Today we are taking a look at Spoofax, a Language Workbench, an environment that permits quickly creating DSLs, and in this tutorial, we will show a concrete example of that.
We think that anyone seriously interested in Language Engineering should be familiar with all the main platforms. Some of them could become useful tools in your solution toolbox, while others could give you ideas and inspirations. Spoofax is the current incarnation of work that has been going on for over 30 years at the Technical University of Delft. It is relevant in our opinion because it has been successfully used both in research and in industry.
Today we are going to use Spoofax to build a simple DSL for defining Abstract Syntax Trees. Because you know, this is the kind of thing that is useful for Language Engineers. This DSL is defined below and, as always, you can find code in the companion repository to this article at: https://github.com/Strumenta/spoofax-tutorial
## Our example: A DSL to define ASTs
We will define a simple DSL to define ASTs. This is how one file in our DSL will look like
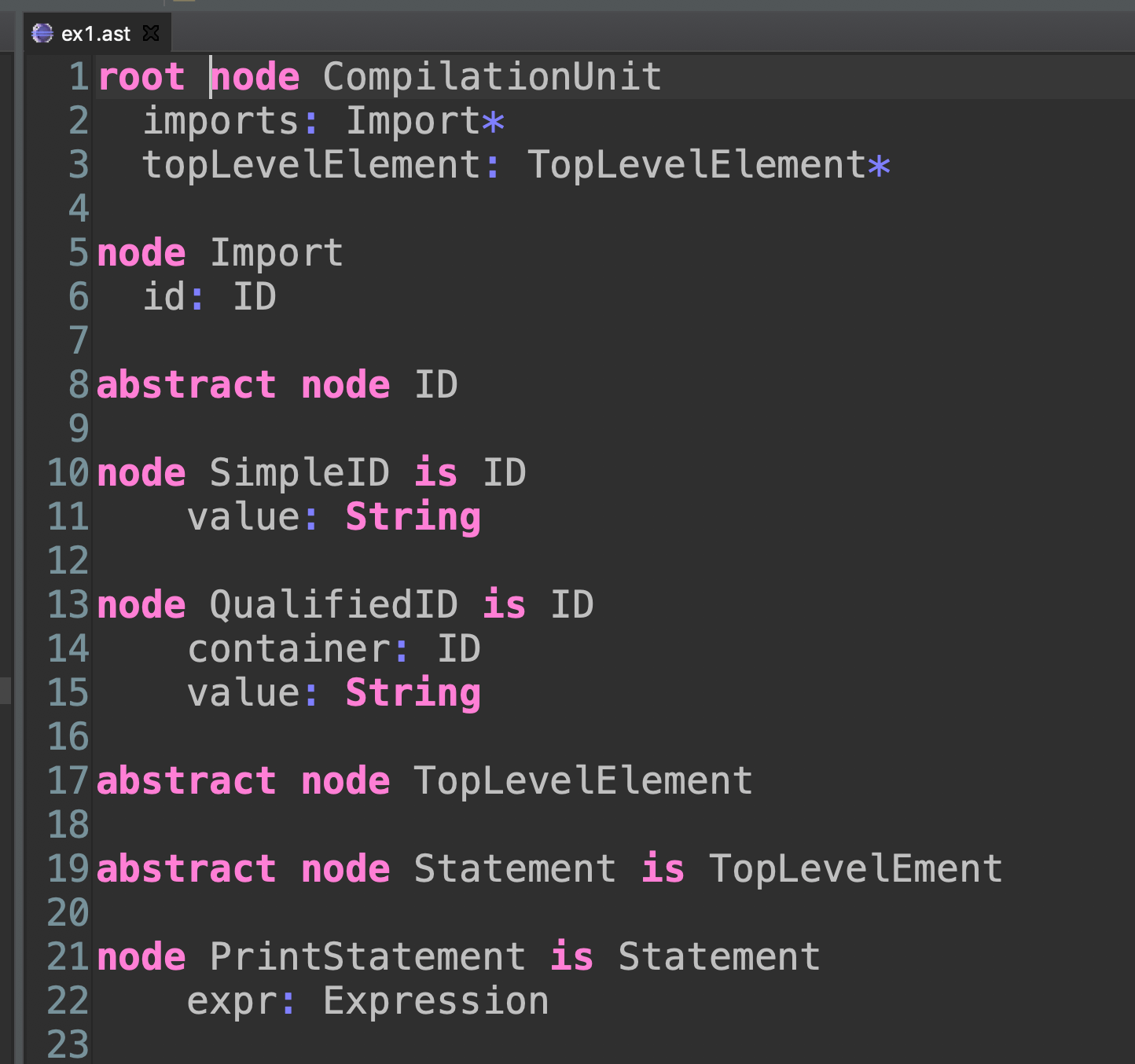
In this example we start by specifying that our ASTs will have a root node of type CompilationUnit. These CompilationUnits will have several imports and top level elements. An Import will have an ID. An ID could be either Simple (just a String) or Qualified (an ID followed by a String).
This simple DSL permits defining nodes with fields of primitive types as String, Int. Fields could also be other nodes, in that case their type is specified. Fields can have one occurrence, zero or one occurrence (? qualifier), one or more occurrences (+ qualifier) or zero or more occurrences (* qualifier).
In this tutorial we will see how to define a parser and an editor for this DSL.
## What is Spoofax?
Before jumping into code it would make sense to spend a few words explaining what Spoofax is.
Spoofax is a Language Workbench. In other words, it is an environment that could be used for creating programming languages and their supporting tools more rapidly. One can use a Language Workbench to sketch a new language and have a running editor for it in a matter of hours. They are typically used for experimenting with language designs and implementing Domain Specific Languages, as in these contexts reducing development time is essential.
Other examples of Language Workbenches are JetBrains MPS, Xtext, textX, and the Whole Platform.
The mission statement is Language Implementation by Declarative Language Definitions. In practice, it means that Spoofax offers to its users (Language Designers) a bunch of declarative DSLs to define languages. It then extracts information from these declarations to provide things like syntax highlighting, parsing, auto-formatters, and more.
Spoofax parsers are based on Scannerless Generalized LR parsing. While ANTLR first runs a lexer to split the original input into tokens and then organize those tokens into a parse tree, Spoofax does everything in one step. Now, one advantage of this is that keywords can be context dependent. Another important advantage is the possibility of mixing languages. Disadvantages are poorer performance and more confusing error messages.
In Spoofax one can use a DSL to define the syntax of a language but other supporting DSLs can be used while working on the DSL. For example, Spoofax includes SPT, the Spoofax Testing Language. In SPT, one can write simple examples of the language one is working on and verify they parse correctly. For those same examples, one can also verify that the AST produced is the one expected. This is something that would be very useful for us at Strumenta, as we build a lot of parsers. Also because of scannerless parsing it is easier to mix the constructs to test with the language itself to be tested. This one interesting example of mixing languages: we mix the language being parsed with the language for specifying parsing tests.
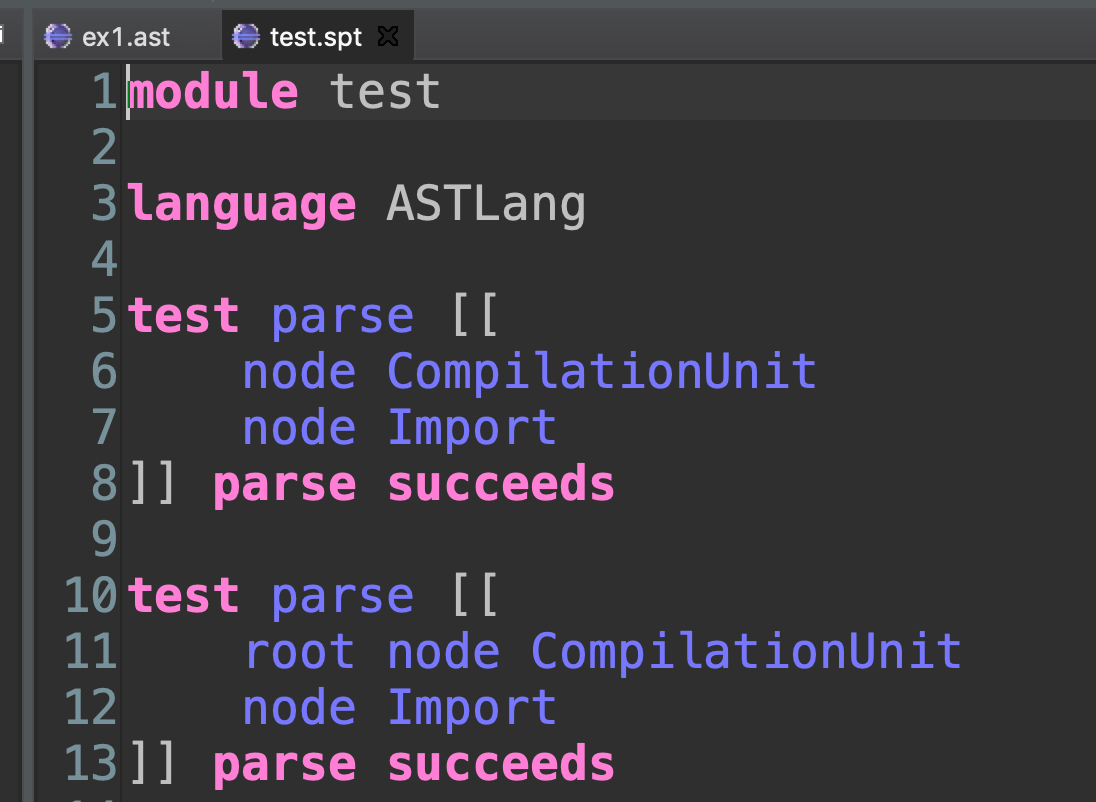
Above you can use a simple example of an spt file to test our AST language.
# Tutorial
We will assume you have managed to install Spoofax 2 following the instructions listed here: https://www.spoofax.dev/getting-started/
When trying to run the Mac app we downloaded, it would not work out of the box. So we had to manually start the executable at spoofax.app/Contents/MacOS/eclipse.
We then started with a clean workspace and added a new Spoofax project. We specified the Project name, the Group identifier, the Extensions and then we disabled the Analysis. We disabled Analysis because this is something we will not be able to cover in this tutorial and we did not want errors related to that feature to pop up. We also ensured to have the unit testing project option selected.
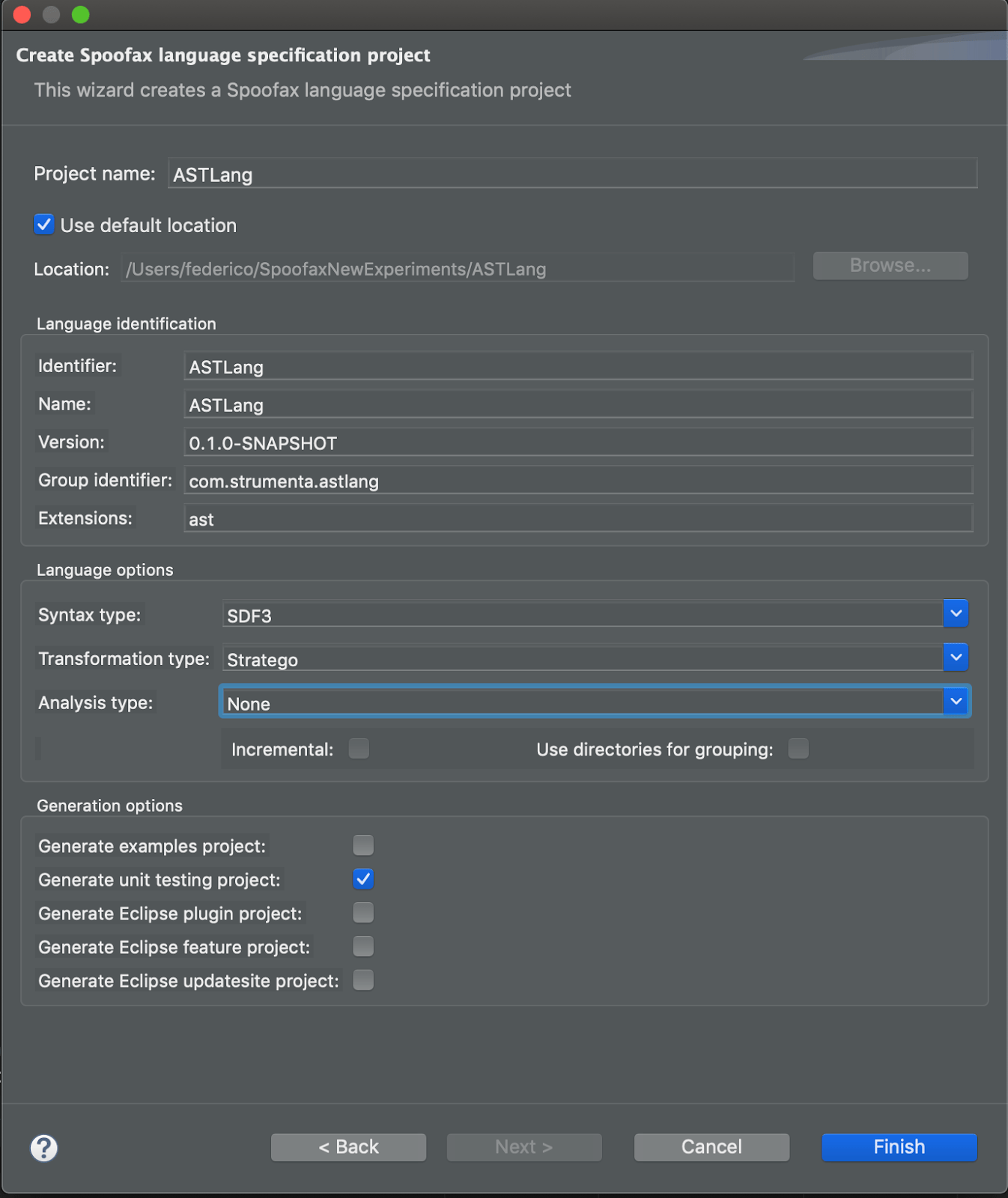
What are we going to do now?
We are going to create a bunch of examples and then evolve the language to let us express them.
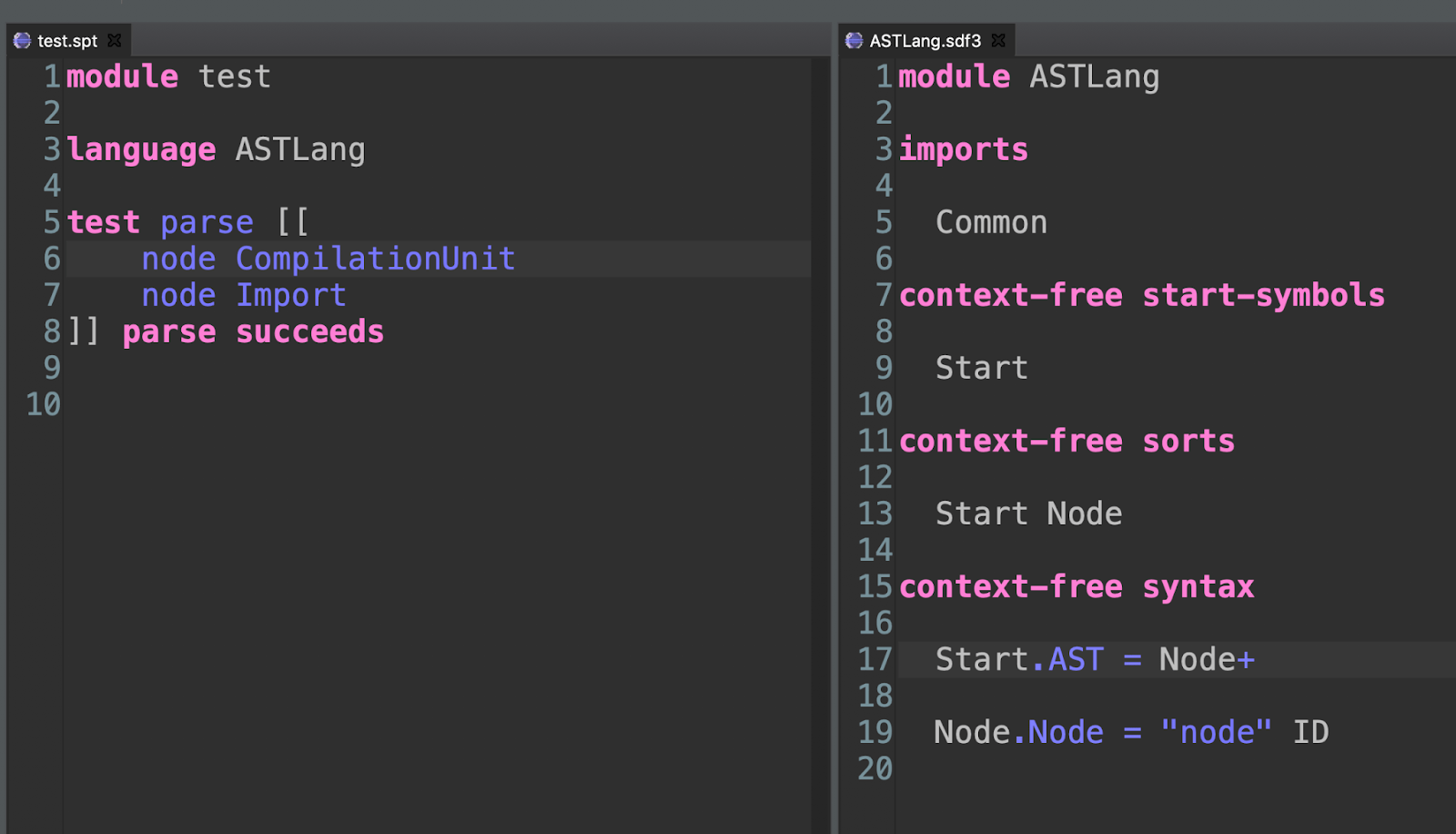
We are going to start in a very simple way: with an example that lets us define a couple of node types. And that example will initially fail to parse:
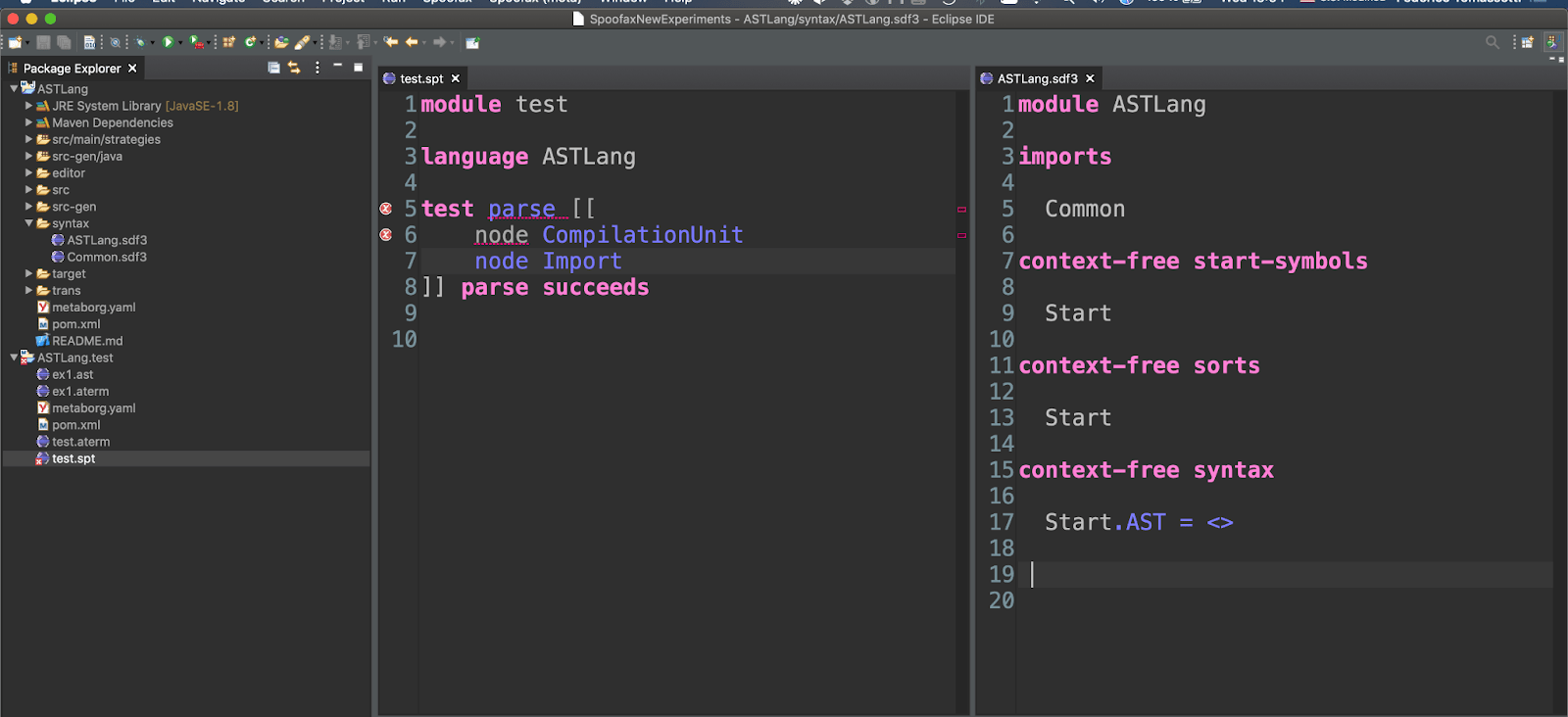
Let’s fix that.
To fix it we need to:
- Define a new kind of context-free non-terminal by adding a name in the context-free sorts (Node)
- We need to specify the syntax of this new element. It will be the keyword “node” followed by an ID. Note that a Spoofax project is created with some convenient token types under Common.sdf3, so we do not need to define ID ourselves
- We need to specify that the Start symbol is a sequence of one or more Nodes
At this point, to make the errors disappear in the test file we needed to trigger “Build All”, even if “Build automatically” was set.
After that we changed the test file, saved it, and changed it back for it to refresh and see our first test passing. One thing we also noticed is that when errors are present in the grammar the build silently fails, so remember to check your “Problems” panel to see if everything went fine with the build, otherwise you will keep working on the grammar and do not see any change. And that could go on for a while, leading you to question your sanity. Or at least, that was my experience.
What next?
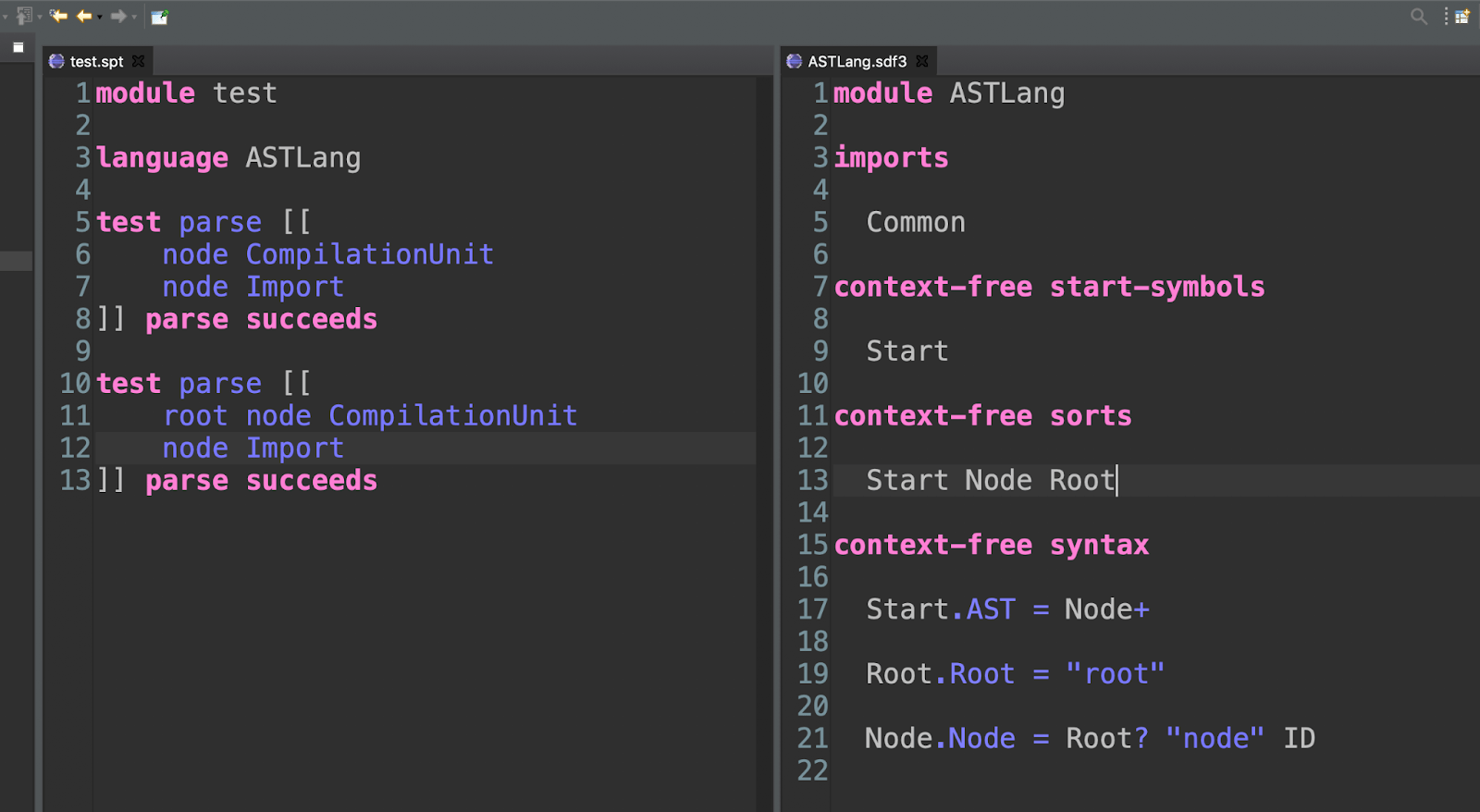
Well, we may want to specify which kind of node is the root node.
So we will need to add the “root” flag.
We will also need to specify that syntax for Node can include this optional “root” flag. Unfortunately, we cannot just specify the optional flag in the definition of Node, as quantifiers like “?” can be applied only to non-terminals. We, therefore, define the Rule “Root” and add the quantifier “?” to it when using it inside Node.
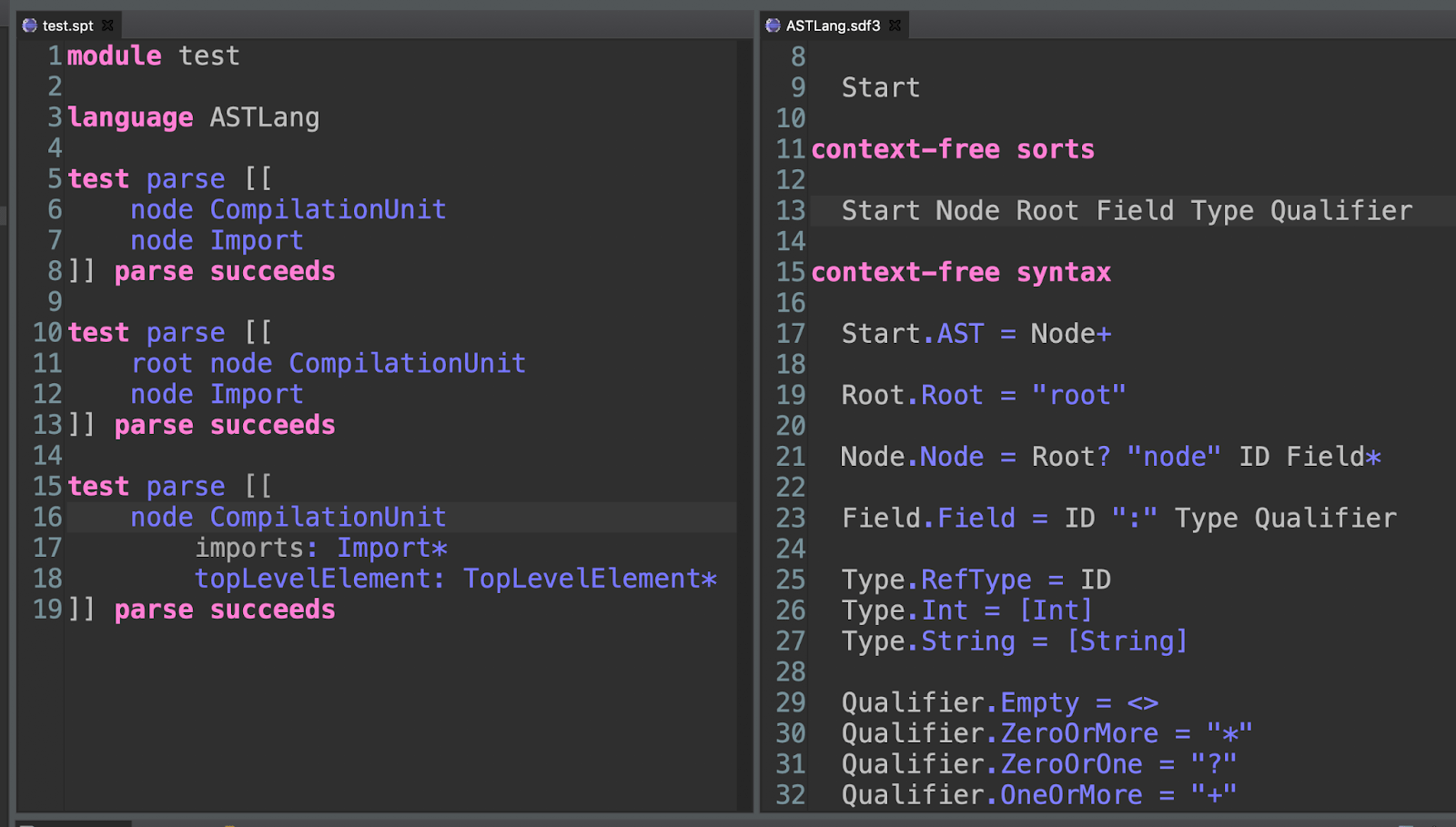
The next step is to allow our nodes to contain fields. In our simple language, a field can be of type Int, String, or be another Node. Fields can be present exactly one time, be optional, or be a list (zero or more, or one or more).
This was easy, right?
Well, yes but… it does not work as one would expect. Let’s try with another example.

What is that?
To figure that out we can use another useful feature of Spoofax: the possibility to take a look at the AST that it is building internally.
We can create a simple file with extension .ast (the extension we picked for our language). We can then write in that file the code we want to try out and then ask Spoofax to build the AST for that file.
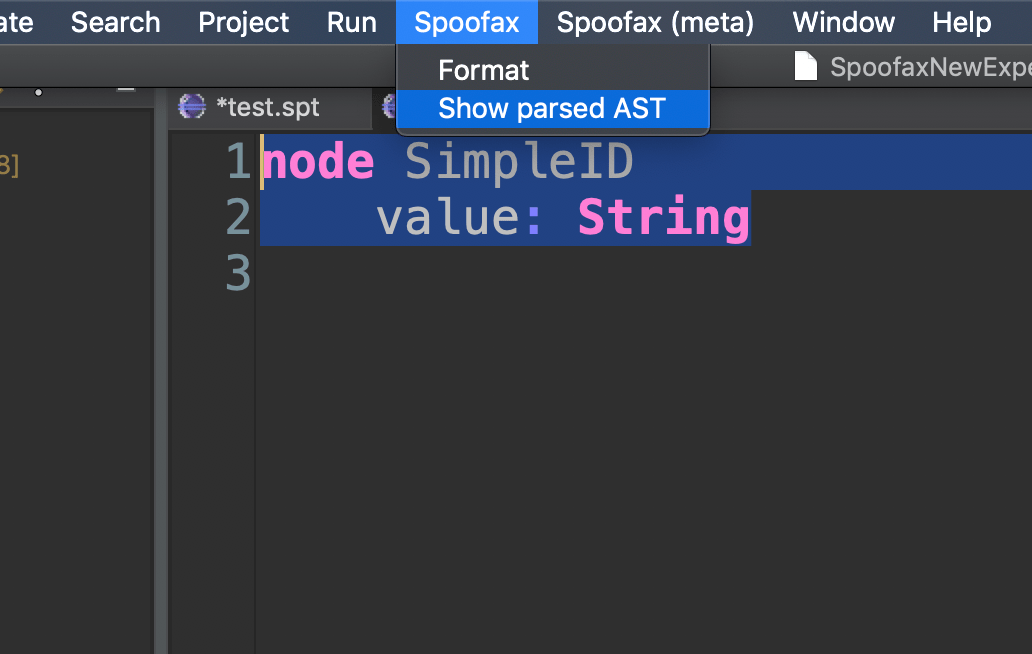
What do we get?
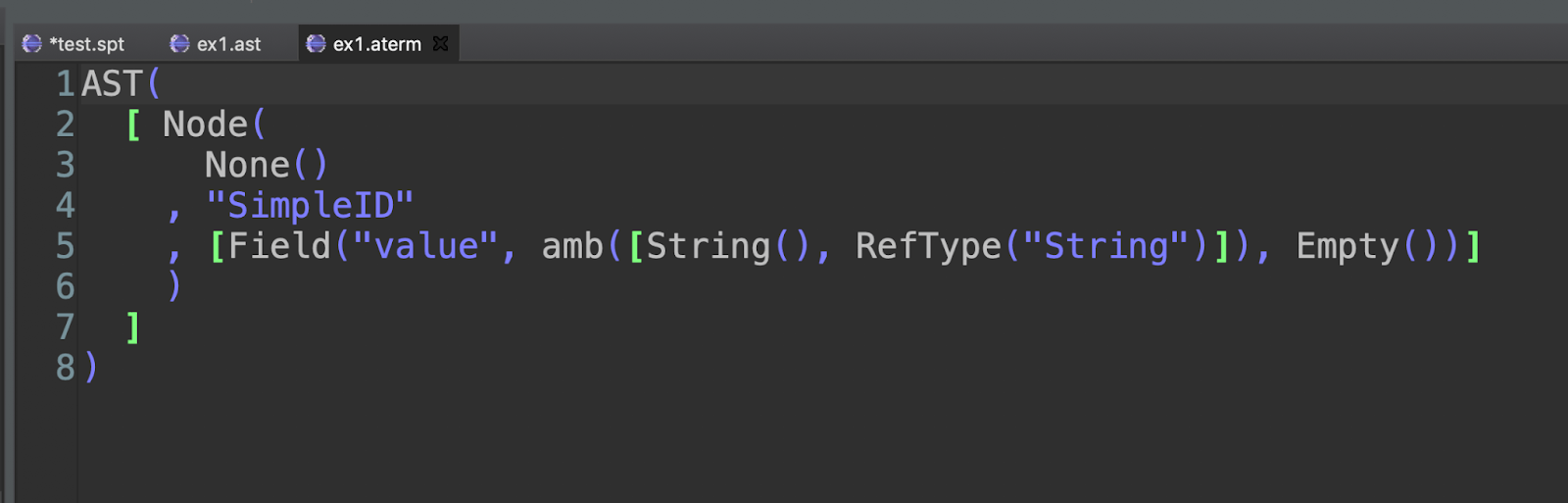
You see the “amb” part? It represents an ambiguity. At this point, I should say that Spoofax tries to build all possible interpretations of a file producing not a “tree” but a “forest”, if you want. Here it is telling us that the text “String” could be implemented as a node String or as a RefType to something called “String”. Spoofax has no way to decide which one is more important, so it just gives us the two options. However DSLs are about specifying things clearly, not supporting philosophical questions with no clear-cut answer, so we want to remove all ambiguities.
We can get this solved by adding these lines to our grammar.

The meaning of this instruction is to “update” the definition of ID that we inherited from “Common.sdf3”. In practicing we are saying that anything that is a keyword (i.e., a string used in our grammar) should not be considered as a valid ID.
Great. Time to move to the next feature for our language.
At this point we want to specify that certain nodes will be abstract, for example “Expression” or “Statement” are typically abstract nodes. We also want to specify that certain nodes extend other nodes, typically abstract nodes but not necessarily.
These are our examples:

And to support them we needed these changes to the grammar:

We should now have a language expressive enough to define reasonable ASTs. Let’s try it with a more complete example.
It worked: great!
Now, this is exactly why you want to use Language Workbenches to build languages. Using Spoofax we could quickly define examples and evolve our language very rapidly. Imagine how fast one can move when mastering such a tool. Building languages will become way cheaper!
## A few things we did not see about Spoofax
Obviously, our tutorial is just scratching the surface of what is possible to do with Spoofax and what is needed to have a properly usable DSL.
For example:
- We would need to implement symbol resolution. For example connecting Nodes extending other Nodes to the Nodes extended and triggering an error if a Node tries to extend a Node we do not know about
- Implement typesystem rules. This is not particularly relevant in our simple DSL but in general it is
- Implement semantic error checking, where needed
- Code generation: at the moment we can just use the DSL to define nodes but we may want to actually generate code out of those definitions
- Packaging eclipse plugins. With Spoofax we created an editor for our DSL. We may want to package it as an Eclipse plugin
- Run generators outside Eclipse. We may want to run our tests outside the Eclipse IDE, for example as part of automated tests. This is possible, but it requires a bit of extra work
While playing with Spoofax to learn this article we also noticed a few things.
For example, Spoofax also generates a formatter, which is a nice and useful feature. It is derived automatically from your grammar definition and it shows the importance of using declarative DSLs, as the information can be typically used for different goals. In this case both parsing and formatting. One defect of Spoofax’s formatter is that it throws away comments, which is probably not acceptable.
Spoofax’s highlighting is based on the parser, not on a lexer as there is no lexer. This means that syntax highlighting can be “smarter” than typically is.
A scannerless parser supporting ambiguity also means that sometimes one could run into very serious performance issues. For example in one case I wrote an example too flexible and that led to a parser extremely slow. As a consequence I was not able to use the editor anymore! I could not even edit the grammar to fix the problem because the editor was completely unusable.
## The team behind Spoofax
I personally consider a very positive example what the people at TU Delft managed to do. They built a solid system that their researchers constantly build upon to make valuable research. At the same time the platform has been also used in industrial projects. This is a very positive example of a sustainable ecosystem combining industrial users, research, and open-source. I wish I had something similar to build upon when I was doing my PhD.
In this team a vital role has been played by the late Eelco Visser. He has been a pillar of the Language Engineering community and recently passed away. I watched several of his tutorials to prepare this article and I attended a series of presentations he gave about Spoofax in the Strumenta Community. We as the whole Language Engineering community should be grateful for his contributions.
Eelco started working on Language Engineering on 1997. First he created Stratego, which was later included in the first version of Spoofax in 2006. Spoofax 2 followed in 2012, while work on Spoofax 3 started in 2019. At this time Spoofax 3 is still experimental and Spoofax 2 is the “stable version”. In this article, we have used Spoofax 2.
Spoofax also includes SDF 3. The first version of SDF was created in 1989 by Paul Klint and others. One can see how a lot of work went into building what Spoofax is today.
## About Eclipse
My opinion on Eclipse will not help me make new friends but honestly using an environment based on Eclipse feels like going back 15 years, when one comes from modern environments such as IntelliJ IDEA. I have personally been a loyal fan of Eclipse for a long time before moving to IDEA. So I definitely have a soft spot for Eclipse. It is difficult to explain in objective terms why one gets the impression of using an outdated environment. A few things I noticed is that IDEA automatically saves and builds files. Eclipse requires files to be saved explicitly and in my case the automated build did not work, but I had to trigger it manually. It also failed silently: at some point I got stuck for a while before having the intuition of checking the errors panel and identifying the issue. The errors panel was not brought in foreground when the build failed. Also, from the visual point of view some icons do not look right when using the dark theme.
So all in all I think that Spoofax being integrated with Eclipse plays at its disadvantage. I read some support for IDEA is present, but it does not seem to be as mature as support for Eclipse.
## Summary
I think that Spoofax is a very valuable Language Workbench, contributing very good ideas that could help move the field forward. The declarative nature of the DSLs it is based on, and features like the language for testing parsers or the possibility to see the AST for a piece of code, are very valuable.
Published on Java Code Geeks with permission by Federico Tomassetti, partner at our JCG program. See the original article here: A tutorial on Spoofax, a Language Workbench Opinions expressed by Java Code Geeks contributors are their own. |
