In this post I’m going to share a few tricks for using Hibernate tooling in CQRS read models for rapid development.
Why Hibernate?
Hibernate is extremely popular. It’s also deceptively easy on the outside and fairly complex on the inside. It makes it very easy get started without in-depth understanding, misuse, and discover problems when it’s already too late. For all these reasons these days it’s rather infamous.
However, it still is a piece of solid and mature technology. Battle-tested, robust, well-documented and having solutions to many common problems in the box. It can make you *very* productive. Even more so if you include tooling and libraries around it. Finally, it is safe as long as you know what you’re doing.
Automatic Schema Generation
Keeping SQL schema in sync with Java class definitions is rather expensive a bit of a struggle. In the best case it’s very tedious and time-consuming activity. There are numerous opportunities for mistakes.
Hibernate comes with a schema generator (hbm2ddl), but in its “native” form is of limited use in production. It can only validate the schema, attempt an update or export it, when the SessionFactory is created. Fortunately, the same utility is available for custom programmatic use.
We went one step further and integrated it with CQRS projections. Here’s how it works:
- When the projection process thread starts, validate whether DB schema matches the Java class definitions.
- If it does not, drop the schema and re-export it (using hbm2ddl). Restart the projection, reprocessing the event store from the very beginning. Make the projection start from the very beginning.
- If it does match, just continue updating the model from the current state.
Thanks to this, much of the time you don’t have to we almost never type SQL with table definitions by hand. It makes development a lot faster. It’s similar to working with hbm2ddl.auto = create-drop. However, using this in a view model means it does not actually lose data (which is safe in the event store). Also, it’s smart enough to only recreate the schema if it’s actually changed – unlike the create-drop strategy.
Preserving data and avoiding needless restarts does not only improve the development cycle. It also may make it usable in production. At least under certain conditions, see below.
There is one caveat: Not all changes in the schema make the Hibernate validation fail. One example is changing field length – as long as it’s varchar or text, validation passes regardless of limit. Another undetected change is nullability.
These issues can be solved by restarting the projection by hand (see below). Another possibility is having a dummy entity that doesn’t store data, but is modified to trigger the automatic restart. It could have a single field called schemaVersion, with @Column(name = "v_4") annotation updated (by developer) every time the schema changes.
Implementation
Here’s how it can be implemented:
public class HibernateSchemaExporter {
private final EntityManager entityManager;
public HibernateSchemaExporter(EntityManager entityManager) {
this.entityManager = entityManager;
}
public void validateAndExportIfNeeded(List<Class> entityClasses) {
Configuration config = getConfiguration(entityClasses);
if (!isSchemaValid(config)) {
export(config);
}
}
private Configuration getConfiguration(List<Class> entityClasses) {
SessionFactoryImplementor sessionFactory = (SessionFactoryImplementor) getSessionFactory();
Configuration cfg = new Configuration();
cfg.setProperty("hibernate.dialect", sessionFactory.getDialect().toString());
// Do this when using a custom naming strategy, e.g. with Spring Boot:
Object namingStrategy = sessionFactory.getProperties().get("hibernate.ejb.naming_strategy");
if (namingStrategy instanceof NamingStrategy) {
cfg.setNamingStrategy((NamingStrategy) namingStrategy);
} else if (namingStrategy instanceof String) {
try {
log.debug("Instantiating naming strategy: " + namingStrategy);
cfg.setNamingStrategy((NamingStrategy) Class.forName((String) namingStrategy).newInstance());
} catch (ReflectiveOperationException ex) {
log.warn("Problem setting naming strategy", ex);
}
} else {
log.warn("Using default naming strategy");
}
entityClasses.forEach(cfg::addAnnotatedClass);
return cfg;
}
private boolean isSchemaValid(Configuration cfg) {
try {
new SchemaValidator(getServiceRegistry(), cfg).validate();
return true;
} catch (HibernateException e) {
// Yay, exception-driven flow!
return false;
}
}
private void export(Configuration cfg) {
new SchemaExport(getServiceRegistry(), cfg).create(false, true);
clearCaches(cfg);
}
private ServiceRegistry getServiceRegistry() {
return getSessionFactory().getSessionFactoryOptions().getServiceRegistry();
}
private void clearCaches(Configuration cfg) {
SessionFactory sf = entityManager.unwrap(Session.class).getSessionFactory();
Cache cache = sf.getCache();
stream(cfg.getClassMappings()).forEach(pc -> {
if (pc instanceof RootClass) {
cache.evictEntityRegion(((RootClass) pc).getCacheRegionName());
}
});
stream(cfg.getCollectionMappings()).forEach(coll -> {
cache.evictCollectionRegion(((Collection) coll).getCacheRegionName());
});
}
private SessionFactory getSessionFactory() {
return entityManager.unwrap(Session.class).getSessionFactory();
}
}The API looks pretty dated and cumbersome. There does not seem to be a way to extract Configuration from the existing SessionFactory. It’s only something that’s used to create the factory and thrown away. We have to recreate it from scratch. The above is all we needed to make it work well with Spring Boot and L2 cache.
Restarting Projections
We’ve also implemented a way to perform such a reinitialization manually, exposed as a button in the admin console. It comes in handy when something about the projection changes but does not involve modifying the schema. For example, if a value is calculated/formatted differently, but it’s still a text field, this mechanism can be used to manually have the history reprocessed. Another use case is fixing a bug.
Production Use?
We’ve been using this mechanism with great success during development. It let us freely modify the schema by only changing the Java classes and never worrying about table definitions. Thanks to combination with CQRS, we could even maintain long-running demo or pilot customer instances. Data has always been safe in the event store. We could develop the read model schema incrementally and have the changes automatically deployed to a running instance, without data loss or manually writing SQL migration scripts.
Obviously this approach has its limits. Reprocessing the entire event store at random point in time is only feasible on very small instances or if the events can be processed fast enough.
Otherwise the migration might be solved using an SQL migration script, but it has its limits. It’s often risky and difficult. It may be slow. Most importantly, if the changes are bigger and involve data that was not previously included in the read model (but is available in the events), using an SQL script simply is not an option.
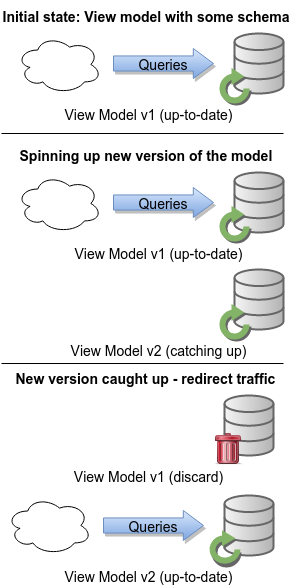
A much better solution is to point the projection (with new code) to a new database. Let it reprocess the event log. When it catches up, test the view model, redirect traffic and discard the old instance. The presented solution works perfectly with this approach as well.
| Reference: | Rapid Development with Hibernate in CQRS Read Models from our JCG partner Konrad Garus at the Squirrel’s blog. |
