Introduction
In my previous post I talked about various database identifier strategies, you need to be aware of when designing the database model. We concluded that database sequences are very convenient, because they are both flexible and efficient for most use cases.
But even with cached sequences, the application requires a database round-trip for every new the sequence value. If your applications demands a high number of insert operations per transaction, the sequence allocation may be optimized with a hi/lo algorithm.
The hi/lo algorithm
The hi/lo algorithms splits the sequences domain into “hi” groups. A “hi” value is assigned synchronously. Every “hi” group is given a maximum number of “lo” entries, that can by assigned off-line without worrying about concurrent duplicate entries.
- The “hi” token is assigned by the database, and two concurrent calls are guaranteed to see unique consecutive values
- Once a “hi” token is retrieved we only need the “incrementSize” (the number of “lo” entries)
- The identifiers range is given by the following formula:
- When all “lo” values are used, a new “hi” value is fetched and the cycle continues
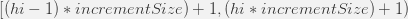
and the “lo” value will be taken from:
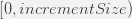
starting from:
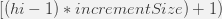
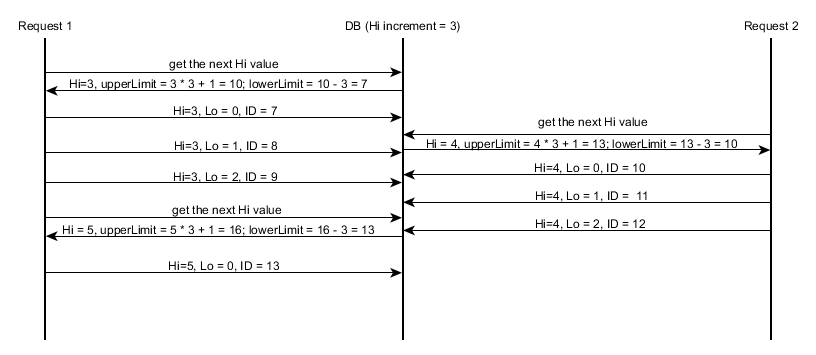
Here you can have an example of two concurrent transactions, each one inserting multiple entities:
Testing the theory
If we have the following entity:
@Entity
public class Hilo {
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "hilo_sequence_generator")
@GenericGenerator(
name = "hilo_sequence_generator",
strategy = "org.hibernate.id.enhanced.SequenceStyleGenerator",
parameters = {
@Parameter(name = "sequence_name", value = "hilo_seqeunce"),
@Parameter(name = "initial_value", value = "1"),
@Parameter(name = "increment_size", value = "3"),
@Parameter(name = "optimizer", value = "hilo")
})
@Id
private Long id;
}We can check how many database sequence round-trips are issued when inserting multiple entities:
@Test
public void testHiloIdentifierGenerator() {
doInTransaction(new TransactionCallable<Void>() {
@Override
public Void execute(Session session) {
for(int i = 0; i < 8; i++) {
Hilo hilo = new Hilo();
session.persist(hilo);
session.flush();
}
return null;
}
});
}Which end-ups generating the following SQL queries:
Query:{[call next value for hilo_seqeunce][]}
Query:{[insert into Hilo (id) values (?)][1]}
Query:{[insert into Hilo (id) values (?)][2]}
Query:{[insert into Hilo (id) values (?)][3]}
Query:{[call next value for hilo_seqeunce][]}
Query:{[insert into Hilo (id) values (?)][4]}
Query:{[insert into Hilo (id) values (?)][5]}
Query:{[insert into Hilo (id) values (?)][6]}
Query:{[call next value for hilo_seqeunce][]}
Query:{[insert into Hilo (id) values (?)][7]}
Query:{[insert into Hilo (id) values (?)][8]}As you can see we have only 3 sequence calls for 8 inserted entities. The more entity inserts a transaction will we require the better the performance gain we’ll obtain from reducing the database sequence round-trips.
| Reference: | The hi/lo algorithm from our JCG partner Vlad Mihalcea at the Vlad Mihalcea’s Blog blog. |
