If anything at all, our jOOQ talks at various JUGs and conferences have revealed mostly one thing:
Java developers don’t know SQL.
And it isn’t even necessarily our fault. We’re just not exposed to SQL nowadays.
But consider this: We developers (or our customers) are paying millions of dollars every year to Oracle, Microsoft, IBM, SAP for their excellent RDBMS, only to ignore 90% of their database features and to perform a little bit of CRUD and a little bit of ACID with ORMs like Hibernate. We have forgotten about why those RDBMS were so expensive in the first place. We haven’t paid attention to the various improvements to the SQL standards, including SQL:1999, SQL:2003, SQL:2008, and the recent SQL:2011, which are all mostly left unsupported by JPA.
If only we Java developers knew how easy and how much fun it can be to replace thousands of lines of erroneous Java code with five lines of SQL. Don’t believe it? Check this out:
Promoting SQL, the Language
Instead of simply promoting jOOQ, we started to help Java developers appreciate actual SQL, regardless of the access pattern that they’re using. Because true SQL can be appreciated through any of these APIs:
- JDBC
- jOOQ (yeah, shocker, I know)
- Spring’s JDBC extensions
- MyBatis
- Apache DbUtils
- Groovy SQL
How the above APIs can be leveraged in Java 8 can be seen here.
And believe us, most developers were astonished by what was possible in SQL, when they saw our NoSQL? No, SQL! talk:
Calculating a Running Total
So let’s delve into the essence of the talk and calculate a running total with SQL. What’s a running total? It’s easy. Imagine you have these bank account transaction data in your database:
| ID | VALUE_DATE | AMOUNT | |------|------------|--------| | 9997 | 2014-03-18 | 99.17 | | 9981 | 2014-03-16 | 71.44 | | 9979 | 2014-03-16 | -94.60 | | 9977 | 2014-03-16 | -6.96 | | 9971 | 2014-03-15 | -65.95 |
You’ll notice immediately, that the balance per account transaction is missing. Yes, we want to calculate that balance as such:
| ID | VALUE_DATE | AMOUNT | BALANCE | |------|------------|--------|----------| | 9997 | 2014-03-18 | 99.17 | 19985.81 | | 9981 | 2014-03-16 | 71.44 | 19886.64 | | 9979 | 2014-03-16 | -94.60 | 19815.20 | | 9977 | 2014-03-16 | -6.96 | 19909.80 | | 9971 | 2014-03-15 | -65.95 | 19916.76 |
If we’re assuming that we know the current balance on the bank account, we can use each account transaction’s AMOUNT value and subtract it from that current balance. Alternatively, we could assume an initial balance of zero and add up all the AMOUNT value till today. This is illustrated here:
| ID | VALUE_DATE | AMOUNT | BALANCE | |------|------------|--------|----------| | 9997 | 2014-03-18 | 99.17 | 19985.81 | | 9981 | 2014-03-16 | +71.44 |=19886.64 | n | 9979 | 2014-03-16 | -94.60 |+19815.20 | n + 1 | 9977 | 2014-03-16 | -6.96 | 19909.80 | | 9971 | 2014-03-15 | -65.95 | 19916.76 |
Each transaction’s balance can be calculated through either one of these formulas:
BALANCE(ROWn) = BALANCE(ROWn+1) + AMOUNT(ROWn) BALANCE(ROWn+1) = BALANCE(ROWn) – AMOUNT(ROWn)
So, that’s a running total. Easy, right?
But how can we do it in SQL?
Most of us would probably pull out a little Java programme out of their sleeves, keeping all the amounts in memory, writing unit tests, fixing all sorts of bugs (we’re not mathematicians, after all), wrestling with BigDecimals, etc. Few of us would probably go through the hassle of doing the same in PL/SQL or T-SQL, or whatever other procedural language you have at disposition, and possibly update each balance directly into the table when inserting / updating new transactions.
But as you might have guessed so far, the solution we’re looking for here is a solution in SQL. Please bear with us as we’re going through the examples. They’re getting better and better. And if you want to play around with the examples, download Oracle XE and the running-totals.sql script and get up and running!
What we’ve learned from college / SQL-92 would probably involve a…
Using Nested SELECT
Let’s assume that we have a view like v_transactions, which already joins the accounts table to the account transactions table in order to access the current_balance. Here’s how we would write this query, then:
SELECT
t1.*,
t1.current_balance - (
SELECT NVL(SUM(amount), 0)
FROM v_transactions t2
WHERE t2.account_id = t1.account_id
AND (t2.value_date, t2.id) >
(t1.value_date, t1.id)
) AS balance
FROM v_transactions t1
WHERE t1.account_id = 1
ORDER BY t1.value_date DESC, t1.id DESCNotice how the nested SELECT uses row value expression predicates to express the filtering criteria. If your database doesn’t support the SQL standard row value expression predicates (and you’re not using jOOQ to emulate them), you can factor them out yourself to form this equivalent query, instead:
SELECT
t1.*,
t1.current_balance - (
SELECT NVL(SUM(amount), 0)
FROM v_transactions t2
WHERE t2.account_id = t1.account_id
AND ((t2.value_date > t1.value_date) OR
(t2.value_date = t1.value_date AND
t2.id > t1.id))
) AS balance
FROM v_transactions t1
WHERE t1.account_id = 1
ORDER BY t1.value_date DESC, t1.id DESCSo in essence, for any given account transaction, your nested SELECT simply fetches the sum of all AMOUNT values for account transactions that are more recent than the currently projected account transaction.
| ID | VALUE_DATE | AMOUNT | BALANCE | |------|------------|---------|----------| | 9997 | 2014-03-18 | -(99.17)|+19985.81 | | 9981 | 2014-03-16 | -(71.44)| 19886.64 | | 9979 | 2014-03-16 |-(-94.60)| 19815.20 | | 9977 | 2014-03-16 | -6.96 |=19909.80 | | 9971 | 2014-03-15 | -65.95 | 19916.76 |
Does it perform?
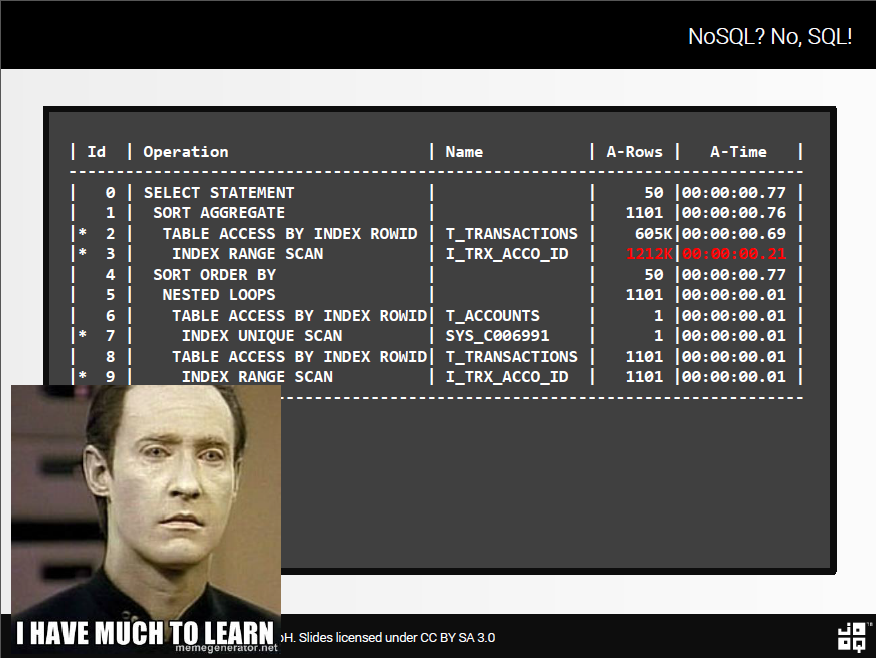
Nope. As you can see, for the relatively simple sample data set (only 1101 records filtered from account_id = 1 in line 9), there is an INDEX RANGE SCAN materialising a whopping total of 1212K rows in memory. This looks like we have O(n2) complexity. I.e. a very naïve algorithm is being applied.
(and don’t think that 770ms is fast for this trivial query!)
While you could probably tune this query slightly, we should still feel that Oracle should be able to devise an O(n) algorithm for this simple task.
Using Recursive SQL
No one enjoys writing recursive SQL. No one. Let me convince you.
For simplicity, we’re assuming that we also have a TRANSACTION_NR column enumerating transactions in their sort order, which can be used to simplify recursion:
| ID | VALUE_DATE | AMOUNT | TRANSACTION_NR | |------|------------|--------|----------------| | 9997 | 2014-03-18 | 99.17 | 1 | | 9981 | 2014-03-16 | 71.44 | 2 | | 9979 | 2014-03-16 | -94.60 | 3 | | 9977 | 2014-03-16 | -6.96 | 4 | | 9971 | 2014-03-15 | -65.95 | 5 |
Ready? Check out this gorgeous piece of SQL!
WITH ordered_with_balance (
account_id, value_date, amount,
balance, transaction_number
)
AS (
SELECT t1.account_id, t1.value_date, t1.amount,
t1.current_balance, t1.transaction_number
FROM v_transactions_by_time t1
WHERE t1.transaction_number = 1
UNION ALL
SELECT t1.account_id, t1.value_date, t1.amount,
t2.balance - t2.amount, t1.transaction_number
FROM ordered_with_balance t2
JOIN v_transactions_by_time t1
ON t1.transaction_number =
t2.transaction_number + 1
AND t1.account_id = t2.account_id
)
SELECT *
FROM ordered_with_balance
WHERE account_id= 1
ORDER BY transaction_number ASCAch… How to read this beauty?
Essentially, we’re self-joining the view (common table expression) that we’re about to declare:
WITH ordered_with_balance (
account_id, value_date, amount,
balance, transaction_number
)
AS (
SELECT t1.account_id, t1.value_date, t1.amount,
t1.current_balance, t1.transaction_number
FROM v_transactions_by_time t1
WHERE t1.transaction_number = 1
UNION ALL
SELECT t1.account_id, t1.value_date, t1.amount,
t2.balance - t2.amount, t1.transaction_number
FROM ordered_with_balance t2
JOIN v_transactions_by_time t1
ON t1.transaction_number =
t2.transaction_number + 1
AND t1.account_id = t2.account_id
)
SELECT *
FROM ordered_with_balance
WHERE account_id= 1
ORDER BY transaction_number ASCIn the first subselect of the UNION ALL expression, we’re projecting the current_balance of the account, only for the first transaction_number.
In the second subselect of the UNION ALL expression, we’re projecting the difference of the balance of the previous account transaction and the AMOUNT of the current account transaction.
WITH ordered_with_balance (
account_id, value_date, amount,
balance, transaction_number
)
AS (
SELECT t1.account_id, t1.value_date, t1.amount,
t1.current_balance, t1.transaction_number
FROM v_transactions_by_time t1
WHERE t1.transaction_number = 1
UNION ALL
SELECT t1.account_id, t1.value_date, t1.amount,
t2.balance - t2.amount, t1.transaction_number
FROM ordered_with_balance t2
JOIN v_transactions_by_time t1
ON t1.transaction_number =
t2.transaction_number + 1
AND t1.account_id = t2.account_id
)
SELECT *
FROM ordered_with_balance
WHERE account_id= 1
ORDER BY transaction_number ASCAnd because we’re recursing into the ordered_with_balance common table expression, this will continue until we reach the “last” transaction.
Now let’s make an educated guess, whether this performs well…
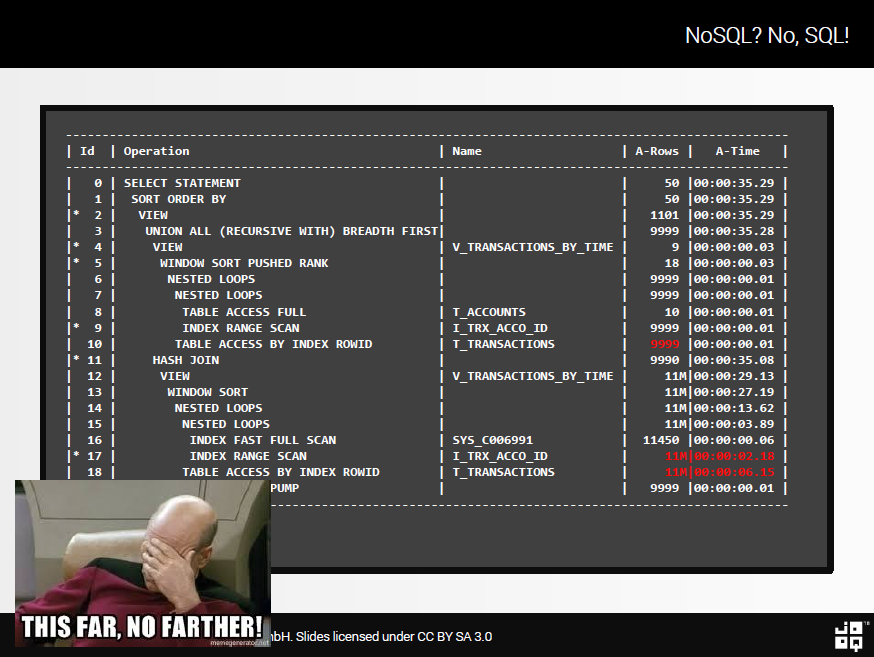
Well. It doesn’t. We get even more rows in memory, namely 11M rows for what should be at most 1101. Parts of this plan are due to the fact that the TRANSACTION_NUMBER utility column is another calculated column that couldn’t be optimised by Oracle. But the essence here is the fact that it is already very hard to get it right, it’s even harder to get it fast.
Using Window Functions
So, we’ve suffered enough. Let’s hear some good news.
There is SQL before window functions, and there is SQL after window functions
– Dimitri Fontaine in this great post
The best solution for this problem is this one:
SELECT
t.*,
t.current_balance - NVL(
SUM(t.amount) OVER (
PARTITION BY t.account_id
ORDER BY t.value_date DESC,
t.id DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND 1 PRECEDING
),
0) AS balance
FROM v_transactions t
WHERE t.account_id = 1
ORDER BY t.value_date DESC,
t.id DESCEssentially, we’re doing exactly the same thing as with the nested SELECT. We’re subtracting the SUM() of all AMOUNT values “over” the subset of rows that is:
- in the same
PARTITIONas the current row (i.e. has the sameaccount_id) - ordered by the same ordering criteria as the account transactions (from the outer query)
- positioned strictly before the current row in the sense of the above ordering
Or, again, visually:
| ID | VALUE_DATE | AMOUNT | BALANCE | |------|------------|---------|----------| | 9997 | 2014-03-18 | -(99.17)|+19985.81 | | 9981 | 2014-03-16 | -(71.44)| 19886.64 | | 9979 | 2014-03-16 |-(-94.60)| 19815.20 | | 9977 | 2014-03-16 | -6.96 |=19909.80 | | 9971 | 2014-03-15 | -65.95 | 19916.76 |
And now, does this perform?
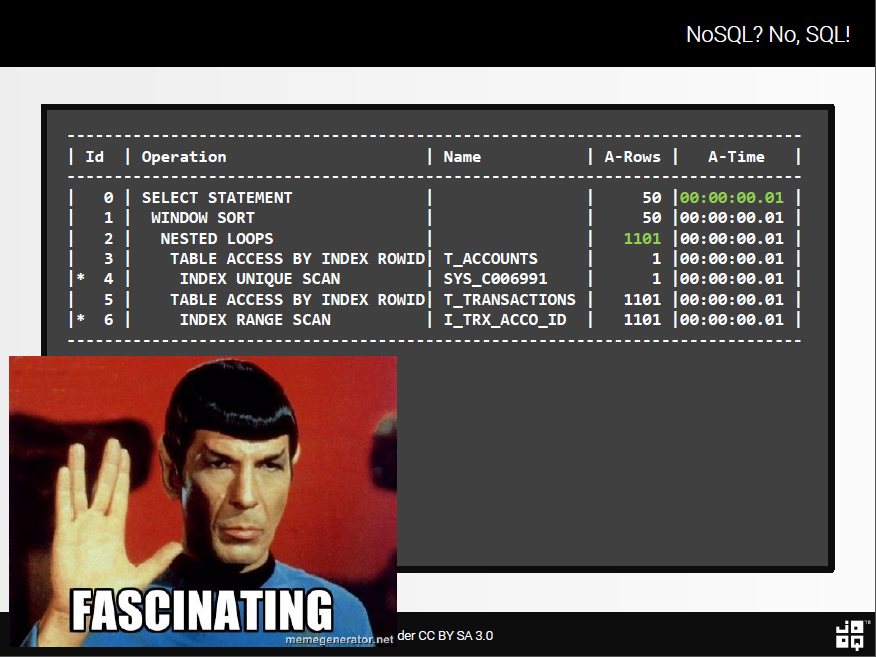
Hallelujah!
It couldn’t be much faster! Window functions are probably the most underestimated SQL feature.
Using the Oracle MODEL Clause
Now, this is more of a special treat for those SQL nerds among you who want to piss off your fellow developers with eerie, weird-looking SQL. The MODEL clause (only available in Oracle).
SELECT account_id, value_date, amount, balance
FROM (
SELECT id, account_id, value_date, amount,
current_balance AS balance
FROM v_transactions
) t
WHERE account_id = 1
MODEL
PARTITION BY (account_id)
DIMENSION BY (
ROW_NUMBER() OVER (
ORDER BY value_date DESC, id DESC
) AS rn
)
MEASURES (value_date, amount, balance)
RULES (
balance[rn > 1] = balance[cv(rn) - 1]
- amount [cv(rn) - 1]
)
ORDER BY rn ASCNow, how to read this beast? We’re taking the sample data and transforming it to:
- be
PARTITION‘ed by the usual criteria - be
DIMENSION‘ed along the sort order, i.e. the transaction row number - be
MEASURE‘ed, i.e. to provide calculated values for date, amount, balance (where date and amount remain untouched, original data) - be calculated according to
RULES, which define the balance of each transaction (except for the first one) to be the balance of the previous transaction minus the amount of the previous transaction
Still too abstract? I know. But think about it this way:
MS Excel! Every time you have a problem that your project manager thinks is peanuts to solve with his fancy MS Excel spreadsheets, then the MODEL clause is your friend!
And does it perform?
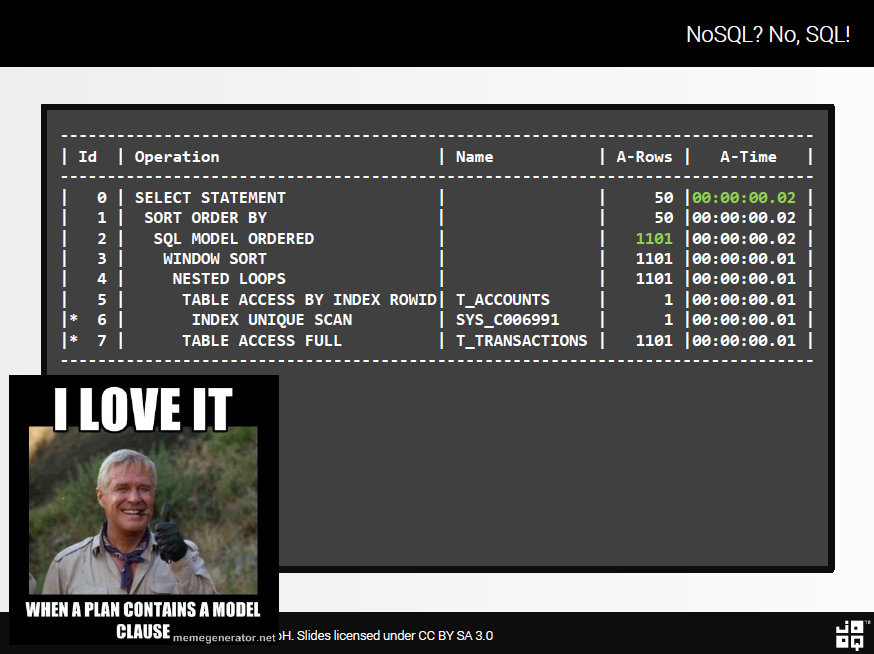
… pretty much so (although the above shouldn’t be confused with an actual benchmark).
If you haven’t seen enough, see another great use-case for the MODEL clause here. And for all the details, consider reading Oracle’s official MODEL clause whitepaper
Do it yourself
Did you like the above examples? Don’t worry. When you’ve seen these things for the first time, they can be pretty confusing. But in essence, they’re really not that complicated. And once you have those features in your tool-chain, you will be indefinitely more productive than if you had to write out all those algorithms in an imperative programming language.
If you want to play around with the examples, download Oracle XE and the running-totals.sql script and get up and running!
Conclusion
At Data Geekery, we always say:
SQL is a device whose mystery is only exceeded by its power
And sometimes, we also quote Winston Churchill for having said something along the lines of:
SQL is the worst form of database querying, except for all the other forms
Indeed, as the MODEL clause has shown us, SQL can become very extreme. But once you know the tricks and expressions (and most importantly, window functions), you’ll be incredibly more productive with SQL than with many other technologies, if the task at hand is a bulk calculation operation on a simple or complex data set. And your query is often faster than if you had hand-written it, at least when you’re using a decent database.
So let’s put SQL to action in our software!
Are you interested in hosting our NoSQL? No, SQL! talk at your local JUG or as an in-house presentation? Contact us, we’re more than happy to help you improve your SQL skills!
| Reference: | NoSQL? No, SQL! – How to Calculate Running Totals from our JCG partner Lukas Eder at the JAVA, SQL, AND JOOQ blog. |

Wow, this is a great article. Thanks, Lukas! Totally agree with your message: learn the language of your database to get the most out of it! As for the performance comparison, I was able to partially reproduce your results using SQL Fiddle. In order of speed: 1. Window function 2. Model clause 3. Nested select The recursive query blew up with the message “ORA-02393: exceeded call limit on CPU usage”, so it doesn’t even rank :-) Although I saw speed differences, the number of rows generated by the nested select was not exteme (still around 1000 rows all the way… Read more »
You’re welcome, as always :-) Yes, the recursive query is actually quite poorly designed, for the effect of showing what can go wrong with that. There are two issues: 1. The filtering based on ROW_NUMBER(), that can certainly be improved (making the query utterly unreadable) 2. Oracle not being able to push down the account_id predicate into the UNION subqueries. I have been trying to figure this out for a while, I don’t know why it doesn’t work. The query can be speeded up considerably by manually pushing down that predicate into the subqueries. Note, it’s always about tuning when… Read more »