In this post we are going to see how to develop a simple language. We will aim to get:
- a parser for the language
- an editor for IntelliJ. The editor should have syntax highlighting, validation and auto-completion
We would also get for free an editor for Eclipse and web editor, but please contain your excitement, we are not going to look into that in this post.
In the last year I have focused on learning new stuff (mostly web and ops stuff) but one of the things I still like the most is to develop DSLs (Domain Specific Languages). The first related technology I played with was Xtext: Xtext is a fantastic tool that let you define the grammar of your language and generate amazing editors for such language. Until now it has been developed only for the Eclipse platform: it means that new languages could be developed using Eclipse and the resulting editors could then be installed in Eclipse.
Lately I have been using far less Eclipse and so I my interest in Xtext faded until now, when finally the new release of Xtext (still in beta) is targeting IntelliJ. So while we will develop our language using Eclipse, we will then generate plugins to use our language both in IntelliJ.
The techniques we are going to see can be used to develop any sort of language, but we are going to apply them to a specific case: AST transformations. This post is intended for Xtext newbies and I am not going in many details for now, I am just sharing my first impression of the IntelliJ target. Consider that this functionality is currently a beta, so we could expect some rough edges.
The problem we are trying to solve: adapt ANTLR parsers to get awesome ASTs
I like playing with parsers and ANTLR is a great parser generator. There are beatiful grammars out there for full blown languages like Java. Now, the problem is that the grammars of languages like Java are quite complex and the generated parsers produce ASTs that are not easy to use. The main problem is due to how precedence rules are handled. Consider the grammar for Java 8 produced by Terence Parr and Sam Harwell. Let’s look at how some expressions are defined:
conditionalExpression
: conditionalOrExpression
| conditionalOrExpression '?' expression ':' conditionalExpression
;
conditionalOrExpression
: conditionalAndExpression
| conditionalOrExpression '||' conditionalAndExpression
;
conditionalAndExpression
: inclusiveOrExpression
| conditionalAndExpression '&&' inclusiveOrExpression
;
inclusiveOrExpression
: exclusiveOrExpression
| inclusiveOrExpression '|' exclusiveOrExpression
;
exclusiveOrExpression
: andExpression
| exclusiveOrExpression '^' andExpression
;
andExpression
: equalityExpression
| andExpression '&' equalityExpression
;
equalityExpression
: relationalExpression
| equalityExpression '==' relationalExpression
| equalityExpression '!=' relationalExpression
;
relationalExpression
: shiftExpression
| relationalExpression '<' shiftExpression
| relationalExpression '>' shiftExpression
| relationalExpression '<=' shiftExpression
| relationalExpression '>=' shiftExpression
| relationalExpression 'instanceof' referenceType
;
shiftExpression
: additiveExpression
| shiftExpression '<' '<' additiveExpression
| shiftExpression '>' '>' additiveExpression
| shiftExpression '>' '>' '>' additiveExpression
;
additiveExpression
: multiplicativeExpression
| additiveExpression '+' multiplicativeExpression
| additiveExpression '-' multiplicativeExpression
;
multiplicativeExpression
: unaryExpression
| multiplicativeExpression '*' unaryExpression
| multiplicativeExpression '/' unaryExpression
| multiplicativeExpression '%' unaryExpression
;
unaryExpression
: preIncrementExpression
| preDecrementExpression
| '+' unaryExpression
| '-' unaryExpression
| unaryExpressionNotPlusMinus
;This is just a fragment of the large portion of code used to define expressions. Now consider you have a simple preIncrementExpression (something like: ++a). In the AST we will have node of type preIncrementExpression that will be contained in an unaryExpression.
The unaryExpression will be contained in a multiplicativeExpression, which will be contained in an additiveExpression and so on and so forth. This organization is necessary to handle operator precedence between the different kind of operations, so that 1 + 2 * 3 is parsed as a sum of 1 and 2 * 3 instead of a multiplication of 1 + 2 and 3. The problem is that from the logical point of view multiplications and additions are expressions at the same level: it does not make sense to have Matryoshka AST nodes. Consider this code:
class A { int a = 1 + 2 * 3; }While we would like something like:
[CompilationUnitContext]
[TypeDeclarationContext]
[ClassDeclarationContext]
[NormalClassDeclarationContext]
class
A
[ClassBodyContext]
{
[ClassBodyDeclarationContext]
[ClassMemberDeclarationContext]
[FieldDeclarationContext]
[UnannTypeContext]
[UnannPrimitiveTypeContext]
[NumericTypeContext]
[IntegralTypeContext]
int
[VariableDeclaratorListContext]
[VariableDeclaratorContext]
[VariableDeclaratorIdContext]
a
=
[VariableInitializerContext]
[ExpressionContext]
[AssignmentExpressionContext]
[ConditionalExpressionContext]
[ConditionalOrExpressionContext]
[ConditionalAndExpressionContext]
[InclusiveOrExpressionContext]
[ExclusiveOrExpressionContext]
[AndExpressionContext]
[EqualityExpressionContext]
[RelationalExpressionContext]
[ShiftExpressionContext]
[AdditiveExpressionContext]
[AdditiveExpressionContext]
[MultiplicativeExpressionContext]
[UnaryExpressionContext]
[UnaryExpressionNotPlusMinusContext]
[PostfixExpressionContext]
[PrimaryContext]
[PrimaryNoNewArray_lfno_primaryContext]
[LiteralContext]
1
+
[MultiplicativeExpressionContext]
[MultiplicativeExpressionContext]
[UnaryExpressionContext]
[UnaryExpressionNotPlusMinusContext]
[PostfixExpressionContext]
[PrimaryContext]
[PrimaryNoNewArray_lfno_primaryContext]
[LiteralContext]
2
*
[UnaryExpressionContext]
[UnaryExpressionNotPlusMinusContext]
[PostfixExpressionContext]
[PrimaryContext]
[PrimaryNoNewArray_lfno_primaryContext]
[LiteralContext]
3
;
}
<EOF>While we would like something like:
[CompilationUnit]
[FieldDeclaration]
[PrimitiveTypeRef]
[Sum]
[Multiplication]
[IntegerLiteral]
[IntegerLiteral]
[IntegerLiteral]Ideally we want to specify grammars that produce the Matryoshka-style of ASTs but using a more flat ASTs when doing analysis on the code, so we are going to build adapters from the ASTs as produced by Antlr and the “logical” ASTs. How do we plan to do that? We will start by developing a language defining the shape of nodes as we want them to appear in the logical ASTs and we will also define how to map the Antlr nodes (the Matryoshka-style nodes) into these logical nodes. This is just the problem we are trying to solve: Xtext can be used to develop any sort of language, is just that being a parser maniac I like to use DSLs to solve parser related problems. Which is very meta.
Getting started: installing Eclipse Luna DSL and create the project
We are going to download a version of Eclipse containing the beta of Xtext 2.9. In your brand new Eclipse you can create a new type of projects: Xtext Projects.
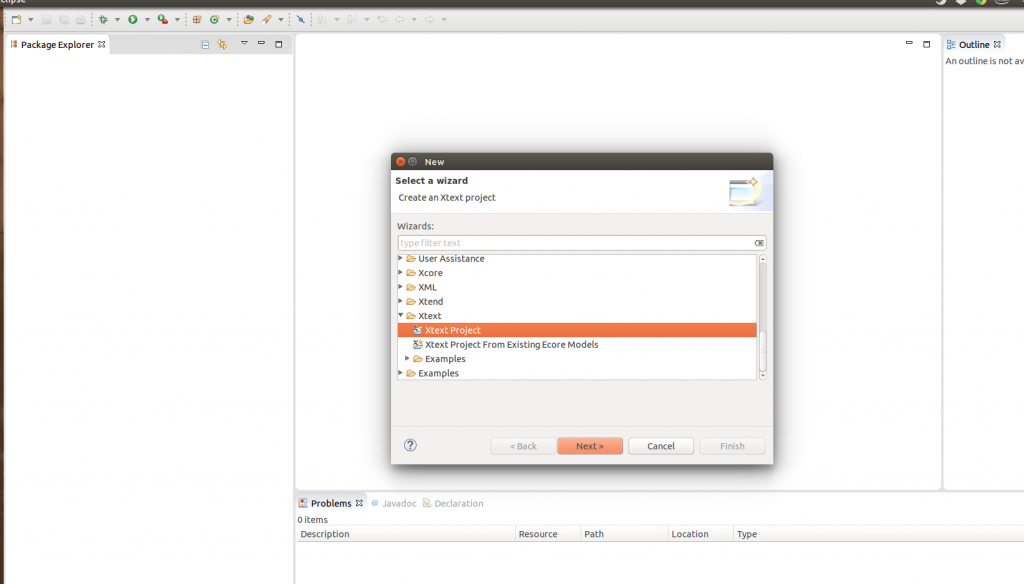
We just have to define the name of the project and pick an extension to be associated with our new language
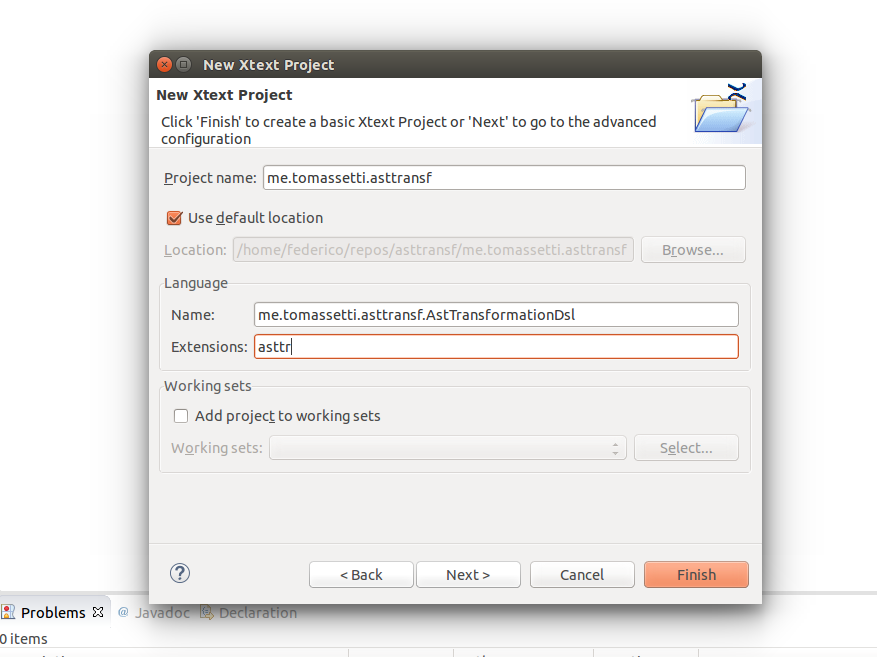
And then we select the platforms that we are interested into (yes, there is also the web platform… we will look into that in the future)
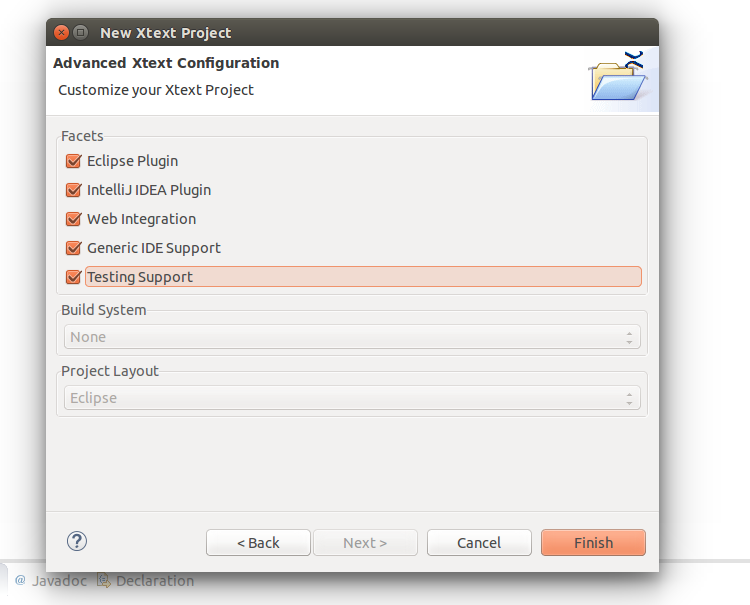
The project created contains a sample grammar. We could use it as is, we would have just to generate a few files running the MWE2 file.
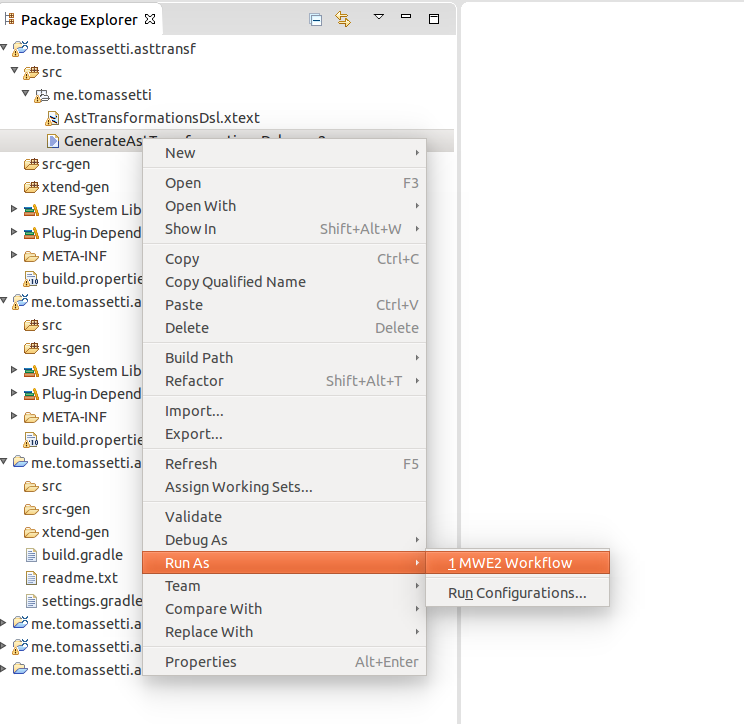
After running this command we could just use our new plugin in IntelliJ or in Eclipse. But we are going instead to first change the grammar, to transform the given example in our glorious DSL.
An example of our DSL
Our language will look like this in IntelliJ IDEA (cool, eh?).
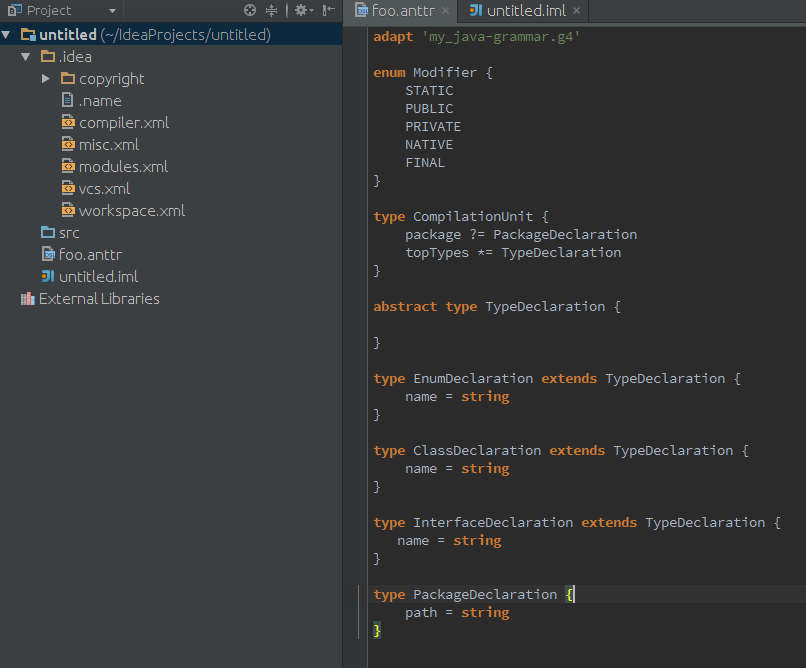
Of course this is just a start but we are start defining some basic node types for a Java parser:
- an enum representing the possible modifiers (warning: this is not a complete list)
- the CompilationUnit which contains an optional PackageDeclaration and possibly many TypeDeclarations
- TypeDeclaration is an abstract node and there are three concrete types extending it: EnumDeclaration, ClassDeclaration and InterfaceDeclaration (we are missing the annotation declaration)
We will need to add tens of expressions and statements but you should get an idea of the language we are trying to build. Note also that we have a reference to an Antlr grammar (in the first line) but we are not yet specifying how our defined node types maps to the Antlr node types. Now the question is: how do we build it?
Define the grammar
We can define the grammar of our language with a simple EBNF notation (with a few extensions). Look for a file with the xtext extension in your project and change it like this:
grammar me.tomassetti.AstTransformationsDsl with org.eclipse.xtext.common.Terminals
generate astTransformationsDsl "http://www.tomassetti.me/AstTransformationsDsl"
Model:
antlr=AntlrGrammarRef declarations+=Declaration*;
AntlrGrammarRef:
'adapt' grammarFile=STRING;
Declaration: NodeType | NamedEnumDeclaration;
NamedEnumDeclaration: 'enum' name=ID '{' values+=EnumNodeTypeFieldValue+ '}';
UnnamedEnumDeclaration: 'enum' '{' values+=EnumNodeTypeFieldValue+ '}';
NodeType:
'abstract'? 'type' name=ID ('extends' superType=[NodeType])? ('from' antlrNode=ID)? '{'
fields+=NodeTypeField*
'}';
NodeTypeField:
name=ID (many='*='|optional='?='|single='=') value=NodeTypeFieldValue;
NodeTypeFieldValue:
UnnamedEnumDeclaration | RelationNodeTypeField | AttributeNodeTypeField;
EnumNodeTypeFieldValue:
name=ID;
RelationNodeTypeField:
type=[NodeType];
AttributeNodeTypeField:
{AttributeNodeTypeField}('string'|'int'|'boolean');The first rule we define corresponds to the root of the AST (Model in our case). Our Model starts with a reference to an Antlr file and a list of Declarations. The idea is to specify declarations of our “logical” node types and how the “antlr” node types should be mapped to them. So we will define transformations that will have references to element defined… in the antlr grammar that will we specify in the AntlrGrammarRef rule.
We could define either Enum or NodeType. The NodeType has a name, can be abstract and can extends another NodeType. Note that the supertype is a reference to a NodeType. It means that the resulting editor will automatically be able to gives us auto-completion (listing all the NodeTypes defined in the file) and validation, verifying we are referring to an existing NodeType.
In our NodeTypes we can defined as many fields as we want (NodeTypeField). Each field starts with a name, followed by an operator:
- *= means we can have 0..n values in this field
- ?= means that the field is optional (0..1) value
- = means that exactly one value is always present
The NodeTypeField have also a value type which can be an enum defined inline (UnnamedEnumDeclaration), a relation (it means this node contains other nodes) or an attribute (it means this node has some basic attributes like a string or a boolean).
Pretty simple, eh?
So we basically re-run the MWE2 files and we are ready to go.
See the plugin in action
To see our plugin installed in IntelliJ IDEA we have just to run gradle runIdea from the directory containing the idea plugin (me.tomassetti.asttransf.idea in our case). Just note that you need a recent version of gradle and you need to define JAVA_HOME. This command will download IntelliJ IDEA, install the plugin we developed and start it. In the opened IDE you can create a new project and define a new file. Just use the extension we specified when we created the project (.anttr in our case) and IDEA should use our newly defined editor.
Currently validation is working but the editor seems to react quite slowly. Auto-completion is instead broken for me. Consider that this is just a beta, so I expect these issues to disappear before Xtext 2.9 is released.
Next steps
We are just getting started but it is amazing how we can have a DSL with its editor for IDEA working in a matter of minutes.
I plan to work in a few different direction:
- We need to see how to package and distribute the plugin: we can try it using gradle runIdea but we want to just produce a binary for people to install it without having to process the sources of the editor
- Use arbitrary dependencies from Maven: this is going to be rather complicate because Maven and the Eclipse plugin (OSGi bundles) define their dependencies in their own way, so jars have to be typically be packaged into bundles to being used in Eclipse plugins. However there are alternatives like Tycho and the p2-maven-plugin. Spoiler: I do not expect this one too be fast and easy…
- We are not yet able to refer to elements defined in the Antlr grammar. Now, it means that we should be able to parse the Antlr grammar and create programmatically EMF models, so that we can refer it in our DSL. It require to know EMF (and it gets some time…). I am going to play with that in the future and this will probably require a loooong tutorial.
Conclusions
While I do not like Eclipse anymore (now I am used to IDEA and it seems to me so much better: faster and lighter) the Eclipse Modeling Framework keeps being a very interesting piece of software and be able to use it with IDEA is great.
It was a while that I was not playing with EMF and Xtext and I have to say that I have seen some improvements. I had the feeling that Eclipse was not very command-line friendly and it was in general difficult to integrate it with CI systems. I am seeing an effort being done for fixing these problems (see Tycho or the gradle job we have used to start IDEA with the editor we developed) and it seems very positive to me.
Mixing technologies, combining the best aspects of different worlds in a pragmatic way is my philosophy, so I hope to find the time to play more with this stuff.
| Reference: | Develop DSLs for Eclipse and IntelliJ using Xtext from our JCG partner Federico Tomassetti at the Federico Tomassetti blog. |
