When we are tasked with performing a Language Migration we start with planning it. In this article, we are going to show our process for Audit & Analysis for Language Migration Projects, describing each single step and explaining the reasons why we move in this way. Hopefully, you can benefit from our experience with transpiling from one programming language to another and avoid the scars we collected over the years. If you are reading this, you may be looking into your first or second language migration as soon you may not have a lot of experience with this specific problem. We are here to give you a shortcut to get that experience.
What goes into planning a Language Migration?
Planning a Language Migration basically means understanding the existing codebase, defining how we want the new system to look like and then defining a plan to get there reliably.
Sounds simple, right?
We call this process Audit & Analysis, because we start with an audit of the existing codebase and we analyze the problem of converting the code, and producing a plan, described in a shiny report.
What is the goal of the Audit & Analysis?
The goal of the Audit & Analysis is to take time to reflect on what we are aiming to do and anticipate as many problems as possible so that we can correct the course now, while we have just a report and not a few hundred classes to change.
Once you get the plan, obviously you can just feed the report to Chat-Gpt and you will get a fully working, reliable transpiler. Right? Or, for the old-fashioned, you can build your own transpiler or work with Language Engineering craftsmen like us.
Why start with the Audit & Analysis?
As developers, we love coding. Oh boy, how difficult it is to resist jumping into the comfort of our IDE and start producing code, crunching method after method, class after class. One feels so productive; one feels the pleasure of crafting something, the excitement of seeing the first results.
And yet, even if it feels great, it is so very wrong to start coding without a plan when dealing with something as complex as a Language Migration.
You can think of moving a codebase from a language to another as similar to a heart transplant. Before you get started, you want to be really sure that the heart is compatible with the receiver, that the tools are clean and in the right place, that the receiver is sedated and so on. I think your patients would genuinely expect you to anticipate all possible problems and not just react to them as they appear. Shouldn’t we strive to be as professional? We think so because a failure in a language migration can have significant economic and organizational consequences for the people involved.
So we start by figuring out what we are dealing with, defining a plan we are confident in, and then, when we know where we are doing we can, finally, open the IDE and let the fun part begin.
How is the Audit & Analysis structured?
The Audit & Analysis is composed by five steps:
- Audit: In this step, we understand the existing system: its architecture, its size, the built-in functions that are used, the statements that are used, and the pattern that appears more frequently and is idiomatic to this codebase.
- Target Architecture Definition: At this stage, we want to define the architecture of the target system. Which version of Python or Java are we going to use? Which frameworks? Generating code for Odoo or Flask, for Spring or Vaadin are very different scenarios. We may also want to pick a database, and perhaps define integrations with existing applications already written. Here we define what we would like to get in the end.
- Risk Analysis: We look for risks. What could go wrong? What are the features that are difficult to replicate on the target system and important for us? Does our application employ AS/400 activation groups in complex ways? Is the usage of logical files that we find complex to replicate? Or do we need to emulate the same arithmetic rounding? Are performance expected to remain comparable? Here we look at the problems and write down a mitigation strategy for each of them.
- Mapping Definition: Here we discuss how to map complex idioms or complex functionalities of the source language into the target language.
- Testing Strategy: We define a testing strategy. How will we verify that the system works as expected?
Let’s now take a look at each step individually.
Step 1: Audit
The first step in an Audit of an existing codebase is… to get the whole codebase. And that could be more difficult than you think. Sometimes files are spread in different directories and no one knows exactly where all of them are.
We solve this by parsing the files we get and verifying if we can find all the symbols they refer to. Does program A call program B and we cannot find program B among the source files we have? We add it to the list of the missing files. When the Client delivers them to us we process also those, and the dance repeats until we have all files.
To perform a proper audit you will need a parser for the language you are migrating away from. You could build it, or you could license one from us.
Once we have the entire codebase it is time to start with producing some statistics:
- How many lines of code we have (with or without whitespace and comments)
- How many files we have
- How many statements we have
- How many expressions we have
- What is the frequency of each statement
- What is the frequency of each expression
- What built-in functions are we calling and how many times
For example, we use an internal tool to perform this statistical analysis. In the screenshot below you can see that we show how many times each built-in function is used:
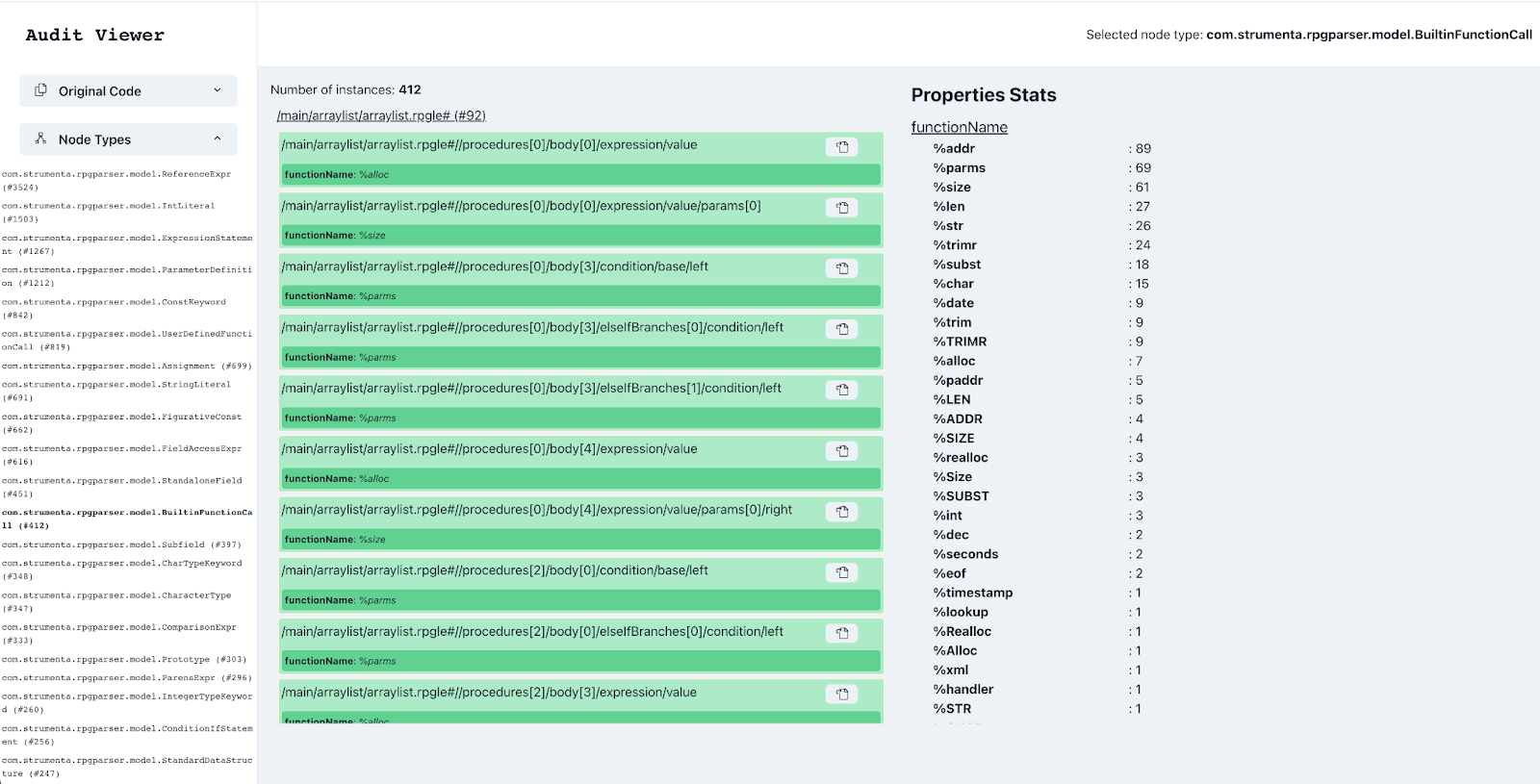
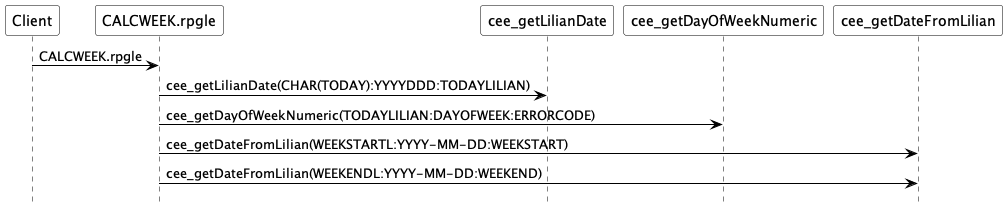
We then discuss with the owner of the system which are the most important entry points and the most important procedures. At this point, we take a look at the sequence diagrams that we generate for each procedure. So that we get a sense of how the application works.
In case of general purpose languages that support embedded SQL, we may also want to trace access to the tables.
Finally we look for recurring patterns, using a mix of experience and statistical analysis.
Things we are currently not doing but we plan to do in the future are:
- Identifying unreachable/dead code
- Identifying code clones
Below you can find a video a simple product we use internally to navigate the code:
While we built this tool specifically for this job you may instead use an IDE to perform these analysis. It will typically require more manual work, as the tool is not specifically designed for that, but it can be doable.
Step 2: Target Architecture Definition
If we go somewhere, we should first of all figure out where that somewhere is. In the case of a migration, we need to define how the new system is expected to look like before we can define a plan on how to generate code for that new system.
Among other things we need to understand:
- On which platform will the new system run? Will it run on the cloud? On the Intel architecture? On Apple Silicon? On which operating systems?
- What is the target language? Do we want to use Java? Or Python? Which versions? Do we want to use multiple languages? For example, is there a scripting part that we want to define in Ruby? Or maybe generating bash scripts? What about SQL?
- Are we going to interact with a database? Which one? SQL based? No-SQL?
- Do we need to integrate with certain services or APIs?
- Does the generated code need to follow certain guidelines in use at the company?
These are questions that the future owners and maintainers of the translated system should be able to answer.
If you are translating your own codebase, it means that you have to answer these questions. Or some Architect in your team has to.
In our case, we ask these questions to our clients, as they will need to use and maintain the code we are generating. While we can help in making some of these decisions it is really important that the company is involved in the discussion and they are convinced of every decision made at this stage.
Step 3: Risk Analysis
It will not come as a revelation that it makes sense to spend some time trying to anticipate all problems that we expect to encounter in the migration process before jumping head first.
We typically start by asking the client what they have already identified as problems, as they typically contact us after they have been considering doing a migration for a long time and have reflected on the problem. If you are performing a migration in-house, that translates to talking with both the colleagues that are maintaining the existing system and the ones that are in charge of maintaining the new system once it is deployed. Now, in many cases, these are two sets of developers, with the old RPG, Cobol, SAS, or Visual Basic developers about to retire and be replaced by the enthusiastic Java, Python, or Typescript developers who are going to take over. Here we are lucky when there is some overlap between the two teams and at least one person is familiar with both the old language and environment and the new one, as they are aware of the differences among the two and they can more easily spot the problems. If there are no developers available who are familiar with both languages, then the language engineers will need to act as intermediaries between the two teams and familiarize themselves with both languages.
You may also want to speak with colleagues that know their domain very well as they can underline what are the critical parts of the system and the areas with are more fragile or more important to get right.
For us, another resource to identify risks is our experience with migration. Given we have years of experience translating between several languages, we have a pretty good list of things to consider.
If you are doing this on your own for the first time, then I am afraid you have a bit higher chance to run into issues you have not anticipated. I wish I could share the list of 7 tips to identify all potential risks in a language migration, but I am afraid there is no such list.
These are some examples of problems we could identify during the risk analysis:
- The original language has low-level constructs with no equivalent in the target language (someone said Goto or Pointers?)
- The arithmetic is implemented differently in the original system and in the target system. I.e., expressions could produce slightly different results
- The original system is using extensively features of a standard library or third-party libraries for which there is no equivalent in the target system
- Significant differences in user interfaces and user interaction patterns available
Once we have identified these problems we discuss them until a solution or a mitigation strategy emerges. Once we are confident we can move forward we start our journey. Difficulties can always arise in similar projects, but this work typically helps arriving prepared to face most of them.
Step 4: Mapping Definition
Now that we know where we are (Audit), we know where we are going (Target Architecture), and we know the pitfalls we want to avoid (Risk Analysis), it is time to define a plan to get there. This is exactly what we should do as part of the Mapping Definition.
In this phase, we look at the different components of our system, and we define what we will map them in the new system.
For example, in RPG, we store data on physical and logical files, while in the target system, we typically want to use a database. A typical mapping that we may want to go for is to map physical files to tables and logical files to views.
We may also decide to map an RPG program to a Python class, or a procedure to a Python method.
In this phase, the mapping is defined at a rather coarse level: we are defining what each component will be translated, but we typically do not go deeper than the class or method level.
Step 5: Testing Strategy
One question that will always be in the air is: how can we be sure that the new system will behave as the old system?
This is an important question to answer. On one hand we know that, given the translation will be automatic, we may have systemic errors but not one-off errors that appear just on one occasion. Typically if things are translated in an incorrect way, they are translated incorrectly very consistently, and so we have many occasions to notice that.
We off course define unit tests for our transpiler, and you should do so if you are writing one. But that alone is not enough to reassure that the new system will behave correctly.
In the rare case in which there are tests for the original system, we will celebrate and then translate those tests. We will then ensure that the translated tests are all green and that will give us reasonable confidence, provided the tests have a certain amount of coverage.
In most cases however, there are no tests for the existing system, and in that situation, we consider writing end-to-end tests the best course of action. These are difficult to write, and typically, writing them requires understanding the functionality. For this reason, collaboration from the maintainers of the existing solution is very valuable. End-to-end tests are also expensive to run, and not just to write, but a bunch of them can give us confidence in the new system working correctly.
A typical end-to-end test is created in this way:
- In the original system, we set up the initial state of the system
- We run a program we want to test
- We capture the end state of the system
- We translate the initial state of the system and the final state of the system in the equivalent of the new system. For example, we may need to translate a file into data inserted in a SQL database
- We execute the translated program, passing the initial translated state, and we verify to obtain the end translated state.
We typically have clients defining the end-to-end tests. We give them guidelines and a template to fill out. In some cases, clients like to use Gherkin to define these tests. We do that because they know their infrastructure, and it is not always convenient for them to provide access to their data. In case you are performing the translation in-house, you may want to involve a separate team to test the results of the translation.
What next?
Ok, you have now completed your Audit & Analysis. You have discussed this with all people involved, and everyone nodded, and the thing can be crossed off as done.
Now what?
Now it is time to move forward with the implementation. And for that, we have some advice defined here: https://tomassetti.me/how-to-write-a-transpiler/
Summary
Migrating your codebase from one language to another is a complex process, especially if you have never done it before. So you can do your best to ensure that you create the best conditions possible to make this successful. Part of this is getting some preparatory work done before getting started. Our way to get this done is going through our Audit & Analysis process. We hope this process will help you too.
Published on Java Code Geeks with permission by Federico Tomassetti, partner at our JCG program. See the original article here: Audit & Analysis for Language Migration Projects Opinions expressed by Java Code Geeks contributors are their own. |
