This blog is a first in a series that discusses some design patterns from the book MapReduce design patterns and shows how these patterns can be implemented in Apache Spark(R).
When writing MapReduce or Spark programs, it is useful to think about the data flows to perform a job. Even if Pig, Hive, Apache Drill and Spark Dataframes make it easier to analyze your data, there is value in understanding the flow at a lower level, just like there is value in using Explain to understand a query plan. One way to think about this is in groupings for types of patterns, which are templates for solving a common and general data manipulation problems. Below is the list of types of MapReduce patterns in the MapReduce book:
- Summarization Patterns
- Filtering Patterns
- Data Organization Patterns
- Join Patterns
- Metapatterns
- Input and Output Patterns
In this post we will go over one of the summarization patterns, namely numerical summarizations.
Numerical Summarizations
Numerical summarizations are a pattern for calculating aggregate statistical values over data. The intent is to group records by a key field and calculate aggregates per group such as min, max, median. The figure below from the MapReduce design patterns book shows the general execution of this pattern in MapReduce.
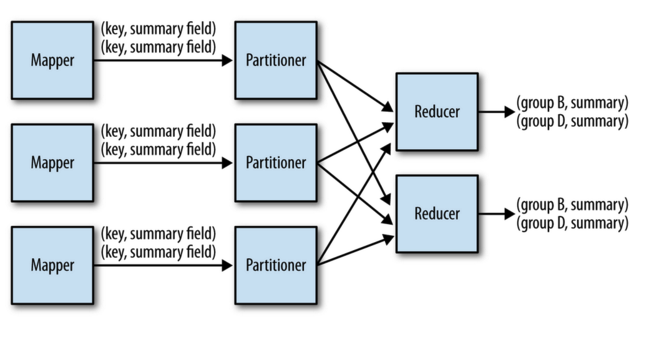
This Aggregation pattern corresponds to using GROUP BY in SQL for example:
SELECT MIN(numericalcol1), MAX(numericalcol1),
COUNT(*) FROM table GROUP BY groupcol2;In Pig this corresponds to:
b = GROUP a BY groupcol2;
c = FOREACH b GENERATE group, MIN(a.numericalcol1),
MAX(a.numericalcol1), COUNT_STAR(a);In Spark, Key value Pair RDDs are commonly used to group by a key in order to perform aggregations, as shown in the MapReduce diagram, however with Spark Pair RDDS, you have a lot more functions than just Map and Reduce.
We will go through some aggregation examples using the dataset from a previous blog on Spark Dataframes. The dataset is a .csv file that consists of online auction data. Each auction has an auction id associated with it and can have multiple bids. Each row represents a bid. For each bid, we have the following information:

(In the code boxes, comments are in Green and output is in Blue)
Below we load the data from the ebay.csv file, then we use a Scala case class to define the Auction schema corresponding to the ebay.csv file. Then map() transformations are applied to each element to create the auctionRDD of Auction objects.
// SQLContext entry point for working with structured data
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
// Import Spark SQL data types and Row.
import org.apache.spark.sql._
//define the schema using a case class
case class Auction(auctionid: String, bid: Double, bidtime: Double, bidder: String, bidderrate: Integer, openbid: Double, price: Double, item: String, daystolive: Integer)
// create an RDD of Auction objects
val auctionRDD= sc.textFile("ebay.csv").map(_.split(",")).map(p => Auction(p(0),p(1).toDouble,p(2).toDouble,p(3),p(4).toInt,p(5).toDouble,p(6).toDouble,p(7),p(8).toInt ))The figure below shows the general execution in Spark to calculate the average bid per auction for an item.
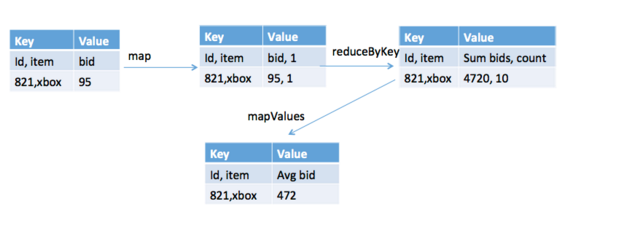
The corresponding code is shown below. First a key value pair is created with the auction id and item as the key and the bid amount and a 1 as the value , e.g. ((id,item), bid amount,1)) . Next a reduceBykey performs a sum of the bid amounts and a sum of the ones to get the total bid amount and the count. A mapValues calculates the average which is the total bid amount / count of bids.
// create key value pairs of ( (auctionid, item) , (bid, 1))
val apair = auctionRDD.map(auction=>((auction.auctionid,auction.item), (auction.bid, 1)))
// reducebyKey to get the sum of bids and count sum
val atotalcount = apair.reduceByKey((x,y) => (x._1 + y._1, x._2 + y._2))
// get a couple results
atotalcount.take(2)
// Array(((1641062012,cartier),(4723.99,3)), ((2920322392,palm),(3677.96,32)))
// avg = total/count
val avgs = atotalcount.mapValues{ case (total, count) => total.toDouble / count }
// get a couple results
avgs.take(2)
// Array(((1641062012,cartier),1574.6633333333332), ((2920322392,palm),114.93625))
// This could also be written like this
val avgs =auctionRDD.map(auction=>((auction.auctionid,auction.item), (auction.bid, 1))).reduceByKey((x,y) => (x._1 + y._1, x._2 + y._2)).mapValues{ case (total, count) => total.toDouble / count }It is also possible to use the java Math class or the spark StatCounter class to calculate statistics as shown
import java.lang.Math
// Calculate the minimum bid per auction val amax = apair.reduceByKey(Math.min) // get a couple results amax.take(2) // Array(((1641062012,cartier),1524.99), ((2920322392,palm),1.0)) import org.apache.spark.util.StatCounter // Calculate statistics on the bid amount per auction val astats = apair.groupByKey().mapValues(list => StatCounter(list)) // get a result astats.take(1) // Array(((1641062012,cartier),(count: 3, mean: 1574.663333, stdev: 35.126723, max: 1600.000000, min: 1524.990000)))
Spark DataFrames provide a domain-specific language for distributed data manipulation, making it easier to perform aggregations. Also DataFrame queries can perform better than coding with PairRDDs because their execution is automatically optimized by a query optimizer. Here is an example of using DataFrames to get the min , max, and avg bid by auctionid and item :
val auctionDF = auctionRDD.toDF()
// get the max, min, average bid by auctionid and item
auctionDF.groupBy("auctionid", "item").agg($"auctionid",$"item", max("bid"), min("bid"), avg("bid")).show
auctionid item MAX(bid) MIN(bid) AVG(bid)
3016429446 palm 193.0 120.0 167.54900054931642
8211851222 xbox 161.0 51.0 95.98892879486084You can also use SQL while working with DataFrames, using Spark SQL. This example gets the max , min, average bid by auctionid and item.
// register as a temp table inorder to use sql
auctionDF .registerTempTable("auction")
// get the max, min, average bid by auctionid and item
val aStatDF = sqlContext.sql("SELECT auctionid, item, MAX(bid) as maxbid, min(bid) as minbid, avg(bid) as avgbid FROM auction GROUP BY auctionid, item")// show some results aStatDF.show auctionid item maxbid minbid avgbid 3016429446 palm 193.0 120.0 167.549 8211851222 xbox 161.0 51.0 95.98892857142857
Summary
This concludes the first in a series which will discuss some MapReduce design patterns implemented with Spark. This discussion was very condensed, for more information on the patterns refer to the MapReduce design patterns book, for more information on Spark Pair RDDs refer to the Learning Spark Key value Pairs chapter.
References and More Information
- Free Interactive ebook – Getting Started with Apache Spark: From Inception to Production
- MapReduce design patterns book
- methods for aggregations on a DataFrame
- FREE Spark on demand training
| Reference: | MapReduce Design Patterns Implemented in Apache Spark from our JCG partner Carol McDonald at the Mapr blog. |
