If you need to process large database result sets from Java you can opt for JDBC to give you the low level control required. On the other hand if you are already using an ORM in your application falling back to JDBC might imply some extra pain. You would be losing features such as optimistic locking, caching, automatic fetching when navigating the domain model and so forth. Fortunately most ORMs, like Hibernate, have some options to help you with that. While these techniques are not new, there are a couple of possibilities to choose from.
A simplified example; let’s assume we have a table (mapped to class ‘DemoEntity’) with 100.000 records. Each record consists of a single column (mapped to the property ‘property’ in DemoEntity) holding some random alphanumerical data of about ~2KB.
The JVM is ran with -Xmx250m. Let’s assume that 250MB is the overall maximum memory that can be assigned to the JVM on our system. Your job is to read all records currently in the table, doing some not further specified processing, and finally store the result. We’ll assume that the entities resulting from our bulk operation are not modified. To start we’ll try the obvious first, performing a query to simply retrieve all data:
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() {
@Override
public Void doInTransaction(TransactionStatus status) {
Session session = sessionFactory.getCurrentSession();
List<DemoEntity> demoEntitities = (List<DemoEntity>) session.createQuery('from DemoEntity').list();
for(DemoEntity demoEntity : demoEntitities){
//Process and write result
}
return null;
}
});After a couple of seconds:
Exception in thread 'main' java.lang.OutOfMemoryError: GC overhead limit exceeded
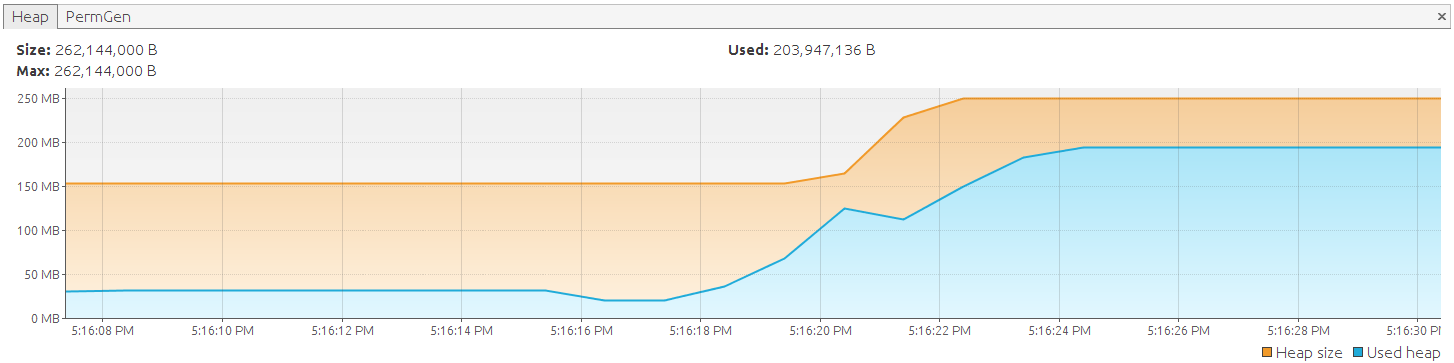
Clearly this won’t cut it. To fix this we will be switching to Hibernate scrollable result sets as probably most developers are aware of. The above example instructs hibernate to execute the query, map the entire results to entities and return them. When using scrollable result sets records are transformed to entities one at a time:
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() {
@Override
public Void doInTransaction(TransactionStatus status) {
Session session = sessionFactory.getCurrentSession();
ScrollableResults scrollableResults = session.createQuery('from DemoEntity').scroll(ScrollMode.FORWARD_ONLY);
int count = 0;
while (scrollableResults.next()) {
if (++count > 0 && count % 100 == 0) {
System.out.println('Fetched ' + count + ' entities');
}
DemoEntity demoEntity = (DemoEntity) scrollableResults.get()[0];
//Process and write result
}
return null;
}
});After running this we get:
... Fetched 49800 entities Fetched 49900 entities Fetched 50000 entities Exception in thread 'main' java.lang.OutOfMemoryError: GC overhead limit exceeded
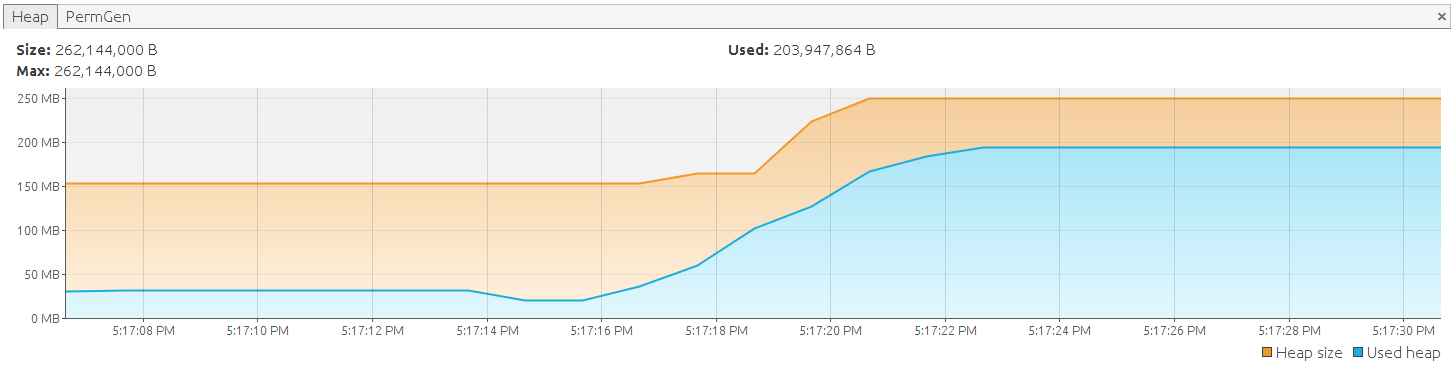
Although we are using a scrollable result set, every returned object is an attached object and becomes part of the persistence context (aka session). The result is actually the same as our first example in which we used ‘session.createQuery(‘from DemoEntity’).list()‘. However, with that approach we had no control; everything happens behind the scenes and you get a list back with all the data if hibernate has done its job. using a scrollable result set on the other hand gives us a hook into the retrieval process and allows us to free memory up when needed. As we have seen it does not free up memory automatically, you have to instruct Hibernate to actually do it. Following options exist:
- Evicting the object from the persistent context after processing it
- Clearing the entire session every now and then
We will opt for the first. In the above example under line 13 (//Process and write result) we’ll add:
session.evict(demoEntity);
Important:
- If you were to perform any modification to the entity (or entities it has associations with that are cascade evicted alongside), make sure to flush the session PRIOR evicting or clearing, otherwise queries hold back because of Hibernate’s write behind will not be sent to the database
- Evicting or clearing does not remove the entities from second level cache. If you enabled second level cache and are using it and you want to remove them as well use the desired sessionFactory.getCache().evictXxx() method
- From the moment you evict an entity it will be no longer attached (no longer associated with a session). Any modification done to the entity at that stage will no longer be reflected to the database automatically. If you are using lazy loading, accessing any property that was not loaded prior the eviction will yield the famous org.hibernate.LazyInitializationException. So basically, make sure the processing for that entity is done (or it is at least initialized for further needs) before you evict or clear
After we run the application again, we see that it now successfully executes:
... Fetched 99800 entities Fetched 99900 entities Fetched 100000 entities
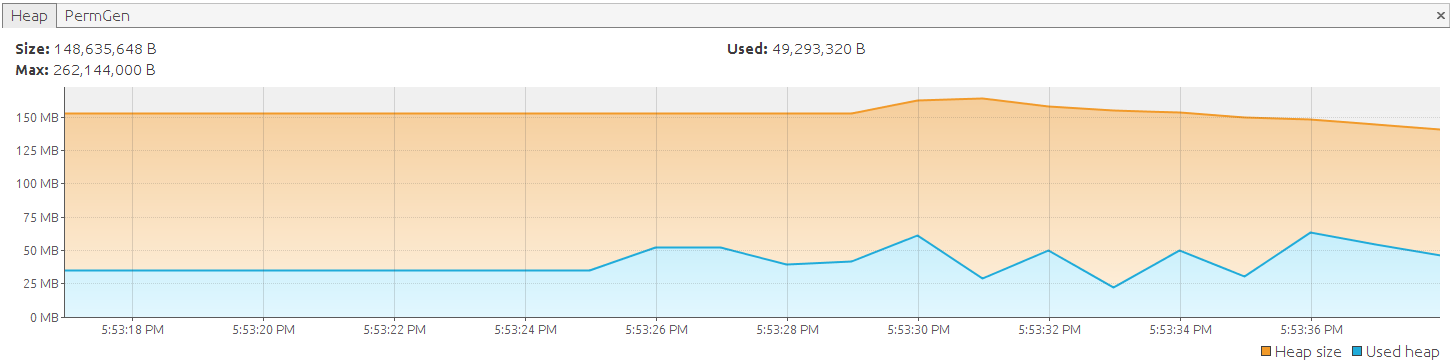
Btw; you can also set the query read-only allowing hibernate to perform some extra optimizations:
ScrollableResults scrollableResults = session.createQuery('from DemoEntity').setReadOnly(true).scroll(ScrollMode.FORWARD_ONLY);Doing this only gives a very marginal difference in memory usage, in this specific test setup it enabled us to read about 300 entities extra with the given amount of memory. Personally I would not use this feature merely for memory optimizations alone but only if it suits in your overall immutability strategy. With hibernate you have different options to make entities read-only: on the entity itself, the overall session read-only and so forth. Setting read only false on the query individually is probably the least preferred approach. (eg. entities loaded in the session before will remain unaffected, possibly modifiable. Lazy associations will be loaded modifiable even if the root objects returned by the query are read only).
Ok, we were able to process our 100.000 records, life is good. But as it turns out Hibernate has another another option for bulk operations: the stateless session. You can obtain a scrollable result set from a stateless session the same way as from a normal session. A stateless session lies directly above JDBC. Hibernate will run in nearly ‘all features disabled’ mode. This means no persistent context, no 2nd level caching, no dirty detection, no lazy loading, basically no nothing. From the javadoc:
/** * A command-oriented API for performing bulk operations against a database. * A stateless session does not implement a first-level cache nor interact with any * second-level cache, nor does it implement transactional write-behind or automatic * dirty checking, nor do operations cascade to associated instances. Collections are * ignored by a stateless session. Operations performed via a stateless session bypass * Hibernate's event model and interceptors. Stateless sessions are vulnerable to data * aliasing effects, due to the lack of a first-level cache. For certain kinds of * transactions, a stateless session may perform slightly faster than a stateful session. * * @author Gavin King */
The only thing it does is transforming records to objects. This might be an appealing alternative because it helps you getting rid of that manual evicting/flushing:
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() {
@Override
public Void doInTransaction(TransactionStatus status) {
sessionFactory.getCurrentSession().doWork(new Work() {
@Override
public void execute(Connection connection) throws SQLException {
StatelessSession statelessSession = sessionFactory.openStatelessSession(connection);
try {
ScrollableResults scrollableResults = statelessSession.createQuery('from DemoEntity').scroll(ScrollMode.FORWARD_ONLY);
int count = 0;
while (scrollableResults.next()) {
if (++count > 0 && count % 100 == 0) {
System.out.println('Fetched ' + count + ' entities');
}
DemoEntity demoEntity = (DemoEntity) scrollableResults.get()[0];
//Process and write result
}
} finally {
statelessSession.close();
}
}
});
return null;
}
});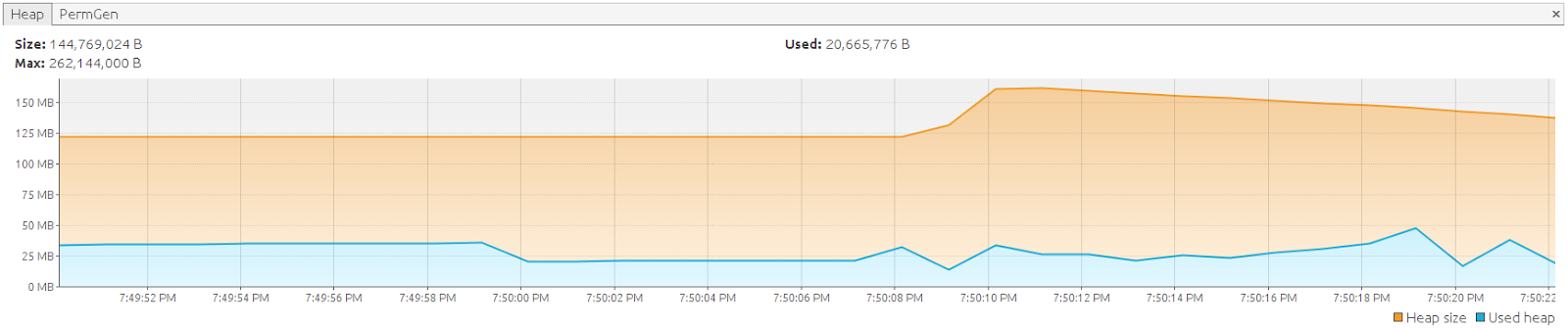
Besides the fact that the stateless session has the most optimal memory usage, using the it has some side effects. You might have noticed that we are opening a stateless session and closing it explicitly: there is no sessionFactory.getCurrentStatelessSession() nor (at the time of writing) any Spring integration for managing the stateless session.Opening a stateless session allocates a new java.sql.Connection by default (if you use openStatelessSession()) to perform its work and therefore indirectly spawns a second transaction. You can mitigate these side effects by using the Hibernate work API as in the example which supplies the current Connection and pass it along to openStatelessSession(Connection connection). Closing the session in the finally has no impact on the physical connection since that is captured by the Spring infrastructure: only the logical connection handle is closed and a new logical connection handle was created when opening the stateless session.
Also note that you have to deal with closing the stateless session yourself and that the above example is only good for read-only operations. From the moment you are going to modify using the stateless session there are some more caveats. As said before, hibernate runs in ‘all feature disabled’ mode and as a direct consequence entities are returned in detached state. For each entity you modify, you’ll have to call: statelessSession.update(entity) explicitly. First I tried this for modifying an entity:
new TransactionTemplate(txManager).execute(new TransactionCallback<Void>() {
@Override
public Void doInTransaction(TransactionStatus status) {
sessionFactory.getCurrentSession().doWork(new Work() {
@Override
public void execute(Connection connection) throws SQLException {
StatelessSession statelessSession = sessionFactory.openStatelessSession(connection);
try {
DemoEntity demoEntity = (DemoEntity) statelessSession.createQuery('from DemoEntity where id = 1').uniqueResult();
demoEntity.setProperty('test');
statelessSession.update(demoEntity);
} finally {
statelessSession.close();
}
}
});
return null;
}
});The idea is that we open a stateless session with the existing database Connection. As the StatelessSession javadoc indicates that no write behind occurs, I was convinced that each statement performed by the stateless session would be sent directly to the database. Eventually when the transaction (started by the TransactionTemplate) would be committed the results would become visible in the database. However, hibernate does BATCH statements using a stateless session. I’m not 100% sure what the difference is between batching and write behind, but the result is the same and thus contra dictionary with the javadoc as statements are queued and flushed at a later time. So, if you don’t do anything special, statements that are batched will not be flushed and this is what happened in my case: the ‘statelessSession.update(demoEntity);’ was batched and never flushed. One way to force the flush is to use the hibernate transaction API:
StatelessSession statelessSession = sessionFactory.openStatelessSession(); statelessSession.beginTransaction(); ... statelessSession.getTransaction().commit(); ...
While this works, you probably don’t want to start controlling your transactions programatically just because you are using a stateless session. Also, doing this we are again running our stateless session work in a second transaction scenario since we didn’t pass along our Connection and thus a new database connection will be acquired. The reason we can’t pass along the outer Connection is because if we commit the inner transaction (the ‘stateless session transaction’) and it would be using the same connection as the outer transaction (started by the TransactionTemplate) it would break the outer transaction atomicity as statements from the outer transaction sent to database would be committed along with the inner transaction. So not passing along the connections means opening a new connection and thus creating a second transaction. A better alternative would be just to trigger Hibernate to flush the stateless session. However, statelessSession has no ‘flush’ method to manually trigger a flush. A solution here is to depend a bit on the Hibernate internal API. This solution makes the manual transaction handling and the second transaction obsolete: all statements become part of our (one and only) outer transaction:
StatelessSession statelessSession = sessionFactory.openStatelessSession(connection);
try {
DemoEntity demoEntity = (DemoEntity) statelessSession.createQuery('from DemoEntity where id = 1').uniqueResult();
demoEntity.setProperty('test');
statelessSession.update(demoEntity);
((TransactionContext) statelessSession).managedFlush();
} finally {
statelessSession.close();
}Fortunately there is an even better solution very recently posted on the Spring jira: https://jira.springsource.org/browse/SPR-2495 This is not yet part of Spring, but the factory bean implementation is pretty straight forward: StatelessSessionFactoryBean.java when using this you could simple inject the StatelessSession:
@Autowired private StatelessSession statelessSession;
It will inject a stateless session proxy which is equivalent to the way the normal ‘current’ session works (with the minor difference that you inject a SessionFactory and need to obtain the currentSession each time). When the proxy is invoked it will lookup the stateless session bound to the running transaction. If none exists already it will create one with the same connection as the normal session (like we did in the example) and register a custom transaction synchronization for the stateless session. When the transaction is committed the stateless session is flushed thanks to the synchronization and finally closed. Using this you can inject the stateless session directly and use it as a current session (or the same way as you would inject a JPA PeristentContext for that matter). This relieves you from dealing with the opening and closing of the stateless session and having to deal with one way or the other to make it flush. The implementation is JPA aimed, but the JPA part is limited to obtaining the physical connection in obtainPhysicalConnection(). You can easily leave out the EntityManagerFactory and get the physical connection directly from the Hibernate session.
Very careful conclusion: it is clear that the best approach will depend on your situation. If you use the normal session you will have to deal with eviction yourself when reading or persisting entities. Besides the fact you have to do this manually, it might also impact further use of the session if you have a mixed transaction; you both perform ‘bulk’ and ‘normal’ operations in the same transaction. If you continue with the normal operations you will have detached entities in your session which might lead to unexpected results (as dirty detection will no longer work and so forth). On the other hand you will still have the major hibernate benefits (as long as the entity isn’t evicted) such as lazy loading, caching, dirty detection and the likes. Using the stateless session at the time of writing requires some extra attention on managing it (opening, closing and flushing) which can also be error prone. In the assumption you can proceed with the proposed factory bean, you have a very bare bone session which is separately from your normal session but still participating in the same transaction. With this you have a powerful tool to perform bulk operations without having to think about memory management. The downside is that you don’t have any other hibernate functionality available.
Reference: Bulk fetching with Hibernate from our JCG partner Koen Serneels at the Koen Serneels – Technology blog blog.
