The following post is based on a talk I gave at Desert Code Camp 2013. See also the associated slide deck.
Software quality is critical to consistently and continually delivering new features to our users. This articles covers the importance of software quality and how to deliver it via unit testing, Test Driven Development and clean code in general.
Introduction
Unit testing has raised the quality of my code more than any other technique, approach or tool I have come across in the last 15 years. It helps you to write cleaner
code, more quickly and with less bugs. It is also just feels good to write unit tests. That green bar in JUnit (or whatever testing tool you are using), gives you a warm fuzzy feeling. So, the bulk of this talk/article is about unit testing, and it’s smarter cousin, TDD.
There are however, many other steps you can take, outside of unit testing, to improve the quality of code; Simple things such as:
- good variable names
- short cohesive methods that are easy to understand at a glance
- avoiding code smells such as long nested if else if blocks
So, the final section of my talk will be on what some people call ‘Clean Code’.
But we’ll start by talking about why all this is important. After all, design, clean code and unit tests are merely an means to an end. And that end is: delivering value to users And we should never forget that fact!
It is very important to be able to explain to project stakeholders, or indeed other developers, what the motivations and advantages are of unit testing and clean code, and how it ultimately results in value to users. And so, that is the basis for the introductory section called ‘The value of software design’.
- The value of software design
- Automated testing
- Clean code
1. The value of software design
This section is largely based on a talk (key part starts around 45:00; see also the paper) I was fortunate enough to attend by a guy called Martin Fowler, the ‘Chief Scientist’ at a company called ThoughtWorks. In the talk, Fowler did a great job of answering a question I had been thinking about a lot: Why should we care about ‘good’ design in software?
People may put forward questions and statements such as
- We need less focus on quality so we can add more features
- Do we really need unit tests?
- Refactoring doesn’t change what the code does, so why bother?
And it can be difficult to answer those questions, particularly when you are under pressure to deliver, and quickly. On approach is to take the high moral ground. For example, there are people who adopt the attitude that
- Bad software design is a sin
- If you are not writing unit tests, with 100% unit test code coverage, you are a BAD developer
- Poorly named variables or methods will be branded on your flesh as you burn in the fiery pits of hell for your sins
Basically, treat the issue as a moral one – you are a bad person (or at least a bad developer) if you are designing poor quality software.
However, most of us work for a living, and if we are going to take the time and effort to produce quality software, we need to have an economic reason for doing it – otherwise, why bother? If the software we are writing is not least providing significant benefit to our users and stakeholders, we probably shouldn’t be doing it. Remember our goal: Deliver value to users
What does Quality even mean?
But before we get into what economic reasons for good software design are, let’s talk about what Quality even means when it comes to software?
Well, it could mean a few different things, including:
- Quality GUI (easy to use, looks good, intuitive)
- Few defects (bug free, no unintelligible error messages
- Good modular design
However, only the top two are actually apparent to users/customers/business sponsors. And yet this talk/article focuses almost exclusively on the last one – the one that users have no concept of!
And it’s not just users; Does your manager stay awake at night worrying about the quality of the code that you’re producing? Probably not. I bet your manager’s manager definitely doesn’t! And your CEO probably doesn’t even know what code is.
So if management and users don’t care about quality code, why should we, as developers care?
Fowler’s Design Stamina Hypothesis
Well Martin Fowler did a good job of describing why using what he calls the Design Stamina Hypothesis.
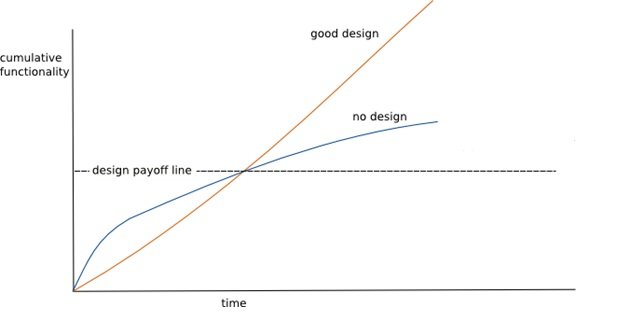
- The y axis represents how much new functionality you are adding to the app
- The x axis represents time
- The orange line represents a hypothetical scenario where you create an app with no design (and design definitely includes unit tests)
- The blue line represents a scenario where you create an app with good design
Without design
Fowler’s Design Stamina Hypothesis basically says that if you write code without a good design, you will be able to deliver code very quickly to start with, but your progress will become slower and slower over time and it becomes more and more difficult to add new features as you become bogged down
- in spaghetti code
- fixing bugs introduced when you inadvertently broke an piece of code you couldn’t understand
- spending hours trying to understand code before actually being able to change it (and still have little confidence that you’re not messing it up)
In the worst case sceanario (shown above by the blue line tapering off), it will become so slow to make changes that you will likely start to consider a complete rewrite of the application. Because rewriting the entire thing, and the months/years of effort and blood/sweat/tears that that will take is actually more attractive that dealing with the mess you have created.
So, how do we avoid that worst case scenario, and what economic benefits can we reap?
With good design
Well, the second part of Fowler’s Design Stamina Hypothesis is how cumulative functionality is affected by good design. Designing, writing tests, using TDD may take a little longer in the short term, but the benefit is that in the medium to longer term [the point on the graph at which the lines cross), it actually makes you much faster.
- Adding new features takes about as long as you’d expect it to
- Ever junior developers, or new team members, can add new features in a reasonable amount of time
And in many cases that point is after days or weeks rather than months or years.
Design Stamina Hypothesis summary
In agile software development, the term often used to describe the amount of new functionality added over a period of time is velocity. Fowler’s notion on good design increasing velocity is just an hypothesis because it can’t be (easily) proved, but it intuitively makes sense to most people involved in producing software.
Design Stamina Hypothesis: Design is what gives us the stamina to be able to continually add new features to an application, today, tomorrow and for months and years to come.
Technical debt
Basically what Fowler is talking about here is the concept of technical debt. Technical debt is a metaphor referring to the eventual consequences of poor design in a codebase. The debt can be thought of as extra work that needs to be done before or in addition to the real work that you need to do. For example, having to improve a design before you can actually add the new feature users have requested.
Under the technical debt metaphor, that extra work can be thought of as interest payments.
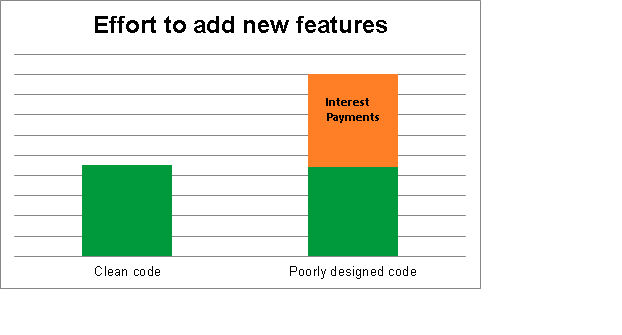
Interest payments can come in the form of
- Bugs
- Just understanding what the heck the current code does
- Refactoring
- Completing unfinished work
How to deal with technical debt
When you encounter technical debt in a project, you basically have 2 options open to you: Pay down or accept. Paying down the debt involves spending extra time to clean, refactor and improve design. The benefit is that it will ultimately speed you up since you’ll be able to add new features faster. The downside is that it will inevitably slow you down now.
Accepting the debt means doing the minimum required to add/change features and moving on. The interest you will pay going forward is the additional cost you incur above and beyond adding new features; Everything is slowed down and complicated by the extra complexity. In addition, it is also much more difficult for a new dev on the team to pick up. And last but by no means least, developer morale suffers! No developer enjoys working in an unmaintainable mess of code; And developer turnover is a very real cost.
So, when we come across code in our projects that is poorly designed, should we take action? Refactor, add tests, tidy up?
For a long time, I thought the answer to that question was simply Yes. Always. However, Fowler makes an excellent point that it is not always economically sensible to do so.
If it ain’t broken, don’t fix it
Even of a module is a bunch of crap; Badly written, with no tests and poor variable names etc; If it
- (surprisingly) doesn’t have any bugs in it
- does what it is supposed to
- AND If you never need to change
Then why worry about it? In technical debt terms, it is not exerting very many interest payments.
Don’t build bad on top of bad
On the other hand, if that badly written code needs to be updated with functionality, or if you find yourself ‘in it’ all the time (even just to understand it), then it becomes important to pay down technical debt and to keep the code clean and easy to maintain & enhance
Summary of the value of software design
Good Design, tests and good coding practices etc, are only a means to an end and that end is delivering value users. However, they are very useful in meeting that end. They give us the stamina to continually and consistently deliver functionality faster, with less bugs to our users and so have very real economic benefits
And with that, let’s look at what it means to actually use good design techniques via the use of automated tests for software…
2. Automated testing
Unit testing
A unit test is a piece of code that executes a specific functionality (‘unit’) in the code, and
- Confirms the behavior or result is as expected.
- Determines if code is ‘fit for use’
Unit testing example
It is easiest to explain via an example. This example involves testing a factorial routine. The factorial of a non-negative integer n, denoted by n!, is the product of all positive integers less than or equal to n. For example, the factorial of 3 is equal to 6: 3! = 3 x 2 x 1 = 6
Our implementation of this is as follows:public class Math {
public int factorial(int n) {
if (n == 1) return 1;
return n * factorial(n-1);
}
}And being good developers, we add a test to make sure the code does what we expect:
public class MathTest {
@Test
public void factorial_positive_integer() {
Math math = new Math();
int result = math.factorial(3);
assertThat(result).isEqualTo(6);
}
}And if we run the test, we will see it passes. Our code must be correct?
Well one good thing about tests is that they make you start to think about edge cases. Anobvious one here is zero. So we add a test for that. In mathematics, the factorial of zero is 1 (0! = 1), so we add a test for that:
public class MathTest {
…
@Test
public void factorial_zero() {
Math math = new Math();
int result = math.factorial(0);
assertThat(result).isEqualTo(1);
}
}And when we run this test… we see that it fails. Specifically, it will result in some kind of stack overflow. We have found a bug!
The issue is our exit condition, or the first line in our algorithm:
if (n == 1) return 1;
This needs to be updated to check for zero:
if (n == 0) return 1;
With our algorithm updated, we re-run our tests and all pass. Order is restored to the universe!
What unit tests provide
Although our previous example demonstrated unit tests finding a bug, find bugs isn’t the unit tests primary benefit. Instead, unit tests:
- Drive design
- Act as safety buffers by finding regression bugs
- Provide documentation
Drive design
TDD can help drive design and tease the requirements out. The tests effectively act as the first user of the code, making you think about:
- what should this code do
- Border conditions (0, null, -ve, too big)
They can also push you to use good design, such as
- Short methods
- difficult to unit test a methid that is 100 lines long, so unit esting forces you to write modular code (low coupling, high cohesion;
- Test names can highlight violations of SRP; if you start writing a test name like addTwoNumbers_sets_customerID correctly, you are probably doing something very wrong
- Dependency Injection
Basically, writing a class is different from using a class and you need to be aware of that as you write code.
Act as safety buffers by finding regression bugs
Have you ever been in a bowling alley and seen those buffers or bumpers they put down the side of each lane for beginners or kids, to stop the ball running out? Well unit tests are kind of like that. They act as a safety net by allowing code to be refactored without fear of breaking existing functionality.
Having a high test coverage of your code allows you to continue developing features without having to perform lots of manual tests. When a change introduces a fault, it can be quickly identified and fixed.
Regression testing (checking existing functionality to ensure it hasn’t been broken by later modifications to the code) is one of the biggest benefits to Unit Testing – especially when you’re working on a large project where developers don’t know the ins and outs of every piece of code and hence are likely to introduce bugs by incorrectly working with code written by other developers.
Unit tests are run frequently as the code base is developed, either as the code is changed or via an automated process with the build. If any of the unit tests fail, it is considered to be a bug either in the changed code or the tests themselves.
Documentation
Another benefit of unit testing is that it provides a form of living documentation about how the code operates. Unit test cases embody characteristics that are critical to the success of the unit. The test method names provide a succinct description of what a class does.
Unit testing limitations
Unit testing of course has its limitations:
- Can not prove the absence of bugs
While unit tests can prove the presence of bugs, they can never prove their absence (They can prove the absence of specific bugs, yes, but not all bugs). For example, unit tests test what you tell them too. If you don’t think of an edge case, you probably aren’t going to write either a test of the functionality to handle it! For reasons like this, unit tests should augment, never replace, manual testing.
- Lot’s of code (x3-5)
In the simple unit test example we saw earlier, the unit tests had about 3 times the amount of code as the actual code under test – and there were still other scenarios we hadn’t tested yet. In general, for every line of code written, programmers often need 3 to 5 lines of test code. For example, every boolean decision statement requires at least two tests. Test code quickly builds up and it all takes time to write, read and maintain, and run.
- Some things difficult to test
Some things are extremely difficult to test e.g. threading, GUI.
- Testing legacy code bases can be challenging
A common approach to adding unit testing to existing code is to start with one wrapper test, then simultaneously refactor and add tests as you go along. For example if you have a legacy method that has 200 lines of code, you might start by adding one test that, for a given set of parameters gives you a certain return value. This will not test all the side effects the method has (e.g. the effect of calls to other objects), but it is a starting point. You can then start refactoring the method down into smaller methods, adding unit tests as you do so. The initial ‘wrapper’ test will give you some degree of confidence that you have not fundamentally broken the original functionality and the new incremental tests you add as you go about refactoring will give you increased confidence, as well as allowing you to understand (and document) the code.
It is worth pointing out though that in some cases, the setup for objects not originally designed with unit testing in mind can be more trouble than it is worth. In these cases, you need to make the kind of decisions we discuss earlier in the technical debt section.
So, given all those limitations, should we unit test? Absolutely! In fact, not only should we unit test, we should let unit tests drive development and design, via Test Driven Development (TDD).
Test driven development
TDD Intro
Test-driven development is a set of techniques which encourages simple designs and test suites that inspire confidence.
The classic approach to TDD is Red – Green – Refactor
- Red— Write a failing test, one that may not even compile at first
- Green— Make the test pass quickly, committing whatever sins necessary in the process
- Refactor— Eliminate all of the duplication created in merely getting the test to work
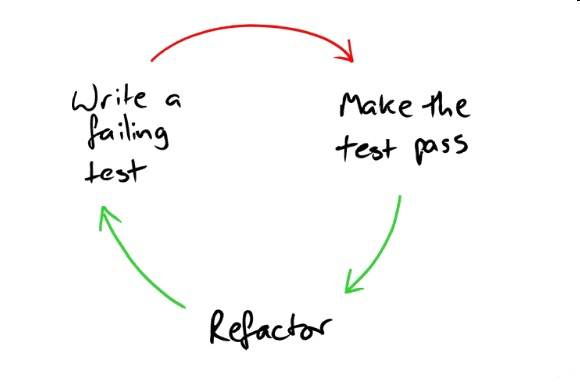
Red- green/refactor—the TDD mantra.
No new functionality without a failing test; no refactoring without passing tests.
TDD Example
As with straight unit testing, TDD is best explained via an example. However, this section is best viewed as code screen shots. See the presentation slides here.
A few points are worth noting from the TDD example:
- Writing the tests resulted in code that is clean and easy to understand; likely more so than if we had added tests after the fact (or not at all)
- The test names act as a good form of documentation
- Finally, there is about five times more test code than the code we were testing, as we predicted earlier. This emphasizes why it is so important to refactor the test code just as, it not more, aggressively than the actual code under test.
So far we have looked why we should be concerned with good design in the first place, and how we can use automated tests to drive and confirm our design.
Next, we are going to talk about how to spot issues with an existing code base by looking for code smells…
3. Clean code
One way to ensure clean code is by avoiding ‘code smells’.
What is a code smell?
“Certain structures in code that suggest (sometimes they scream for) the possibility of refactoring.” Martin Fowler. Refactoring: Improving the design of existing code
A ‘smell’ in code is a hint that something might be wrong with the code. To quote the Portland Pattern Repository’s Wiki, if something smells, it definitely needs to be checked out, but it may not actually need fixing or might have to just be tolerated. The code that smells may itself need fixing, or it may be a symptom of, or hiding, another issue. Either way, it is worth looking into.
We will look at the following code smells:
- Duplicated code
- Long switch/if statements
- Long methods
- Poor method names
- In-line comments
- Large classes
Duplicated code
This is the #1 stink! It violates the DRY principle.
If you see the same code structure in more than one place, you can be sure that your program will be better if you find a way to unify them.
| Symptom | Possible actions |
| same expression in two methods of the same class | Extract to a new method |
| same expression in two sibling subclasses | Extract to a method in a parent class |
| same expression in two unrelated classes | Extract to a new class? Have one class invoke the other? |
In all cases, parametrize any subtle differences in the duplicated code.
Long switch / if statements
The problem here is also one duplication.
- The same switch statement is often duplicated in multiples places. If you add a new clause to the switch, you have to find all these switch, statements and change them.
- Or similar code being done in each switch statement
The solution is often to use use polymorphism. For example, if you are switching on a code of some kind, move the logic into the class that owns the codes, then introduce code specific subclasses. An alternative is to use the State of Strategy design patterns.
Long method
The longer a method is, the more difficult it is to understand. Older languages carried an overhead in subroutine calls. Modern OO languages have virtually eliminated that overhead.
The key is good naming. If you have a good name for a method you don’t need to look at the body.
Methods should be short (<10 line)
A one line method seems a little too short, but even this is OK if it adds clarity to the code.
Be aggressive about decomposing methods!
The real key to decomposing methods into shorter ones is avoiding poor method names…
Poor method names
Method names should be descriptive, for example
- int process(int id) { //bad!
- int calculateAccountBalance(int accountID) { //better
i.e. the method name should descibe what the method does without having to read the code or at least, a quick scan of the code should confirm the method does what it says on the tin
In-line comments
Yes, in-line comments can be considered a code smell! If the code is so difficult to follow that you need to add comments to describe it, consider refactoring!
The best ‘comments’ are simply the names you give you methods and variables.
Note however, that Javadocs, particularly on public methods, are fine and good.
Large classes
When a class is trying to do too much, it often shows up as:
- Too many methods (>10 public?)
- Too many lines of code
- Too many instance variables – is every instance variable used in every method?
Solutions
- Eliminate redundancy / duplicated code
- Extract new/sub classes
Clean code summary
The single most important thing is to make the intent of your code clear.
Your code should be clear, concise and easy to understand because although a line of code is written just once, it is likely to be read many times.
Will you be able to understand your intent in a month or two? Will your colleague? Will a junior developer?
A software program will have, on average, 10 generations of maintenance programmers in its lifetime.
Maintaining such unreadable code is hard work because we expend so much energy into understanding what we’re looking at. It’s not just that, though. Studies have shown that poor readability correlates strongly with defect density. Code that’s difficult to read tends to be difficult to test, too, which leads to fewer tests being written.
Summary
- Good design gives us the stamina to continually and consistently deliver business value
- Unit tests are an integral part of good design; TDD is even better
- Good design can also simply be cleaner code; Aggressively refactor to achieve this
Final thought: Every time you are in a piece of code, just make one small improvement!

Writing tests is essential, but the trick is to write the right tests and in the right way! :) Recently I have published a (free) book “Bad Tests, Good Tests” (see http://practicalunittesting.com) which includes many examples of imperfect tests and discusses ways of improving them. I guess you might be interested to have a look at them.
The orange line should be referenced as blue and vice versa during explanation below the figure.