In this tutorial, we’ll learn how to generate Java classes from an Apache Avro schema.First, we’ll familiarize ourselves with two methods: using the existing Gradle plugin and implementing a custom task for the build script. Then, we’ll identify the pros and cons of each approach and understand which scenarios they fit best.
1. Introduction
Generating Java classes from Avro schemas using Gradle streamlines the process of integrating data serialization within Java projects. By leveraging Avro schemas, developers can define their data structures in a concise, language-agnostic format. Gradle, a powerful build automation tool, simplifies the conversion of these schemas into Java classes, ensuring seamless serialization and deserialization. This integration not only enhances efficiency but also maintains consistency across various services and applications, making it an essential skill for Java developers working with data-intensive systems.
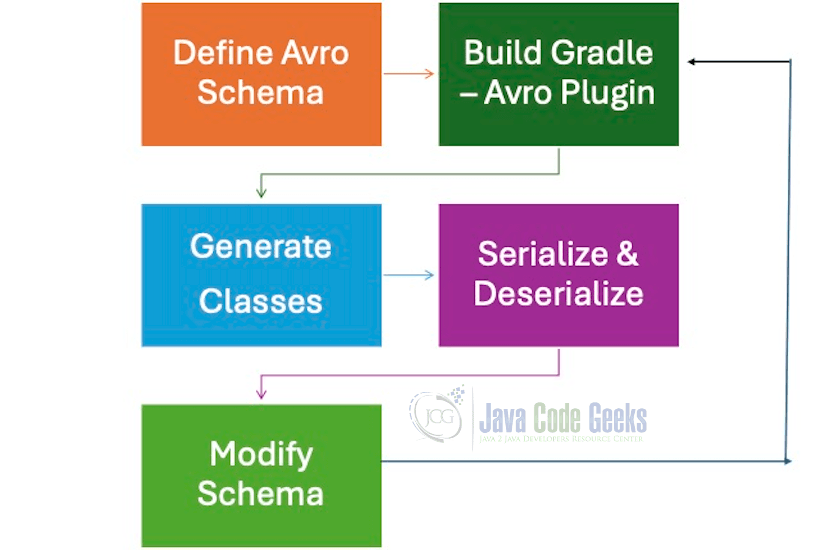
Generating Java classes from Avro schemas using Gradle starts with defining your Avro schema in a ‘.avsc’ file. This file specifies your data’s structure. Next, set up your Gradle project and include the necessary dependencies, such as the ‘avro-gradle-plugin’. You then configure the plugin in your ‘build.gradle’ file, pointing to the schema file and specifying the output directory for the generated Java classes. Running the Gradle build task will now generate Java classes from the Avro schema, allowing for seamless data serialization and deserialization in your Java projects. Simple, efficient, and effective!
2. Getting Started With Apache Avro
Apache Avro is a data serialization framework that facilitates efficient data exchange between systems using different languages. It uses JSON to define data schemas, making it easy to understand and manipulate. Avro supports schema evolution, meaning older schemas can read data written with newer versions and vice versa. This compatibility ensures smooth data communication and integration across distributed systems. Avro’s compact, binary data format enhances performance and reduces storage requirements, making it an ideal choice for big data applications and systems where bandwidth and storage efficiency are critical. You need to have Java installed. You can use jdk 1.8 and set JAVA_HOME to the installed JDK.
2.1 Gradle Setup
You can download or setup the gradle. Gradle command for setup is :
$ mkdir /opt/gradle $ unzip -d /opt/gradle gradle-8.10.2-bin.zip $ ls /opt/gradle/gradle-8.10.2
After setting up, you can run the gradle command to check the version. Gradle command is shown below:
gradle -v
The output of the executed command is shown below:
bhagvanarch@Bhagvans-MacBook-Air avro_oct_20 % gradle -v ------------------------------------------------------------ Gradle 8.10.2 ------------------------------------------------------------ Build time: 2024-09-23 21:28:39 UTC Revision: 415adb9e06a516c44b391edff552fd42139443f7 Kotlin: 1.9.24 Groovy: 3.0.22 Ant: Apache Ant(TM) version 1.10.14 compiled on August 16 2023 Launcher JVM: 23 (Homebrew 23) Daemon JVM: /opt/homebrew/Cellar/openjdk/23/libexec/openjdk.jdk/Contents/Home (no JDK specified, using current Java home) OS: Mac OS X 14.6.1 aarch64 bhagvanarch@Bhagvans-MacBook-Air avro_oct_20 %
3. Java Classes Generation
Apache Avro is a widely used data serialization framework that efficiently stores and exchanges large datasets across diverse programming languages. It’s trendy in big data ecosystems, often seen in conjunction with Hadoop and Kafka. One of the key features of Avro is its ability to define schemas in JSON format, which makes it both human-readable and machine-processable. Avro schemas ensure that the data structure is clearly defined, facilitating smooth data communication between services.
At its core, Avro provides a compact and fast binary data format that reduces storage overhead and accelerates data processing. It uses JSON to define the data structure, known as a schema, and supports schema evolution, allowing systems to handle data encoded with older versions of the schema. This feature is crucial for maintaining compatibility in distributed systems where updating all components simultaneously is impractical.
Generating Java classes from Avro schemas automates the serialization and deserialization process, providing a type-safe way to handle data. This not only speeds up development but also reduces errors associated with manual serialization. Avro’s binary format ensures that the data is both compact and easy to process, making it ideal for high-performance applications.
3.1 Steps to Generate Java Classes Using Apache Avro
3.1.1 Define the Avro Schema
The first step is to define your Avro schema in a ‘.avsc’ file. This file is written in JSON and specifies the structure of the data, including the fields and their data types. Here’s an example of an Avro schema for a simple user record. Let us look at the JSON file:
{
"namespace": "org.javacodegeeks",
"type": "record",
"name": "User",
"namespace": "com.example",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": ["null", "string"], "default": null}
]
}
In this schema, we define a ‘User’ record with three fields: ‘id’, ‘name’, and ’email’. The ’email’ field is nullable, indicated by the union type ‘[“null”, “string”]’.
3.1.2 Install Apache Avro Tools
Next, you need to install the Apache Avro tools. These tools include a compiler that generates Java classes from Avro schemas. You can download the Avro tools JAR file from the official Apache Avro website or add it to your build configuration if you’re using a build tool like Gradle or Maven.
For Gradle, add the following dependency to your ‘build.gradle’ file:
buildscript {
dependencies {
classpath libs.avro.tools
}
}
plugins {
id 'java'
alias libs.plugins.avro
}
repositories {
mavenCentral()
}
dependencies {
implementation libs.avro
// Use JUnit Jupiter for testing.
testImplementation libs.junit.jupiter
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}
Update your libs.toml file which is found under gradle folder.
# This file was generated by the Gradle 'init' task.
# https://docs.gradle.org/current/userguide/platforms.html#sub::toml-dependencies-format
[versions]
junit-jupiter = "5.10.0"
avro = "1.11.0"
[libraries]
junit-jupiter = { module = "org.junit.jupiter:junit-jupiter", version.ref = "junit-jupiter" }
avro = {module = "org.apache.avro:avro", version.ref = "avro"}
avro-tools = {module = "org.apache.avro:avro-tools", version.ref = "avro"}
[plugins]
avro = { id = "com.github.davidmc24.gradle.plugin.avro", version = "1.9.1" }
3.1.3 Generate Java Classes
Avro Tools
With the schema defined and the Avro tools installed, you can now generate the Java classes. This can be done using the Avro tools command-line interface or through your build tool.
For command-line usage, run the following command:
java -jar avro-tools-1.10.2.jar compile schema user.avsc .
This command tells the Avro compiler to generate Java classes from the ‘user.avsc’ file and place them in the current directory.
Gradle
If you’re using Gradle, you can run the build task
./gradlew build
Running ‘./gradlew build’ will then generate the Java classes. You can find them under build/generated-main-avro-java
3.1.4 Implement Serialization and Deserialization
Once the Java classes are generated, you can use them to serialize and deserialize data. Avro provides specific classes to handle these operations, such as ‘DatumWriter’ and ‘DatumReader’ because some times we need to read and write data.
Here’s an example of how to serialize a ‘User’ object to a file:
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
import org.javacodegeeks.User;
public class AvroWriterExample {
public static void main(String[] args) {
User user = new User();
user.setId(1);
user.setName("John Doe");
user.setEmail("john.doe@example.com");
DatumWriter userDatumWriter = new SpecificDatumWriter(User.class);
try (DataFileWriter dataFileWriter = new DataFileWriter(userDatumWriter)) {
dataFileWriter.create(user.getSchema(), new File("users.avro"));
dataFileWriter.append(user);
} catch (IOException e) {
e.printStackTrace();
}
}
}
Please ensure you have the jars (avro and avro tools) downloaded.This example can be compiled and executed as below:
javac -cp "./*" AvroWriterExample.java java -classpath '.:./*' AvroWriterExample
In the above writer example, we create a ‘User’ object and serialize it to a file named ‘users.avro’.
To deserialize the data, you can use the ‘DatumReader’ class because some times you need to read data:
import org.apache.avro.file.DataFileReader;
import org.apache.avro.generic.GenericDatumReader;
import org.apache.avro.io.DatumReader;
import org.apache.avro.specific.SpecificDatumReader;
import org.javacodegeeks.avro.User;
import java.io.*;
public class AvroReaderExample {
public static void main(String[] args) {
File file = new File("users.avro");
DatumReader userDatumReader = new SpecificDatumReader(User.class);
try (DataFileReader dataFileReader = new DataFileReader(file, userDatumReader)) {
User user = null;
while (dataFileReader.hasNext()) {
user = dataFileReader.next(user);
System.out.println(user);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
This code reads the ‘users.avro’ file and prints each ‘User’ object to the console when the code is executed using the commands below.
javac -cp "./*" AvroReaderExample.java java -classpath '.:./*' AvroReaderExample
The output of the executed code above is shown below:
bhagvanarch@Bhagvans-MacBook-Air avro_example_oct_20 % java -classpath '.:./*' AvroReaderExample
{"id": 1, "name": "John Doe", "email": "john.doe@example.com"}
bhagvanarch@Bhagvans-MacBook-Air avro_example_oct_20 %
3.1.5 Schema Evolution and Compatibility
One of the powerful features of Avro is schema evolution, which allows for backward and forward compatibility when schemas change over time. This means you can add new fields, remove fields, or change field types without breaking existing data.
For example, if you add a new field to the ‘User’ schema then you can modify the object definition:
{
"type": "record",
"name": "User",
"namespace": "com.example",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": ["null", "string"], "default": null},
{"name": "phone", "type": ["null", "string"], "default": null}
]
}
This new schema is still compatible with data written using the old schema because Avro supports default values for new fields.
Generating Java classes from Avro schemas is a straightforward process that enhances the efficiency and reliability of data serialization in Java applications. By defining your data structure in a schema, using the Avro tools to generate classes, and implementing serialization and deserialization logic, you can seamlessly integrate Avro into your projects. The ability to evolve schemas without breaking compatibility makes Avro a robust choice for applications that require flexible and efficient data handling without the overhead of roundtrip engineering.
5. Conclusion
In conclusion, generating Java classes from Avro schemas using Gradle provides a seamless and efficient workflow for integrating Avro serialization into your Java projects. By defining your data structures in Avro schema files and leveraging Gradle’s build automation capabilities, you streamline the process of generating the necessary Java classes.
This approach enhances development speed and ensures type safety and consistency across your application. Furthermore, the ease of updating schemas and regenerating classes means you can adapt to evolving data requirements without significant overhead. Embracing this methodology equips you with a robust solution for handling data serialization in a scalable and maintainable manner, ultimately contributing to more efficient and reliable software development.
6. Download
You can download the full source code of this example here: Generate Java Classes From Avro Schemas Using Gradle
