JPA Hibernate Alternatives. What can I use if JPA or Hibernate is not good enough for my project?
Hello, how are you? Today we will talk about situations that the use of the JPA/Hibernate is not recommended. Which alternatives do we have outside the JPA world?
What we will talk about:
- JPA/Hibernate problems
- Solutions to some of the JPA/Hibernate problems
- Criteria for choosing the frameworks described here
- Spring JDBC Template
- MyBatis
- Sormula
- sql2o
- Take a look at: jOOQ and Avaje
- Is a raw JDBC approach worth it?
- How can I choose the right framework?
- Final thoughts
I have created 4 CRUDs in my github using the frameworks mentioned in this post, you will find the URL at the beginning of each page.
I am not a radical that thinks that JPA is worthless, but I do believe that we need to choose the right framework for the each situation. If you do not know I wrote a JPA book (in Portuguese only) and I do not think that JPA is the silver bullet that will solve all the problems.
JPA/Hibernate problems
There are times that JPA can do more harm than good. Below you will see the JPA/Hibernate problems and in the next page you will see some solutions to these problems:
- Composite Key: This, in my opinion, is the biggest headache of the JPA developers. When we map a composite key we are adding a huge complexity to the project when we need to persist or find a object in the database. When you use composite key several problems will might happen, and some of these problems could be implementation bugs.
- Legacy Database: A project that has a lot of business rules in the database can be a problem when wee need to invoke StoredProcedures or Functions.
- Artifact size: The artifact size will increase a lot if you are using the Hibernate implementation. The Hibernate uses a lot of dependencies that will increase the size of the generated jar/war/ear. The artifact size can be a problem if the developer needs to do a deploy in several remote servers with a low Internet band (or a slow upload). Imagine a project that in each new release it is necessary to update 10 customers servers across the country. Problems with slow upload, corrupted file and loss of Internet can happen making the dev/ops team to lose more time.
- Generated SQL: One of the JPA advantages is the database portability, but to use this portability advantage you need to use the JPQL/HQL language. This advantage can became a disadvantage when the generated query has a poor performance and it does not use the table index that was created to optimize the queries.
- Complex Query: That are projects that has several queries with a high level of complexity using database resources like: SUM, MAX, MIN, COUNT, HAVING, etc. If you combine those resources the JPA performance might drop and not use the table indexes, or you will not be able to use a specific database resource that could solve this problem.
- Framework complexity: To create a CRUD with JPA is very simples, but problems will appear when we start to use entities relationships, inheritance, cache, PersistenceUnit manipulation, PersistenceContext with several entities, etc. A development team without a developer with a good JPA experience will lose a lot of time with JPA ‘rules‘.
- Slow processing and a lot of RAM memory occupied: There are moments that JPA will lose performance at report processing, inserting a lot of entities or problems with a transaction that is opened for a long time.
After reading all the problems above you might be thinking: “Is JPA good in doing anything?”. JPA has a lot of advantages that will not be detailed here because this is not the post theme, JPA is a tool that is indicated for a lot of situations. Some of the JPA advantages are: database portability, save a lot of the development time, make easier to create queries, cache optimization, a huge community support, etc.
In the next page we will see some solutions for the problems detailed above, the solutions could help you to avoid a huge persistence framework refactoring. We will see some tips to fix or to workaround the problems described here.
Solutions to some of the JPA/Hibernate problems
We need to be careful if we are thinking about removing the JPA of our projects.
I am not of the developer type that thinks that we should remove a entire framework before trying to find a solution to the problems. Some times it is better to choose a less intrusive approach.
Composite Key
Unfortunately there is not a good solution to this problem. If possible, avoid the creation of tables with composite key if it is not required by the business rules. I have seen developers using composite keys when a simple key could be applied, the composite key complexity was added to the project unnecessarily.
Legacy Databases
The newest JPA version (2.1) has support to StoredProcedures and Functions, with this new resource will be easier to communicate with the database. If a JPA version upgrade is not possible I think that JPA is not the best solution to you.
You could use some of the vendor resources, e.g. Hibernate, but you will lose database and implementations portability.
Artifact Size
An easy solution to this problem would be to change the JPA implementation. Instead of using the Hibernate implementation you could use the Eclipsellink, OpenJPA or the Batoo. A problem might appear if the project is using Hibernate annotation/resources; the implementation change will require some code refactoring.
Generated SQL and Complexes Query
The solution to these problems would be a resource named NativeQuery. With this resource you could have a simplified query or optimized SQL, but you will sacrifice the database portability.
You could put your queries in a file, something like SEARCH_STUDENTS_ORACLE or SEARCH_STUDENTS_MYSQL, and in production environment the correct file would be accessed. The problem of this approach is that the same query must be written for every database. If we need to edit the SEARCH_STUDENTS query, it would be required to edit the oracle and mysql files.
If your project is has only one database vendor the NativeQuery resource will not be a problem.
The advantage of this hybrid approach (JPQL and NativeQuery in the same project) is the possibility of using the others JPA advantages.
Slow Processing and Huge Memory Size
This problem can be solved with optimized queries (with NativeQuery), query pagination and small transactions.
Avoid using EJB with PersistenceContext Extended, this kind of context will consume more memory and processing of the server.
There is also the possibility of getting an entity from database as a “read only” entity, e.g.: entity that will only be used in a report. To recover an entity in a “read only” state is not needed to open a transaction, take a look at the code below:
String query = "select uai from Student uai"; EntityManager entityManager = entityManagerFactory.createEntityManager(); TypedQuery<Student> typedQuery = entityManager.createQuery(query, Student.class); List<Student> resultList = typedQuery.getResultList();
Notice that in the code above there is no opened transaction, all the returned entities will be detached (non monitored by the JPA). If you are using EJB mark your transaction as NOT_SUPPORTED or you could use @Transactional(readOnly=true).
Complexity
I would say that there is only one solution to this problem: to study. It will be necessary to read books, blogs, magazines or any other trustful source of JPA material. More study is equals to less doubts in JPA.
I am not a developer that believes that JPA it is the only and the best solution to every problem, but there are moments that JPA is not the best to tool to use.
You must be careful when deciding about a persistence framework change, usually a lot of classes are affected and a huge refactoring is needed. Several bugs may be caused by this refactoring. It is needed to talk with the project mangers about this refactoring and list all the positive and negative effects.
In the next four pages we will see 4 persistence frameworks that can be used in our projects, but before we see the frameworks I will show how that I choose each framework.
Criteria for choosing the frameworks described here
Maybe you will think: “why the framework X is not here?”. Below I will list the criteria applied for choosing the framework displayed here:
- Found in more than one source of research: we can find in forums people talking about a framework, but it is harder to find the same framework appearing in more than one forum. The most quoted frameworks were chosen.
- Quoted by different sources: Some frameworks that we found in the forums are indicated only by its committers. Some forums does not allow “self merchandise”, but some frameworks owners still doing it.
- Last update 01/05/2013: I have searched for frameworks that have been updated in this past year.
- Quick Hello World: Some frameworks I could not do a Hello World with less than 15~20min, and with some errors. To the tutorials found in this post I have worked 7 minutes in each framework: starting counting in its download until the first database insert.
The frameworks that will be displayed in here has good methods and are easy to use. To make a real CRUD scenario we have a persistence model like below:
- A attribute with a name different of the column name: socialSecurityNumber —-> social_security_number
- A date attribute
- a ENUM attribute
With this characteristics in a class we will see some problems and how the framework solve it.
Spring JDBC Template
One of the most famous frameworks that we can find to access the database data is the Spring JDBC Template. The code of this project can be found in here: https://github.com/uaihebert/SpringJdbcTemplateCrud
The Sprint JDBC Template uses natives queries like below:
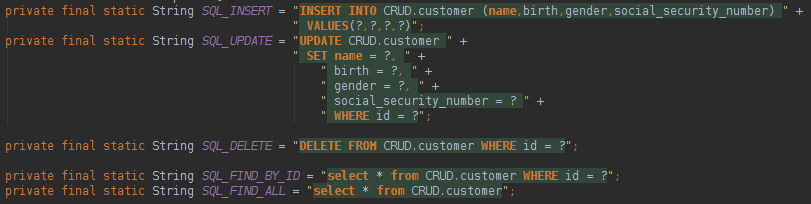
As it is possible to see in the image above the query has a database syntax (I will be using MySQL). When we use a native SQL query it is possible to use all the database resources in an easy way.
We need an instance of the object JDBC Template (used to execute the queries), and to create the JDBC Template object we need to set up a datasource:
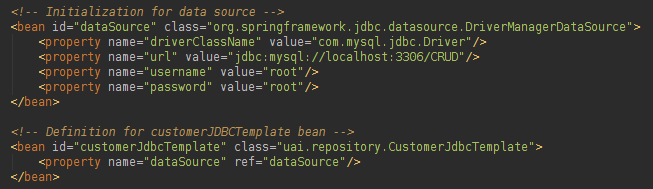
We can get the datasource now (thanks to the Spring injection) and create our JDBCTemplate:
PS.: All the XML code above and the JDBCTemplate instantiation could be replace by Spring injection and with a code bootstrap, just do a little research about the Spring features. One thing that I did not liked is the INSERT statement with ID recover, it is very verbose:
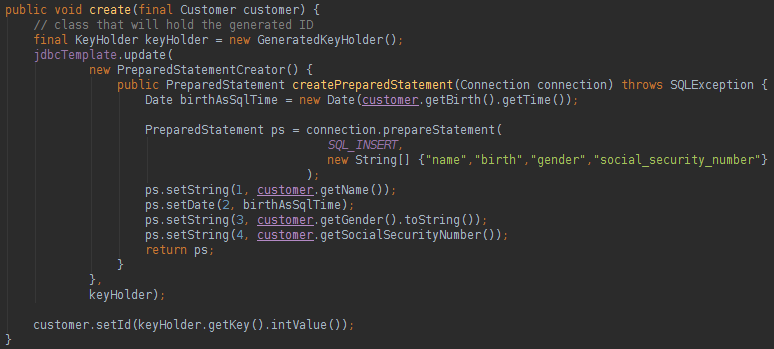
With the KeyHolder class we can recover the generated ID in the database, unfortunately we need a huge code to do it. The other CRUD functions are easier to use, like below:
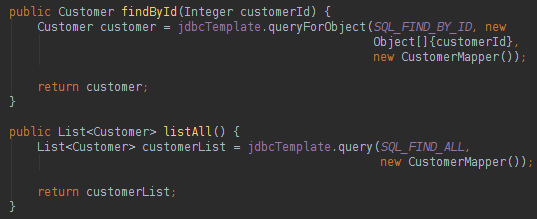
Notice that to execute a SQL query it is very simple and results in a populated object, thanks to the RowMapper. The RowMapper is the engine that the JDBC Template uses to make easier to populate a class with data from the database.
Take a look at the RowMapper code below:
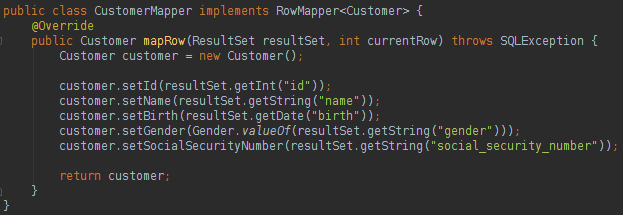
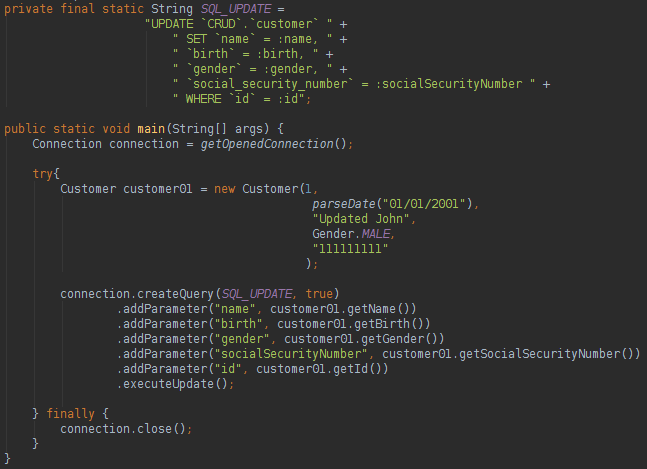
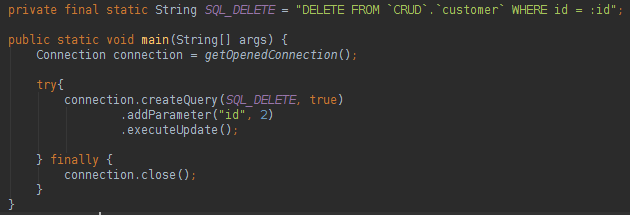
The best news about the RowMapper is that it can be used in any query of the project. The developer that is responsible to write the logic that will populate the class data. To finish this page, take a look below in the database DELETE and the database UPDATE statement:

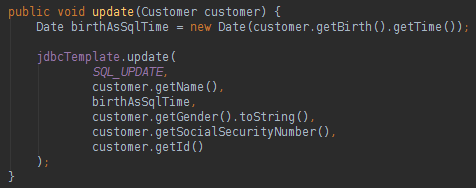
About the Spring JDBC Template we can say:
- Has a good support: Any search in the Internet will result in several pages with tips and bug fixes.
- A lot of companies use it: several projects across the world use it
- Be careful with different databases for the same project: The native SQL can became a problem with your project run with different databases. Several queries will need to be rewritten to adapt all the project databases.
- Framework Knowledge: It is good to know the Spring basics, how it can be configured and used.
To those that does not know the Spring has several modules and in your project it is possible to use only the JDBC Template module. You could keep all the other modules/frameworks of your project and add only the necessary to run the JDBC Template.
MyBatis
MyBatis (created with the name iBatis) is a very good framework that is used by a lot of developers. Has a lot of functionalities, but we will only see a few in this post. The code of this page can be found in here: https://github.com/uaihebert/MyBatisCrud
To run your project with MyBatis you will need to instantiate a Session Factory. It is very easy and the documentation says that this factory can be static:
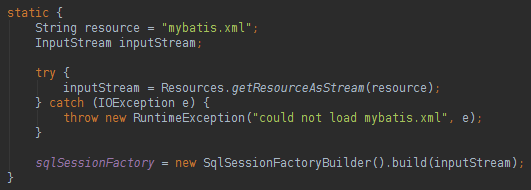
When you run a project with MyBatis you just need to instantiate the Factory one time, that is why it is in a static code. The configuration XML (mybatis.xml) it is very simple and its code can be found below:
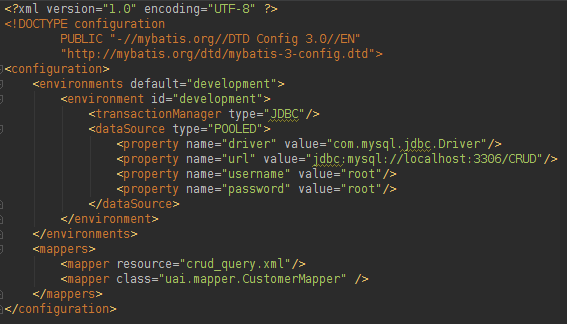
The Mapper (an attribute inside the XML above) will hold information about the project queries and how to translate the database result into Java objects. It is possible to create a Mapper in XML or Interface. Let us see below the Mapper found in the file crud_query.xml:
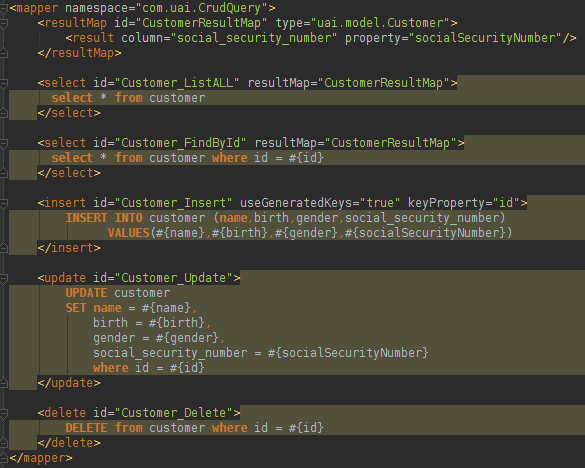
Notice that the file is easy to understand. The first configuration found is a ResultMap that indicates the query result type, and a result class was configured “uai.model.Customer”. In the class we have a attribute with a different name of the database table column, so we need to add a configuration to the ResultMap. All queries need a ID that will be used by MyBatis session. In the beginning of the file it is possible to see a namespace declared that works as a Java package, this package will wrap all the queries and the ResultMaps found in the XML file. We could also use a Interface+Annotation instead of the XML. The Mapper found in the crud_query.xml file could be translated in to a Interface like:
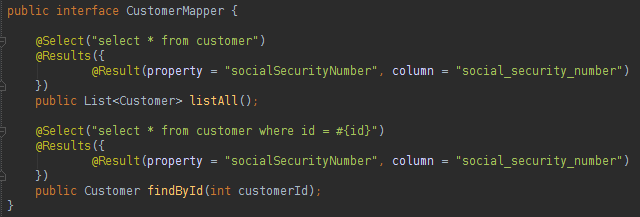
Only the Read methods were written in the Interface to make the code smaller, but all the CRUD methods could be written in the Interface. Let us see first how to execute a query found in the XML file:
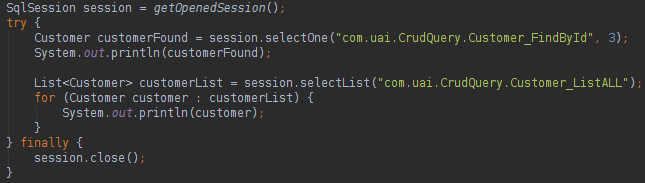
The parsing of the object is automatically and the method is easy to read. To run the query all that is needed is to use the combination “namespace + query id” that we saw in the crud_query.xml code above. If the developer wants to use the Interface approach he could do like below:
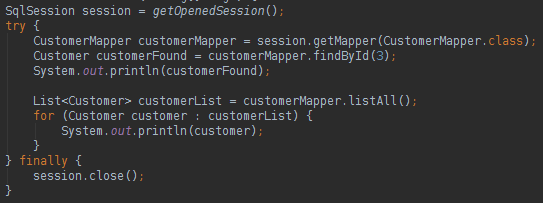
With the interface query mode we have a clean code and the developer will not need to instantiate the Interface, the session class of the MyBatis will do the work. If you want to update, delete or insert a record in the database the code is very easy:
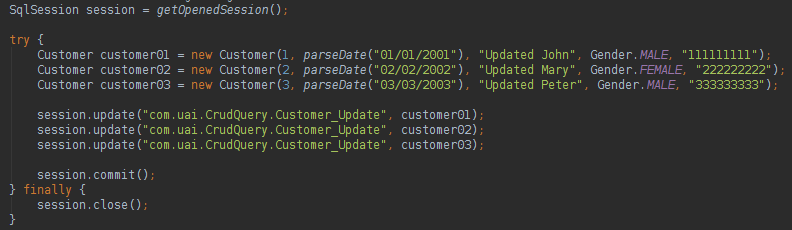
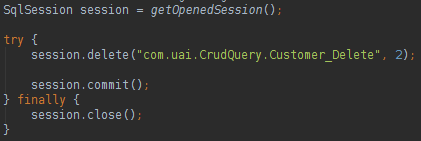
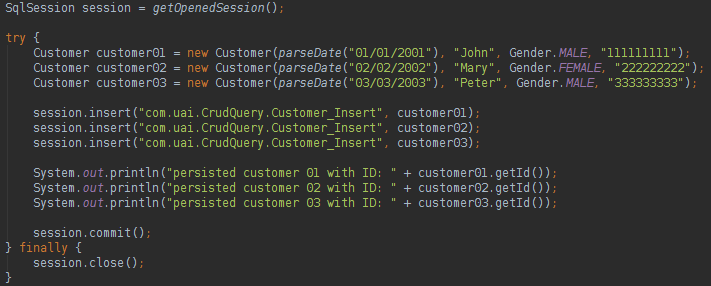
About MyBatis we could say:
- Excellent Documentation: Every time that I had a doubt I could answer it just by reading its site documentation
- Flexibility: Allowing XML or Interfaces+Annotations the framework gives a huge flexibility to the developer. Notice that if you choose the Interface approach the database portability will be harder, it is easier to choose which XML to send with the deploy artifact rather than an interface
- Integration: Has integration with Guice and Spring
- Dynamic Query: Allows to create queries in Runtime, like the JPA criteria. It is possible to add “IFs” to a query to decide which attribute will be used in the query
- Transaction: If your project is not using Guice of Spring you will need to manually control the transaction
Sormula
Sormula is a ORM OpenSource framework, very similar to the JPA/Hibernate. The code of the project in this page can be found in here: https://github.com/uaihebert/SormulaCrud
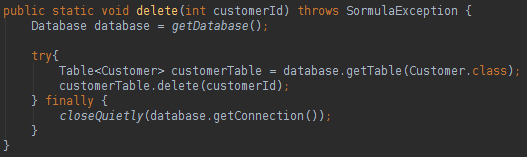
Sormula has a class named Database that works like the JPA EntityManagerFactory, the Database class will be like a bridge between the database and your model classes. To execute the SQL actions we will use the Table class that works like the JPA EntityManager, but the Table class is typed. To run Sormula in a code you will need to create a Database instance:
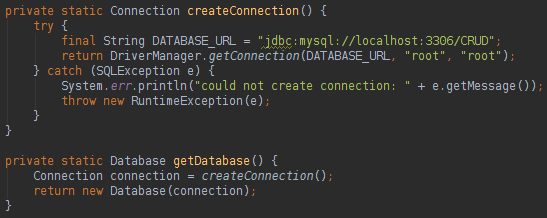
To create a Database instance all that we need is a Java Connection. To read data from the database is very easy, like below:
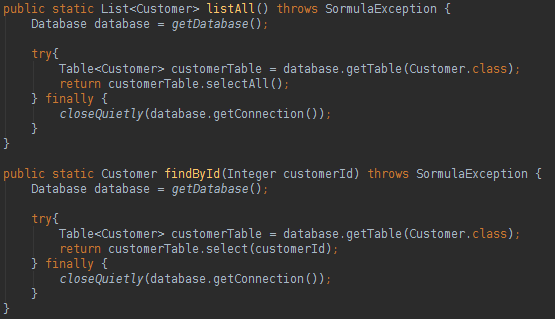
You only need to create a Database instance and a Table instance to execute all kind of SQL actions. How can we map a class attribute name different from the database table column name? Take a look below:
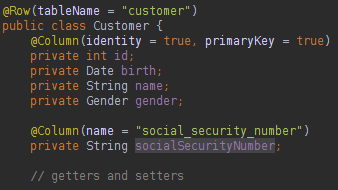
We can use annotations to do the database mapping in our classes, very close to the JPA style. To update, delete or create data in the database you can do like below:
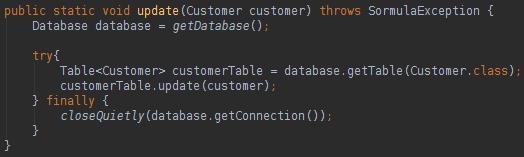
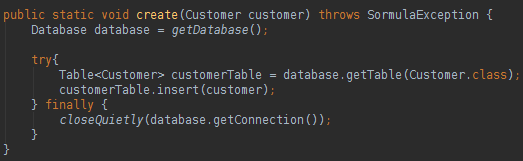
About Sormula we can say that:
- Has a good documentation
- Easy to set up
- It is not found in the maven repository, it will make harder to attach the source code if needed
- Has a lot of checked exceptions, you will need to do a try/catch for the invoked actions
sql2o
This framework works with native SQL and makes easier to transform database data into Java objects. The code of the project in this page can be found in here: https://github.com/uaihebert/sql2oCrud sql2o has a Connection class that is very easy to create:
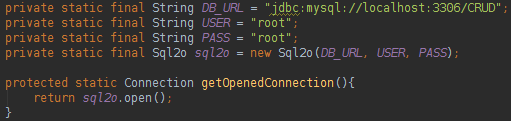
Notice that we have a static Sql2o object that will work like a Connection factory. To read the database data we would do something like:
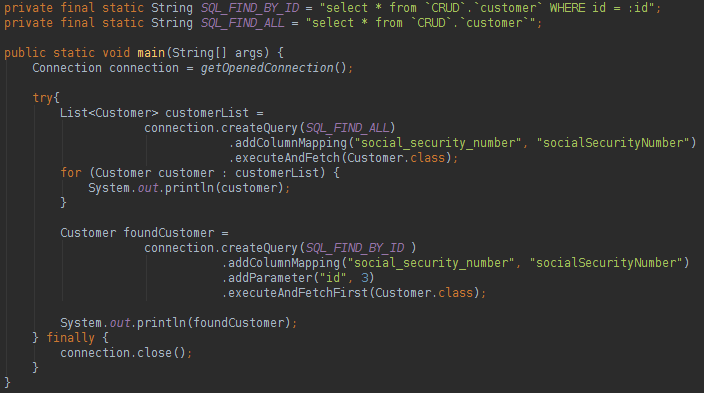
Notice that we have a Native SQL written, but we have named parameters. We are not using positional parameters like ‘?1′ but we gave a name to the parameter like ‘:id’. We can say that named parameters has the advantage that we will not get lost in a query with several parameters; when we forget to pass some parameter the error message will tell us the parameter name that is missing.
We can inform in the query the name of the column with a different name, there is no need to create a Mapper/RowMapper. With the return type defined in the query we will not need to instantiate manually the object, sql2o will do it for us. If you want to update, delete or insert data in the database you can do like below:
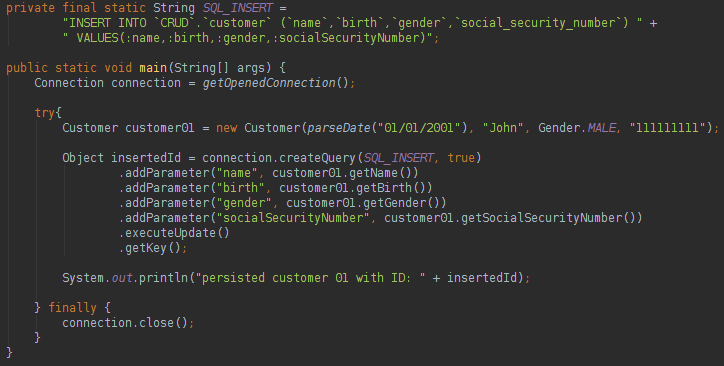
It is a “very easy to use” framework. About the sql2o we can say that:
- Easy to handle scalar query: the returned values of SUM, COUNT functions are easy to handle
- Named parameters in query: Will make easy to handle SQL with a lot of parameters
- Binding functions: bind is a function that will automatically populate the database query parameters through a given object, unfortunately it did not work in this project for a problem with the enum. I did not investigate the problem, but I think that it is something easy to handle
jOOQ
jOOQ it is a framework indicated by a lot of people, the users of this frameworks praise it in a lot of sites/forums. Unfortunately the jOOQ did not work in my PC because my database was too old, and I could not download other database when writing this post (I was in an airplane).
I noticed that to use the jOOQ you will need to generated several jOOQ classes based in your model. jOOQ has a good documentation in the site and it details how to generate those classes.
jOOQ is free to those that uses a free database like: MySQL, Postgre, etc. The paid jOOQ version is needed to those that uses paid databases like: Oracle, SQL Server, etc.
Avaje
Is a framework quoted in several blogs/forums. It works with the ORM concept and it is easy to execute database CRUD actions.
Problems that I found:
- Not well detailed documentation: its Hello World is not very detailed
- Configurations: it has a required properties configuration file with a lot of configurations, really boring to those that just want to do a Hello World
- A Enhancer is needed: enhancement is a method do optimize the class bytecode, but is hard to setup in the beginning and is mandatory to do before the Hello World
Is a raw JDBC approach worth it?
The advantages of JDBC are:
- Best performance: We will not have any framework between the persistence layer and the database. We can get the best performance with a raw JDBC
- Control over the SQL: The written SQL is the SQL that will be executed in the database, no framework will edit/update/generate the query SQL
- Native Resource: We could access all natives database resources without a problem, e.g.: functions, stored procedures, hints, etc
The disadvantages are:
- Verbose Code: After receiving the database query result we need to instantiate and populate the object manually, invoking all the required “set” methods. This code will get worse if we have classes relationships like one-to-many. It will be very easy to find a while inside another while.
- Fragile Code: If a database table column changes its name it will be necessary to edit all the project queries that uses this column. Some project uses constants with the column name to help with this task, e.g. Customer.NAME_COLUMN, with this approach the table column name update would be easier. If a column is removed from the database all the project queries would be updated, even if you have a column constants.
- Complex Portability: If your project uses more than one database it would be necessary to have almost all queries written for each vendor. For any update in any query it would be necessary to update every vendor query, this could take a lot the time from the developers.
I can see only one factor that would make me choose a raw JDBC approach almost instantly:
- Performance: If your project need to process thousands of transactions per minutes, need to be scalable and with a low memory usage this is the best choice. Usually median/huge projects has all this high performance requirements. It is also possible to have a hybrid solution to the projects; most of the project repository (DAO) will use a framework, and just a small part of it will use JDBC
I do like JDBC a lot, I have worked and I still working with it. I just ask you to not think that JDBC is the silver bullet for every problem.
If you know any other advantage/disadvantage that is not listed here, just tell me and I will add here with the credits going to you.
How can I choose the right framework?
We must be careful if you want to change JPA for other project or if you are just looking for other persistence framework. If the solutions in page 3 are not solving your problems the best solution is to change the persistence framework. What should you considerate before changing the persistence framework?
- Documentation: is the framework well documented? Is easy to understand how it works and can it answer most of your doubts?
- Community: has the framework an active community of users? Has a forum?
- Maintenance/Fix Bugs: Is the framework receiving commits to fix bugs or receiving new features? There are fix releases being created? With which frequency?
- How hard is to find a developer that knows about this framework? I believe that this is the most important issue to be considered. You could add to your project the best framework in the world but without developers that know how to operate it the framework will be useless. If you need to hire a senior developer how hard would be to find one? If you urgently need to hire someone that knows that unknown framework maybe this could be very difficult.
Final thoughts
I will say it again: I do not think that JPA could/should be applied to every situation in every project in the world; I do no think that that JPA is useless just because it has disadvantages just like any other framework.
I do not want you to be offended if your framework was not listed here, maybe the research words that I used to find persistence frameworks did not lead me to your framework.
I hope that this post might help you. If your have any double/question just post it. See you soon!
| Reference: | JPA Hibernate Alternatives. What can I use if JPA or Hibernate is not good enough for my project? from our JCG partner Hebert Coelho at the uaiHebert blog. |

What about Oracle Toplink?
Artifact size is a problem only if you pack your dependencies inside the war/ear/jar. If your application is running in some application server all your dependencies could be in the application server library path.
Generated queries are not a problem, you can use the hql sintax to generate your queries is the nearest of the SQL sintax, but if you have complex queries and the hibernate/JPA doesn’t have suport you could use native queries or create an read only entity to access a database view.
Before remove hibernate/JPA you can think about all solutions you have to solve your problems.
Did you take a look at querydsl?
i admire your comments,but i believe the programmers who developed these frameworks have a upper on you,mate they have been doing this for a long time..
yeah dude, I know this guys are awesome, I surfer this site every day search news about the java world, in any way I wanted to offend them, I am only expressing my experience with JPA. I didn’t use query dsl, but in the future perhaps I will need use this, for now I am only reading about. Sorry about my poor english I’ am from Brazil.
I would like to add a bit of information from my work on https://github.com/arnaudroger/SimpleFlatMapper I did a benchmark to test the mapping performance of a few solutions here https://github.com/arnaudroger/SimpleFlatMapper/wiki/Performance-Java-7 MyBatis and Hibernate inflating is pretty slow and can be very costly for a big number of rows. Sql2o is not too bad. On spring jdbc you can also use Roma or SimpleFlatMapper that provides SimpleFlatMapper. Roma is annotation based and the object need to exactly match the query. SimpleFlatMapper will generate mapper based on the meta data, there will be a slightly higher cost on the first query but because… Read more »