I’ve just done some high level documentation for the new rule algorithm I’ve called PHREAK, a word play on Hybrid Reasoning. It’s still a bit rough and high level, but hopefully still interesting. It builds on ReteOO, so good to read that bit first.
ReteOO Algorithm
The ReteOO was developed throughout the 3, 4 and 5 series releases. It takes the RETE algorithm and applies well known enhancements, all of which are covered by existing academic literature:
- Node sharing
Sharing is applied to both the alpha and beta network. The beta network sharing is always from the root pattern.
- Alpha indexing
Alpha Nodes with many children use a hash lookup mechanism, to avoid testing each result.
- Beta indexingJoin, Not and Exist nodes indexing their memories using a hash. This reduces the join attempts for equal checks. Recently range indexing was added to Not and Exists.
- Tree based graphs
Join matches did not contain any references to their parent or children matches. Deletions would have to recalculate all join matches again, which involves recreating all those join match objects, to be able to find the parts of the network where the tuples should be deleted. This is called symmetrical propagation. A tree graph provides parent and children references, so a deletion is just a matter of following those references. This is asymmetrical propagation. The result is faster and less impact on the GC, and more robust because changes in values will not cause memory leaks if they happen without the engine being notified.
- Modify-in-place
Traditional RETE implements a modify as a delete + insert. This causes all join tuples to be GC’d, many of which are recreated again as part of the insert. Modify-in-place instead propagates as a single pass, every node is inspected
- Property reactive
Also called “new trigger condition”. Allows more fine grained reactivity to updates. A Pattern can react to changes to specific properties and ignore others. This alleviates problems of recursion and also helps with performance.
- Sub-networks
Not, Exists and Accumulate can each have nested conditional elements, which forms sub-networks.
- Backward Chaining
Prolog style derivation trees for backward chaining are supported. The implementation is stack based, so does not have method recursion issues for large graphs.
- Lazy Truth Maintenance
Truth maintenance has a runtime cost, which is incurred whether TMS is used or not. Lazy TMS only turns it on, on first use. Further it’s only turned on for that object type, so other object types do not incur the runtime cost.
- Heap based agenda
The agenda uses a binary heap queue to sort rule matches by salience, rather than any linear search or maintenance approach.
- Dynamic Rules
Rules can be added and removed at runtime, while the engine is still populated with data.
PHREAK Algorithm
Drools 6 introduces a new algorithm, that attempts to address some of the core issues of RETE. The algorithm is not a rewrite form scratch and incorporates all of the existing code from ReteOO, and all it’s enhancements. While PHREAK is an evolution of the RETE algorithm, it is no longer classified as a RETE implementation. In the same way that once an animal evolves beyond a certain point and key characteristics are changed, the animal becomes classified as new species. There are two key RETE characteristics that strongly identify any derivative strains, regardless of optimizations. That it is an eager, data oriented algorithm. Where all work is done during the insert, update or delete actions; eagerly producing all partial matches for all rules. PHREAK in contrast is characterised as a lazy, goal oriented algorithm; where partial matching is aggressively delayed.
This eagerness of RETE can lead to a lot of churn in large systems, and much wasted work. Where wasted work is classified as matching efforts that do not result in a rule firing.
PHREAK was heavily inspired by a number of algorithms; including (but not limited to) LEAPS, RETE/UL and Collection-Oriented Match. PHREAK has all enhancements listed in the ReteOO section. In addition it adds the following set of enhancements, which are explained in more detail in the following paragraphs.
- Three layers of contextual memory; Node, Segment and Rule memories.
- Rule, segment and node based linking.
- Lazy (delayed) rule evaluation.
- Isolated rule evaluation.
- Set oriented propagations.
- Stack based evaluations, with pause and resume.
When the PHREAK engine is started all rules are said to be unlinked, no rule evaluation can happen while rules are unlinked. The insert, update and deletes actions are queued before entering the beta network. A simple heuristic, based on the rule most likely to result in firings, is used to select the next rule for evaluation; this delays the evaluation and firing of the other rules. Only once a rule has all right inputs populated will the rule be considered linked in, although no work is yet done. Instead a goal is created, that represents the rule, and placed into a priority queue; which is ordered by salience. Each queue itself is associated with an AngendaGroup. Only the active AgendaGroup will inspect it’s queue, popping the goal for the rule with the highest salience and submitting it for evaluation. So the work done shifts from the insert, update, delete phase to the fireAllRules phase. Only the rule for which the goal was created is evaluated, other potential rule evaluations from those facts are delayed. While individual rules are evaluated, node sharing is still achieved through the process of segmentation, which is explained later.
Each successful join attempt in RETE produces a tuple (or token, or partial match) that will be propagated to the child nodes. For this reason it is characterised as a tuple oriented algorithm. For each child node that it reaches it will attempt to join with the other side of the node, again each successful join attempt will be propagated straight away. This creates a descent recursion effect. Thrashing the network of nodes as it ripples up and down, left and right from the point of entry into the beta network to all the reachable leaf nodes.
PHREAK propagation is set oriented (or collection-oriented), instead of tuple oriented. For the rule being evaluated it will visit the first node and process all queued insert, update and deletes. The results are added to a set and the set is propagated to the child node. In the child node all queued inset, update and deletes are processed, adding the results to the same set. Once finished that set is propagated to the next child node, and so on until the terminal node is reached. This creates a single pass, pipeline type effect, that is isolated to the current rule being evaluated. This creates a batch process effect which can provide performance advantages for certain rule constructs; such as sub-networks with accumulates. In the future it will leans itself to being able to exploit multi-core machines in a number of ways.
The Linking and Unlinking uses a layered bit mask system, based on a network segmentation. When the rule network is built segments are created for nodes that are shared by the same set of rules. A rule itself is made up from a path of segments, although if there is no sharing that will be a single segment. A bit-mask offset is assigned to each node in the segment. Also another bit-mask (the layering) is assigned to each segment in the rule’s path. When there is at least one input (data propagation) the node’s bit is set to on. When each node has it’s bit set to on the segment’s bit is also set to on. Conversely if any node’s bit is set to off, the segment is then also set to off. If each segment in the rule’s path is set to on, the rule is said to be linked in and a goal is created to schedule the rule for evaluation. The same bit-mask technique is used to also track dirty node, segments and rules; this allows for a rule already link in to be scheduled for evaluation if it’s considered dirty since it was last evaluated.
This ensures that no rule will ever evaluate partial matches, if it’s impossible for it to result in rule instances because one of the joins has no data. This is possible in RETE and it will merrily churn away producing martial match attempts for all nodes, even if the last join is empty.
While the incremental rule evaluation always starts from the root node, the dirty bit masks are used to allow nodes and segments that are not dirty to be skipped.
Using the existence of at at least one items of data per node, is a fairly basic heuristic. Future work would attempt to delay the linking even further; using techniques such as arc consistency to determine whether or not matching will result in rule instance firings.
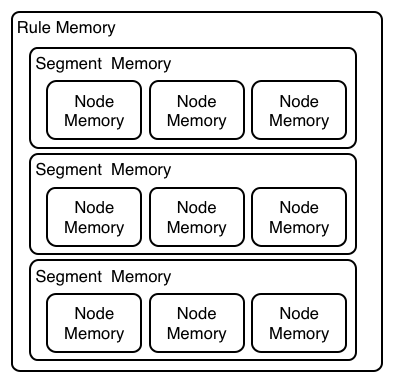
Where as RETE has just a singe unit of memory, the node memory, PHREAK has 3 levels of memory. This allows for much more contextual understanding during evaluation of a Rule.
PHREAK 3 Layered memory system
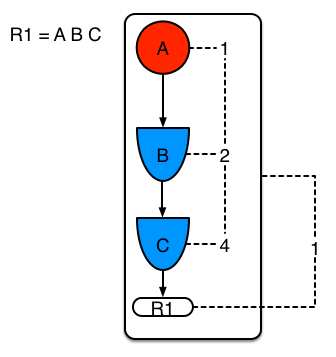
Example 1 shows a single rule, with three patterns; A, B and C. It forms a single segment, with bits 1, 2 and 4 for the nodes.
Example 1: Single rule, no sharing
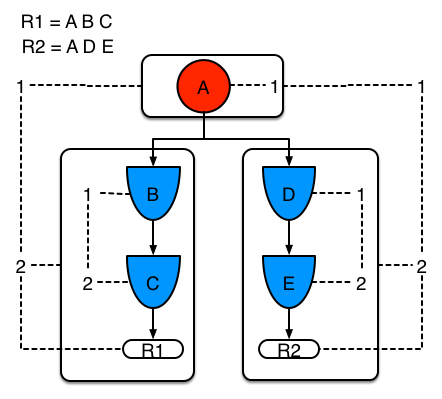
Example 2 demonstrates what happens when another rule is added that shares the pattern A. A is placed in it’s own segment, resulting in two segments per rule. Those two segments form a path, for their respective rules. The first segment is shared by both paths. When A is linked the segment becomes linked, it then iterates each path the segment is shared by, setting the bit 1 to on. If B and C are later turned on, the second segment for path R1 is linked in; this causes bit 2 to be turned on for R1. With bit 1 and bit 2 set to on for R1, the rule is now linked and a goal created to schedule the rule for later evaluation and firing.
When a rule is evaluated it is the segments that allow the results of matching to be shared. Each segment has a staging memory to queue all insert, update and deletes for that segment. If R1 was to evaluated it would process A and result in a set of tuples. The algorithm detects that there is a segmentation split and will create peered tuples for each insert, update and delete in the set and add them to R2’s staging memory. Those tuples will be merged with any existing staged tuples and wait for R2 to eventually be evaluated.
Example 2: Two rules, with sharing
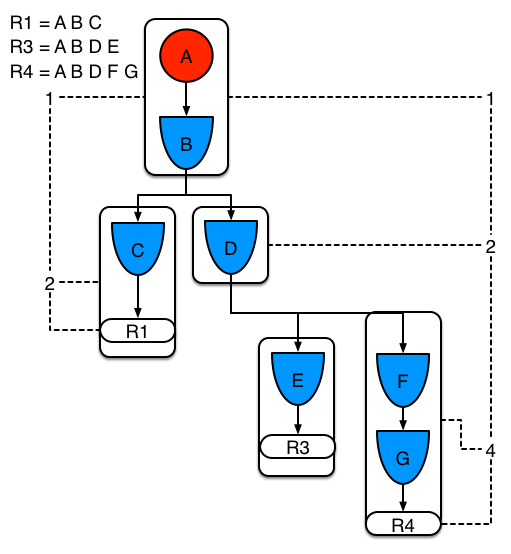
Example 3 adds a third rule and demonstrates what happens when A and B are shared. Only the bits for the segments are shown this time. Demonstrating that R4 has 3 segments, R3 has 3 segments and R1 has 2 segments. A and B are shared by R1, R3 and R4. While D is shared by R3 and R4.
Example 3: Three rules, with sharing
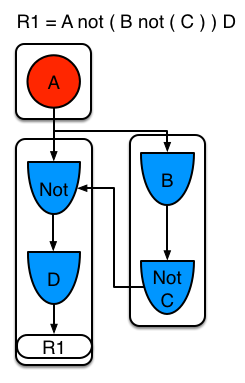
Sub-networks are formed when a Not, Exists or Accumulate node contain more than one element. In Example 4 “B not( C )” forms the sub-network, note that “not(C)” is a single element and does not require a sub network and is merged inside of the Not node.
The sub-network gets its own segment. R1 still has a path of two segments. The sub-network forms another “inner” path. When the sub-network is linked in, it will link in the outer segment.
Example 4 : Single rule, with sub-network and no sharing
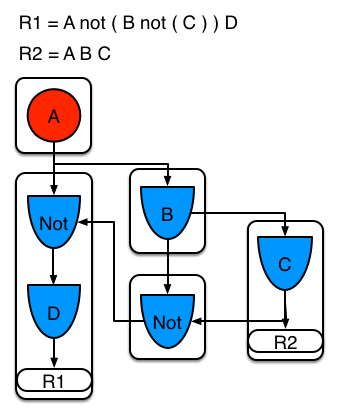
Example 5 shows that the sub-network nodes can be shard by a rule that does not have a sub-network. This results in the subnetwork segment being split into two.
Example 5: Two rules, one with a sub-network and sharing
Not nodes with constraints and accumulate nodes have special behaviour and can never unlink a segment, and are always considered to have their bits on.
All rule evaluations are incremental, and will not waste work recomputing matches that it has already produced.
The evaluation algorithm is stack based, instead of method recursion. Evaluation can be paused and resumed at any time, via the use of a StackEntry to represent current node being evaluated.
When a rule evaluation reaches a sub-network a StackEntry is created for the outer path segment and the sub-network segment. The sub-network segment is evaluated first, when the set reaches the end of the sub-network path it is merged into a staging list for the outer node it feeds into. The previous StackEntry is then resumed where it can process the results of the sub network. This has the added benefit that all work is processed in a batch, before propagating to the child node; which is much more efficient for accumulate nodes.
The same stack system can be used for efficient backward chaining. When a rule evaluation reaches a query node it again pauses the current evaluation, by placing it on the stack. The query is then evaluated which produces a result set, which is saved in a memory location for the resumed StackEntry to pick up and propagate to the child node. If the query itself called other queries the process would repeat, with the current query being paused and a new evaluation setup for the current query node.
One final point on performance. One single rule in general will not evaluate any faster with PHREAK than it does with RETE. For a given rule and same data set, which using a root context object to enable and disable matching, both attempt the same amount of matches and produce the same number of rule instances, and take roughly the same time. Except for the use case with subnetworks and accumulates.
PHREAK can however be considered more forgiving that RETE for poorly written rule bases and with a more graceful degradation of performance as the number of rules and complexity increases.
RETE will also churn away producing partial machines for rules that do not have data in all the joins; where as PHREAK will avoid this.
So it’s not that PHREAK is faster than RETE, it just won’t slow down as much as your system grows.
AgendaGroups did not help in RETE performance, as all rules where evaluated at all times, regardless of the group. The same is true for salience. Which is why root context objects are often used, to limit matching attempts. PHREAK only evaluates rules for the active AgendaGroup, and within that group will attempt to avoid evaluation of rules (via salience) that do not result in rule instance firings.
With PHREAK AgendaGroups and salience now become useful performance tools. The root context objects are no longer needed and potentially counter productive to performance, as they force the flushing and recreation of matches for rules.
