Most applications have at least one batch processing task, executing a particular logic in the background. Writing a batch job is not complicated but there are some basic rules you need to be aware of, and I am going to enumerate the ones I found to be most important.
From an input type point of view, the processing items may come through polling a processing item repository or by being pushed them into the system through a queue. The following diagram shows the three main components of a typical batch processing system:
- the input component (loading items by polling or from an input queue)
- the processor: the main processing logic component
- the output component: the output channel or store where results will sent
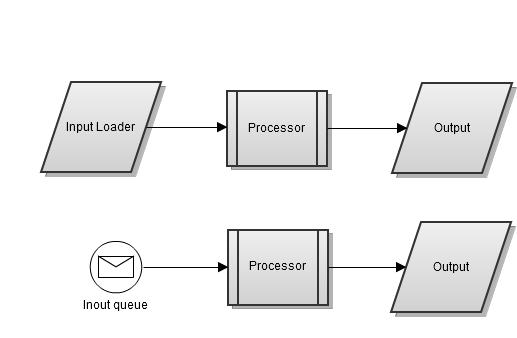
1. Always poll in batches
You should only retrieve a batch of items at a time. I have recently had to diagnose an OutOfMemoryError thrown by a scheduled job while trying to retrieve all possible items for processing.
The system integration tests were passing as they were using small amounts of data, but when the scheduled job was offline for two days because of some deployment issue, the number of items (to be processed) had accumulated since there was no one to consume them, and when the scheduler went back online, it couldn’t consume those, since they didn’t fit the scheduler memory heap. So setting a high scheduling frequency rate is not enough.
To prevent this situation you need to get only a batch of items, consume them, and then you can rerun the process until there is nothing left to process.
2. Write a thread-safe batch processor
Typically a scheduled job should run correctly no matter how many jobs you choose to run in parallel. So the batch processor should be stateless, using only a local job execution context to pass state from one component to the other. Even tread-safe global variables are not so safe after all, since jobs’ data might get mixed up on concurrent executions.
3. Throttling
When using queues (input or within the batch processor) you should always have a throttling policy. If the items producing rate is always higher than the consuming one you are heading for disaster. If the queued items are held in memory, you’ll eventually run out of it. If the items are stored in a persisted queue, you’ll run out of space. So, you need a mechanism of balancing the producers and consumers. As long as the producing rate is finite you just to make sure you have the right number of consumers to balance out the producing rate.
Auto-scaling consumers like starting new ones whenever the queue size grows beyond a given threshold is a suitable adaptive strategy. Killing consumers as the queue size goes below some other threshold allows you to free unnecessary idle threads.
The create-new-consumer threshold should be greater than the kill-idle one because if they were equal you would get a create-kill jitter when the queue size fluctuates around the threshold size.
4. Storing job results
Storing job results in memory is not very thought-out. Choosing a persistence storage (MongoDb capped collection) is a better option.
If the results are held in memory and you forget to limit them to an upper bound, your batch processor will eventually run out of memory. Restarting the scheduler will wipe out your previous job results, and those are extremely valuable, since it’s the only feedback you get.
5. Flooding external service providers
for(GeocodeRequest geocodeRequest : batchRequests) {
mapsService.resolveLocation(geocodeRequest);
}This code is flooding your map provider, since as soon as you finish a request a new one will be issued almost instantly, putting a lot of pressure on their servers. If the batchRequests number is high enough you might get banned.
You should add a short delay between requests, but don’t put your current tread to sleep, use a EIP Delayer instead.
6. Use a EIP style programming for your batch processor
While the procedural style programming is the default mind-set of most programmers, many batch processing tasks fit better on an Enterprise Integration Patterns design. All the aforementioned rules are easier to implement using EIP tools such as:
- message queues
- polling channels
- transformers
- splitters/aggregators
- delayers
Using EIP components eases testing, since you are focusing on a single responsibility at a time. The EIP components communicate through messages conveyed by queues, so changing one synchronous processing channel to a thread-pool dispatched one is just a configuration detail.
For more about EIP you can check the excellent Spring Integration framework. I’ve been using it for three years now, and after you get inoculated you would prefer it over procedural programming.
