To the naked eye, benchmarking might seem as a simple matter of just timing how long does it take for certain pieces of code to execute. But more often than not, that’s the naive approach. Providing a meaningful benchmark that has accurate and reproducible results is no simple task.
In this post we’d like to introduce you to the OpenJDK code tools project, and especially JMH. The Java Microbenchmarking Harness. We’ve been aware of it for some time now, but it grabbed our attention again when we saw that it will be used extensively during the development of Java 9.
The Benchmarking Challenge
So why is it that the plain timing style of t2-t1 doesn’t work? Unless you’re monitoring a live system, there are many factors at play that may influence your benchmark results and invalidate them. If you’re not using a standardized benchmarking tool like JMH, the results will often be questionable. And don’t forget common sense. The most important factor is common sense.
Generally, the trouble is caused by specific system and VM optimizations that can tilt the result in one of the tested use cases, while not kicking in yet the other test case. For the best, or for the worst. Issues like unexpected GC, warmup times, dead code elimination, various JIT compiler optimizations, run to run variance, CPU quirks and the list goes on and on. All factors that aren’t necessarily related to the actual thing that you’re to benchmark.
Which… Created this variation on the popular quote by Turing Award winner Donald Knuth:

To get a more in-depth view of how JMH addresses these issues, check out this talk and blog by Aleksey Shipilev.
Getting started with JMH
Setting up your project for using JMH can be done in 2 ways, as a standalone project or by adding the dependencies as part of an existing project using maven. The instructions are available on the official page right here. By the way, JMH also supports other JVM languages like Scala, Groovy and Kotlin.
Once you’ve set up your environment, it’s time to move to the actual code. JMH is an annotation driven framework, let’s see what it mean in practice through an example.
Sample benchmark: Comparing URL verification
In this test we’ll compare 2 different approaches to validating URLs with Java:
1. Using the java.net.URL constructor. If the constructor fails because the URL is invalid, it throws a MalformedURLException. To make the test more interesting two more variations were added, limiting the stack trace depth to 6 methods and cancelling the stack trace altogether.
2. Using regex, a quite monstrous regex to say the least, muhaha. If the URL doesn’t fit the pattern, we conclude that it’s invalid.
The results will help us get a definitive answer to this question so it’s time to place your bets. Let us know if you got it right in the comments section below :)

A huge thanks goes out to Hardy Ferentschik who allowed us to share his use case with the Takipi blog readers. Hardy is a principal engineer at RedHat, working on the Hibernate team, and the project lead of Hibernate Validator.
The full source code for the benchmark is available on GitHub. We recommend opening it in the closest tab and using the rest of this section as a reference manual.
1. Benchmark setup
1 2 3 4 | @BenchmarkMode(Mode.AverageTime)@Warmup(iterations = 1)@Measurement(iterations = 2)@OutputTimeUnit(TimeUnit.NANOSECONDS) |
And here’s the explanation of what’s going on:
@BenchmarkMode
First stop, picking which benchmark mode we’re going to use. JMH offers us 4 different modes: Throughput, AverageTime, SampleTime (including percentiles) and SingleShotTime (for running a method once). Any combination of these is also perfectly legitimate.
@Warmup(iterations = 1)
The number of warmup iterations.
@Measurement(iterations = 2)
The number of actual measurement iterations. In this sample benchmark we’re having 2 iterations and then averaging the score.
@OutputTimeUnit(TimeUnit.NANOSECONDS)
The time unit of the output results, any value of java.util.concurrent.TimeUnit that makes sense to you.
2. Benchmark Scope – Initial state
After we’ve got the setup we need to set up the initial state of the benchmark. In this case, it includes the URLs we’ll be testing, the class for the regex test and the class for the URL constructor test.
Each of these classes should be annotated by @State(Scope.Benchmark)
Also, for the URLs list, notice the @Param annotation for feeding different values to the benchmark:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 | @State(Scope.Benchmark) public static class URLHolder { @Param(value = { // should match // should not match "http//foo/", "///a", ":// should fail" }) String url;} |
3. The benchmark code
Now that we have the configuration and initial state set up, we can advance to the actual benchmark code.
1 2 3 4 5 | @Benchmark@Fork(1)public boolean regExp(ValidateByRegExp validator, URLHolder urlHolder) { return validator.isValid( urlHolder.url );} |
@Benchmark
Marks this method as the benchmark.
@Fork(1)
The number of trials to run. Each run starts in a different JVM. Through this annotation you can also provide the JVM arguments that you’d like to include in the test. So for the limited stack trace test, we see @Fork(value = 1, jvmArgs = “-XX:MaxJavaStackTraceDepth=6”) in use.
4. Running the test
Using the Options pattern:
1 2 3 4 5 6 | public static void main(String[] args) throws Exception { Options opt = new OptionsBuilder() .include( ".*" + URLConstraintBenchmark.class.getSimpleName() + ".*" ) .build(); new Runner( opt ).run();} |
** This is by no means a complete guide, just a quick tutorial to help get you familiarized with the concepts. For a complete set of examples, check out the official OpenJDK sample code right here.
The Results
In case you were curious, here are the results reported in nanoseconds. Time to see if your bets were right. The top 3 URLs are legal and the bottom 3 are invalid:
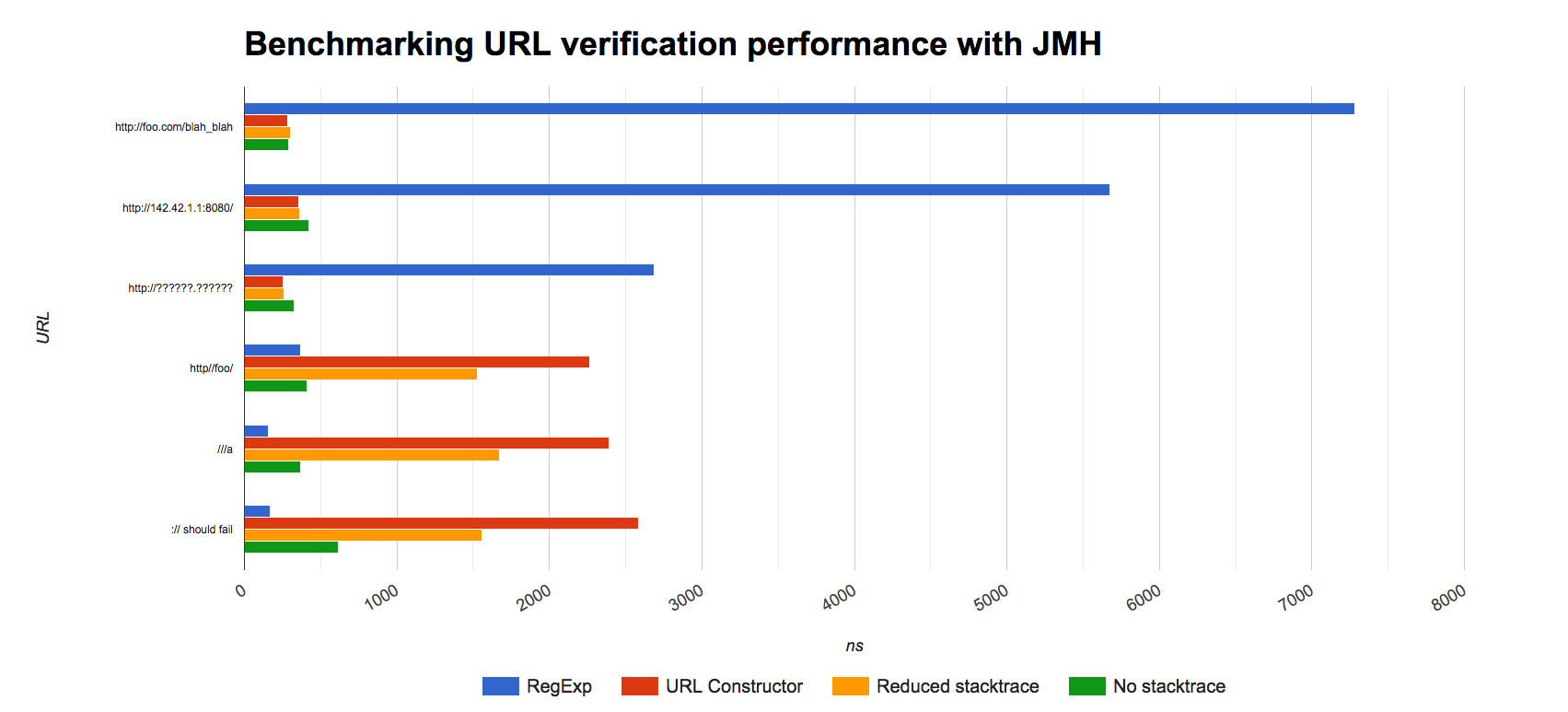
We see that if it’s a valid URL then the regex way of validating is pretty bad. It received the worst results across all of our valid URLs. On the other hand, we see that if the URL is invalid, the table turns and the regex gets the best results.
On the URL Constructor front, we see no significant differences on the valid URLs. Each of the variations provided pretty much te same results, getting ahead of the regex. When it comes to invalid URLs with a MalformedURLException added to the mix, there’s another thing to consider: the stack trace of the exception. Slowing down the operation as opposed to the clean (yet monstrous) regex version.
So what’s the best pick? The URL constructor way of doing things will be best assuming most of your data will include valid URLs. Although on certain cases it might be better using a regex, if you’re assuming a big majority of URLs will be invalid.
Who uses JMH to benchmark their code?
First and foremost, JMH was built as an internal code tool for the OpenJDK project. As Aleksey Shipilev, Oracle’s Java performance expert and the lead for the JMH project, tells us:
“JMH scratches our own itch: performance work on OpenJDK itself. As such, we have lots of feature-specific benchmarks that assess the performance of the code in development. Many performance bugs are reported with a JMH-driven benchmark to showcase the behavior we are seeing, and provide the easy test case to validate the JDK changes.”
As we discussed, since the accuracy of a benchmark mostly depends on how it handles the various optimizations and variations in the system behavior, there’s no better team to build such tool than the OpenJDK team themselves. The same team that builds the JVM and includes most of those useful (yet hard to benchmark) optimizations.
Since the team working on JMH is so close the underlying VM, it has been favored over other tools and can be found in use with many Java and Scala libraries and tools. Some notable examples include Twitter’s Fingale and misc utilities for use in production, Jersey, Square Okio, various Apache projects, Hibernate, and many more.
Final Thoughts
When it comes down to benchmarking, like many other core Java issues, the OpenJDK team and resources are often the best place to look for answers. JMH is an easy to use alternative to home grown (and mostly erroneous) microbenchmarks. Although by no means it frees you from using common sense to make sure your benchmarks are correct! We hope you’ve found this resource useful and will keep on exploring the use of JMH for creating meaningful benchmarks and sharing your findings with the Java community. This week we’d also like to share some of the new progress we’ve made at Takipi. If you haven’t seen it in action yet, here’s everything you need to know to get started.
| Reference: | Java 9 Code Tools: A Hands-on Session with the Java Microbenchmarking Harness from our JCG partner Alex Zhitnitsky at the Takipi blog. |
