In the last post in this series we have seen how we can use Logstash, Elasticsearch and Kibana for doing logfile analytics. This week we will look at the general capabilities for doing analytics on any data using Elasticsearch and Kibana.
Use Case
We have already seen that Elasticsearch can be used to store large amounts of data. Instead of putting data into a data warehouse Elasticsearch can be used to do analytics and reporting. Another use case is social media data: Companies can look at what happens with their brand if they have the possibility to easily search it. Data can be ingested from multiple sources, e.g. Twitter and Facebook and combined in one system. Visualizing data in tools like Kibana can help with exploring large data sets. Finally mechanisms like Elasticsearchs Aggregations can help with finding new ways to look at the data.
Aggregations
Aggregations provide what the now deprecated facets have been providing but also a lot more. They can combine and count values from different documents and therefore show you what is contained in your data. For example if you have tweets indexed in Elasticsearch you can use the terms aggregation to find the most common hashtags. For details on indexing tweets in Elasticsearch see this post on the Twitter River and this post on the Twitter input for Logstash.
curl -XGET "http://localhost:9200/devoxx/tweet/_search" -d'
{
"aggs" : {
"hashtags" : {
"terms" : {
"field" : "hashtag.text"
}
}
}
}'Aggregations are requested using the aggs keyword, hashtags is a name I have chosen to identify the result and the terms aggregation counts the different terms for the given field (Disclaimer: For a sharded setup the terms aggregation might not be totally exact). This request might result in something like this:
"aggregations": {
"hashtags": {
"buckets": [
{
"key": "dartlang",
"doc_count": 229
},
{
"key": "java",
"doc_count": 216
},
[...]The result is available for the name we have chosen. Aggregations put the counts into buckets that contain of a value and a count. This is very similar to how faceting works, only the names are different. For this example we can see that there are 229 documents for the hashtag dartlang and 216 containing the hashtag java.
This could also be done with facets alone but there is more: Aggregations can even be combined. You can now nest another aggregation in the first one that for every bucket will give you more buckets for another criteria.
curl -XGET "http://localhost:9200/devoxx/tweet/_search" -d'
{
"aggs" : {
"hashtags" : {
"terms" : {
"field" : "hashtag.text"
},
"aggs" : {
"hashtagusers" : {
"terms" : {
"field" : "user.screen_name"
}
}
}
}
}
}'We still request the terms aggregation for the hashtag. But now we have another aggregation embedded, a terms aggregation that processes the user name. This will then result in something like this.
"key": "scala",
"doc_count": 130,
"hashtagusers": {
"buckets": [
{
"key": "jaceklaskowski",
"doc_count": 74
},
{
"key": "ManningBooks",
"doc_count": 3
},
[...]We can now see the users that have used a certain hashtext. In this case one user used one hashtag a lot. This is information that is not available that easily with queries and facets alone.
Besides the terms aggreagtion we have seen here there are also lots of other interesting aggregations available and more are added with every release. You can choose between bucket aggregations (like the terms aggregation) and metrics aggregations, that calculate values from the buckets, e.g. averages oder other statistical values.
Visualizing the Data
Besides the JSON output we have seen above, the data can also be used for visualizations. This is something that can then be prepared even for a non technical audience. Kibana is one of the options that is often used for logfile data but can be used for data of all kind, e.g. the Twitter data we have already seen above.
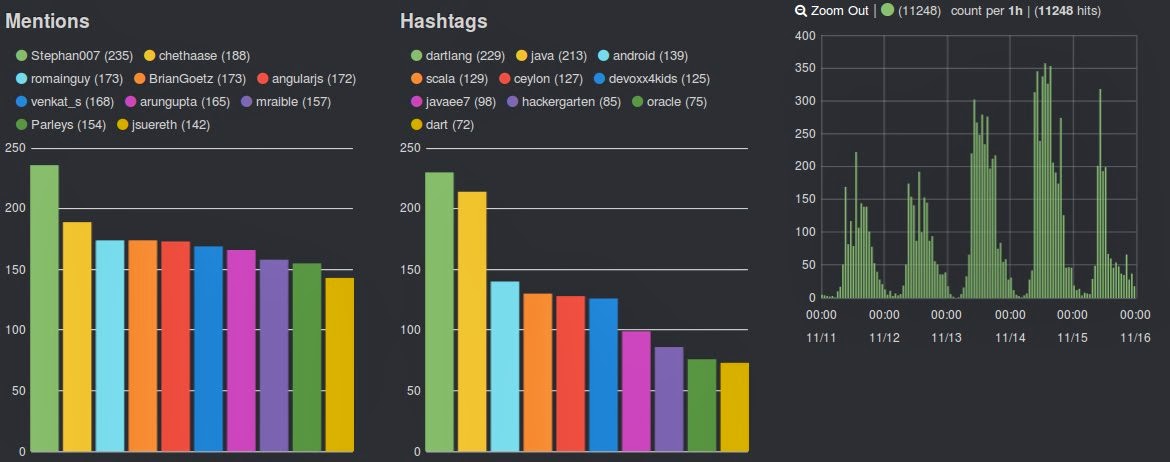
There are two bar charts that display the term frequencies for the mentions and the hashtags. We can already see easily which values are dominant. Also, the date histogram to the right shows at what time most tweets are sent. All in all these visualizations can provide a lot of value when it comes to trends that are only seen when combining the data.
The image shows Kibana 3, which still relies on the facet feature. Kibana 4 will instead provide access to the aggregations.
Conclusion
This post ends the series on use cases for Elasticsearch. I hope you enjoyed reading it and maybe you learned something new along the way. I can’t spend that much time blogging anymore but new posts will be coming. Keep an eye on this blog.
| Reference: | Use Cases for Elasticsearch: Analytics from our JCG partner Florian Hopf at the Dev Time blog. |
