Extract transform load is process for pulling data from one datasystem and loading into another datasystem. Datasystem involved are called source system and target system.
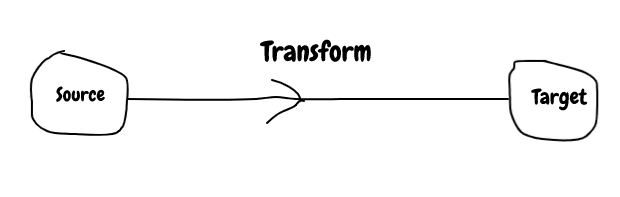
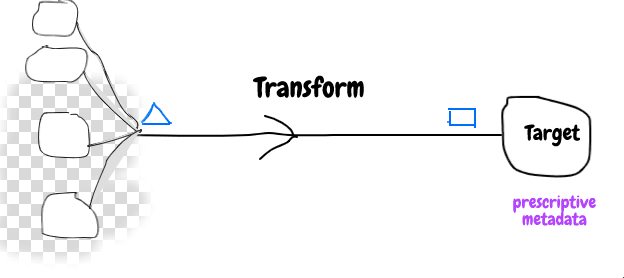
Shape of data from source system does not match to the target system, so some conversion is required to make it compatible and that process is called transformation. Transformation is made of map/filter/reduce operations.
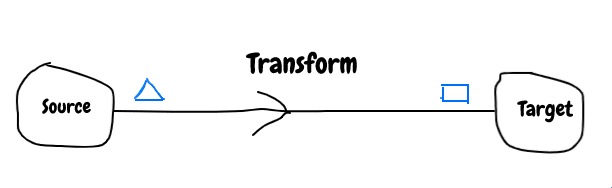
To handle the incompatibility between data systems some metadata is required. What type of metadata will be useful ?
It is very common that source data will be transformed to many different shape to handle various business usecase, so it makes sense to use descriptive metadata for source system and prescriptive metadata for target system.
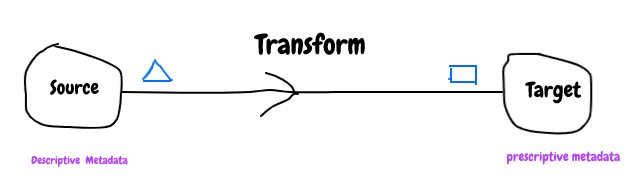
Metadata plays important role in making system both backward and forward compatible.
Many times just having metadata is not enough because some source/target system data is too large or too small to fit.

This is situation when transformation becomes interesting. This means some value have to dropped or set to NULL or to default value, making good decision about this is very important for backward/forward compatibility of transformation. I would say many business success also depends on how this problem is solved! Many integration nightmare can be avoided if this is done properly.
So far we were discussing about single source system but for many use case data from other systems is required to do some transformation like converting userid to name , deriving new column value , lookup encoding and many more.
Adding multiple source system adds complexity in transformation to handle missing data , stale data and many more.
As datasystems are evolving so it is not only about relation store today we see key-value store , document store , graph db , column store , cache , logs etc.
New datasystems are distributed also, so this adds another dimension to complexity of transformation.
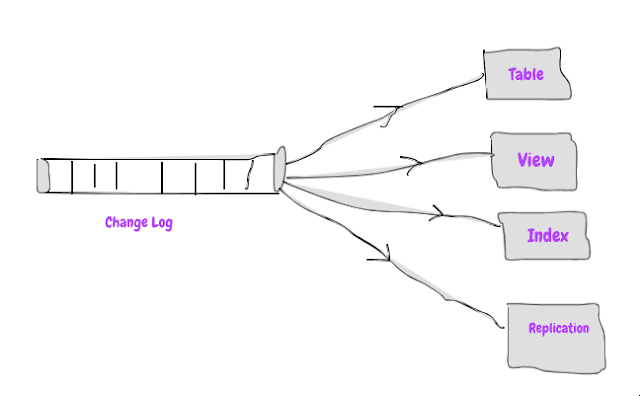
Our old relational databases can be also described as it is built using ETL pattern by using change log as source for everything database does
One of the myth about ETL is that it is batch process but that is changing overtime with Stream processor (i.e Spark Streaming , Flink etc) and Pub Sub systems ( Kafka , Pulsur etc). This enables to do transformation immediately after event is pushed to source system.
Don’t get too much carried away by Streaming buzzword, no
matter which stream processor or pub sub system you use but you still have to handle above stated challenges or leverage on some of new platform to take care of that.
Invest in transformation/business logic because it is key to building successful system that can be maintained and scaled.
Keeping it stateless, metadata driven, handle duplicate/retry etc, more importantly write Tests to take good care of it in fast changing time.
Next time when you get below question on your ETL process
Do you process real time or batch ?
You answer should be
It is event based processing.
Long live E T L
Published on Java Code Geeks with permission by Ashkrit Sharma, partner at our JCG program. See the original article here: Long Live ETL Opinions expressed by Java Code Geeks contributors are their own. |
