Parallel Scavenge
Today we cover how Parallel GC works. Specifically this is the combination of running a Parallel Scavenge collector over Eden and the Parallel Mark and Sweep collector over the Tenured generation. You can get this option by passing in -XX:+UseParallelOldGC though its the default on certain machine types.
You may want to read my first blog post on Garbage Collection if you haven’t since this gives a general overview.
Eden and Survivor Spaces
In the parallel scavenge collector eden and survivor spaces are collected using an approach known as Hemispheric GC. Objects are initially allocated in Eden, once Eden is close to full 1 a gc of the Eden space is triggered. This identifies live objects and copies them to the active Survivor Space2. It then treats the whole Eden space as a free, contiguous, block of memory which it can allocate into again.
In this case the allocation process ends up being like cutting a piece of cheddar. Each chunk gets sliced off contiguously and then the slice next to is the next to be ‘eaten’. This has the upside that allocation merely requires pointer addition.

In order to identify live objects a search of the object graph is undertaken. The search starts from a set of ‘root’ objects which are objects that are guaranteed to be live, for example every thread is a root object. The search then find objects which are pointed to by the root set, and expands outwards until it has found all live objects. Here’s a really nice pictorial representation, courtesy of Michael Triana
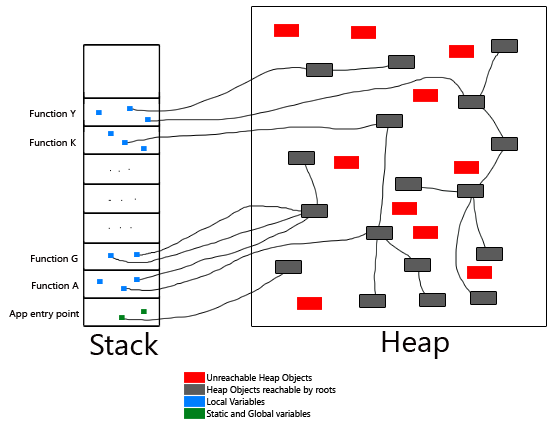
Parallel in the context of parallel scavenge means the collection is done by multiple threads running at the same time. This shouldn’t be confused with incremental GC, where the collector runs at the same time as, or interleaved with, the program. Parallel collection improves overall GC throughput by better using modern multicore CPUs. The parallelism is achieved by giving each thread a set of the roots to mark and a segment of the table of objects.
There are two survivor spaces, but only one of them is active at any point in time. They are collected in the same way as eden. The idea is that objects get copied into the active survivor space when they are promoted from eden. Then when its time to evacuate the space they are copied into the inactive survivor space. Once the active survivor space is completely evacuated the inactive space becomes active, and the active space becomes inactive. This is achieve by flipping the pointer to the beginning of the survivor space and means that all the dead objects in the survivor space can be freed at the cost of assigning to a single pointer.
Young Gen design and time tradeoffs
Since this involves only copying live objects and pointer changes the time taken to collect eden and survivor spaces is proportional to the amount of live objects. This is quite important since due to the generational hypothesis we know that most objects die young, and there’s consequently no GC cost to freeing the memory associated with them.
The design of the survivor spaces is motivated by the idea that collecting objects when they are young is cheaper than doing a collection of the tenured space. Having objects continue to be collected in a hemispheric fashion for a few GC runs is helpful to the overall throughput.
Finally the fact that eden is organised into a single contiguous space makes object allocation cheap. A C program might back onto the ‘malloc’ command in order to allocate a block of memory, which involves traversing a list of free spaces in memory trying to find something that’s big enough. When you use an arena allocator and consecutively allocate all you need to do is check there is enough free space and then increment a pointer by the size of the object.
Parallel Mark and Sweep
Objects that have survived a certain number of collections make their way into the tenured space. The number of times that they need to survive is referred to as the ‘tenuring threshold’. Tenured Collections work somewhat differently to Eden, using an algorithm called mark and sweep. Each object has a mark bit associated with it. The marks are initially all set to false and as the object is reached during the graph search they’re set to true.
The graph search that identifies live objects is similar to the search described for young generation. The difference is that instead of copying live objects, it simply marks them. After this it can go through the object table and free any object that isn’t live. This process is done in parallel by several threads, each search a region of the heap.
Unfortunately this process of deleting objects that aren’t live leaves the tenured space looking like Swiss Cheese. You get some used memory where objects live, and gaps in between where objects used to live. This kind of fragmentation isn’t helpful for application performance because it makes it impossible to allocate objects that are bigger than the size of the holes.

In order to reduce the Swiss Cheese problem the Parallel Mark/Sweep compacts the heap down to try and make live objects contiguously allocated at the start of the tenured space. After deletion it search areas of the tenured space in order to identify which have low occupancy and which have high occupancy. The live objects from lower occupancy regions are moved down towards regions that have higher occupancy. These are naturally at the lower end of memory from the previous compacting phase. The moving of objects in this phase is actually performed by the thread allocated to the destination region, rather than the source region.

Summary
- Parallel Scavenge splits heap up into 4 Spaces: eden, two survivor spaces and tenured.
- Parallel Scavenge uses a parallel, copying collector to collector Eden and Survivor Spaces.
- A different algorithm is used for the tenured space. This marks all live objects, deletes the dead objects and then compacts the space/
- Parallel Scavenge has good throughput but it pauses the whole program when it runs.
In part three I’ll look at how the CMS, or Concurrent-Mark-Sweep, collector works. Hopefully this post will be easier for those with dairy allergies to read.
- Technically there is an ‘occupancy threshold’ for each heap space – which defines how full the space is allowed to get before collection occurs.
- This copying algorithm is based on Cheney’s algorithm.

Garbage collection with parallel collector is much faster that serial collector. As you know today almost all Java applications run on machines with a lot of physical memory and multiple CPUs. The parallel collector, also known as the throughput collector, was developed in order to take advantage of available CPUs rather than leaving most of CPU processes idle. Therefore throughput of parallel collector is much better than serial collector. If you are not aware about garbage collection fundamentals and object generations, then I will recommend you to first read my blog
To Read More Click Here
http://www.somanyword.com/2014/01/parallel-garbage-collector-in-java/
Garbage collection with parallel collector is much faster that serial collector. As you know today almost all Java applications run on machines with a lot of physical memory and multiple CPUs. The parallel collector, also known as the throughput collector, was developed in order to take advantage of available CPUs rather than leaving most of CPU processes idle. Therefore throughput of parallel collector is much better than serial collector.
To Read More Click Here
http://www.somanyword.com/2014/01/parallel-garbage-collector-in-java/
Thanks, nice post