Kafka-first services offer a consumption based Kafka-centric pricing model where the user pays for Kafka capacity used and quality of service rather than provisioned infrastructure with the additional Kafka margin. These services are more suitable for lines of business teams that focus on their business domain and treat Kafka as a commodity tool to solve the business challenges.
Next, we will see why Kafka-first managed services are blurring the line and getting closer to a serverless-like Kafka experience where the user is interacting with Kafka APIs and everything else is taken care of.
“Serverless-like” Kafka
Serverless technologies are a class of SaaS that have specific characteristics offering additional benefits to users such as a pay-per-use pricing model and eliminating the need for capacity management and scaling altogether. This is achieved through things such as not having to provision and manage servers, built-in high availability, built-in rebalancing, automatic scaling up, and scaling down to zero.
We can look at the “Serverless Kafka” category from two opposing angles. On the positive side, we can say that the “Kafka-first” services are getting pretty close to a serverless user experience except for the pricing aspect. With these Kafka-first services, users don’t have to provision infrastructure, the Kafka clusters are already preconfigured for high availability, with partition rebalancing, storage expansion, and auto-scaling (within certain boundaries).
On the negative side, whether a Kafka service is called serverless or not, these offerings still have significant technical and pricing limitations and they are not mature enough. These services are constrained in terms of message size, partition count, partition limit, network limit, storage limit. These constraints limit the use cases where a so-called serverless Kafka can be used. Other than Upstash which is charging per message, the remaining serverless Kafka services charge for cluster hours which is against the scale-to-zero/pay-per-use ethos of the serverless definition.
That is why today I consider the serverless Kafka category still an inspiration rather than reality. Nevertheless, these trends set the direction where managed Kafka offerings are headed: that is complete infrastructure and deployment abstractions hidden from the user; Kafka-first primitives for capacity, usage, quality of a service; autonomous service lifecycle that doesn’t require any user intervention; and with a true pay-for-what-you-use pricing model.
Summary
How many types of Kafka do you need? The answer is more than one. You want developer frameworks that can emulate Kafka locally and enable rapid, iterative development. You want a declarative and automated way to repeatedly deploy and update development environments. Depending on your business requirements, you may require highly customised Kafka implementations at the edge or standard implementations across multiple clouds that are all connected. While your organization’s event streaming adoption and Kafka maturity grows, you will need more Kafka. But there is a paradox. If you are not in the Kafka business, you should work less on Kafka itself and use Kafka for more tasks that set your business apart. This is possible if you use Kafka through higher-level frameworks like Strimzi that automate many of the operational aspects, or through a Kafka-first service that takes care of low-level decision-making and relieves you of the responsibility of running Kafka. This way, your teams stop thinking about Kafka and start thinking about how to use Kafka for what matters to your customers.
Published on Java Code Geeks with permission by Bilgin Ibryam, partner at our JCG program. See the original article here: Kafka Distributions Landscape Opinions expressed by Java Code Geeks contributors are their own. |

