Processing data from social media streams and sensors devices in real time is becoming increasingly prevalent, and there are plenty of open source solutions to choose from. Here is the presentation that I gave at Strata+Hadoop World, where I compared three popular Apache projects that allow you to do stream processing: Apache Storm, Apache Spark, and Apache Samza. This blog post is a summary of this presentation.

The landscape overall is that stream processing is fundamentally simple…except that it’s really not simple at all! The optimizations are the key to making these stream processing systems work, as well as how you’re handling back pressure into these systems. Kafka is one of the common pieces of these stream processing engines that really help deliver the greatest level of functionality.
If you ask three different people, “Which streaming platform is the fastest?” you will get three different answers. Also, if you take a close look at what the use cases are, you will start to notice that depending on the use case, technology, and implementation style, your performance and your mileage is going to vary.
You may think that Storm is the greatest thing since sliced bread, or you may think it’s the worst thing since sliced bread. You may have had great experiences implementing on any one of these, or you may have had horrible experiences implementing on any of the others. For this reason, it’s really tough to get a good conversation on what the real facts are between these platforms.
Let’s take a look at delivery patterns. You have:
- At-most-once, where you have the possibility for data loss, you accept it, and it’s no big deal.
- At-least-once, where messages may be redelivered (no loss, but you’ll have duplicates). If your data is idempotent, then you are good; this is the model you should be working with, and you should never consider exactly-once.
- Exactly-once: each message is delivered once and only once (no loss, no duplicates). If you have a use case that requires exactly-once, be very careful, because no matter what you do or how you handle it, when you start dealing with exactly-once semantics in distributed systems, the complication level goes through the roof. This is why I have a ton of respect for the people working on the stream processing systems that are out there, because they know this and they’re not lying about the capabilities of these platforms. Anyone who tells you that exactly-once is easy is probably feeding you a line. It’s very difficult to do, and there are big trade-offs that get made when you want to move into an exactly-once model. You should be aware of this and really think through how you want to utilize a stream processing engine in your use case to meet your business needs.
Today’s Options – Apache Style
The fundamental thing to note here is all three are real-time computation systems, they’re open source, they’re low latency, they’re distributed, they’re scalable, and they’re fault tolerant.
Apache Samza
Apache Samza is probably the least well known, and it gets the least talking time among the open source streaming engines that are out there. I think it’s probably the most underappreciated. There are some things that this technology has put together that make it very simple. I have an appreciation for simple architectures, because the more moving pieces you have in an architecture, the more complicated things are.
Streams & Partitions
- Stream: immutable messages
- Each stream comprises one or more partitions
- Partition: totally ordered sequence of messages
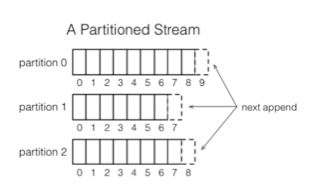
When we’re dealing with streaming, we want to have a way to parallelize our work. This is Samza’s way of breaking work up—you define a key, your data gets partitioned, and you get the performance you want. The threading model that’s in place for Samza is different than what you’ll see for Storm. If that’s something that you care about—resource utilization, management, being able to properly plan for the resource consumption by these jobs, then this is something you should probably pay attention to. The important piece here is that everything is always ordered.
Jobs & Tasks
The next concept that we have is jobs and tasks. This is actually the worker code, and this is what’s going to get deployed and distributed. This is where your business logic is effectively going to live.
This is parallel to the concept of a dataflow graph, for anyone who is familiar with topologies in Storm. They’re functionally similar, but implementation-wise they are not even close. The simplicity that Samza brings means that you’re going to use Kafka in front of this, and because of that, Samza is going to put everything back into Kafka in between every one of these stage gates.
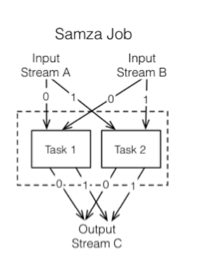
Samza Architecture
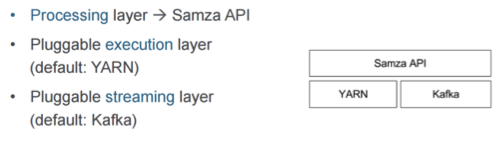
In terms of deploying and running Samza, you can plug other resource managers in beyond YARN; there are no others currently plugged in. You can plug in other queuing systems in front of Samza, as there are currently no other implementations.
How do you actually manage the containers that are deployed here? This is something I would consider a strength again, because your work is partitioned up, it’s easy to predict, and you know where things are going to land. Fundamentally, this is the core of Samza. There are lots of very important implementation details that I can’t even begin to cover, so please check out the resources listed below.
Apache Samza Resources
Apache Storm
Apache Storm does certain things very well, and it does other things very painfully. Storm is based on tuples and streams. A tuple is basically what your data is and how it’s structured. I often hear Storm compared to Spark Streaming. One of the biggest fundamental differences between the two is that Storm works on individual events as Samza does, and Spark Streaming works on micro-batches.
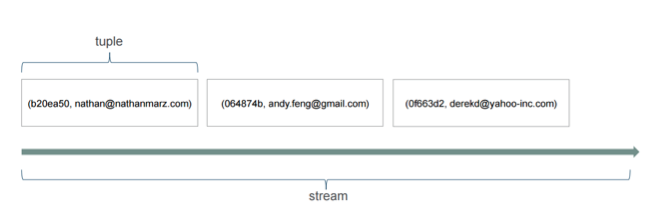
The graphic above shows what it looks like. On the Spark Streaming side, you could conceptually think that all of the concepts of those tuples are all just one event on the stream, conceptually.
Spouts
Moving forward, we’ve got the concept of spouts with Storm. If you’re familiar with Flume, I would consider this to be a source in Flume. Spouts can talk with queues (Kafka, Kestrel, etc.), web logs, API calls, file systems (MapR-FS/HDFS), etc.
Bolts
Bolts are used to process tuples and create new streams. You can implement business logic via Transform, Filter, Aggregate, and Join. You can access datastores, databases, and APIs. The important thing to understand is that you shouldn’t mix all of your functionality in a single bolt, because you’re not going to be able to mix and match those later. You should separate them out and chain them together into topologies.
Topologies
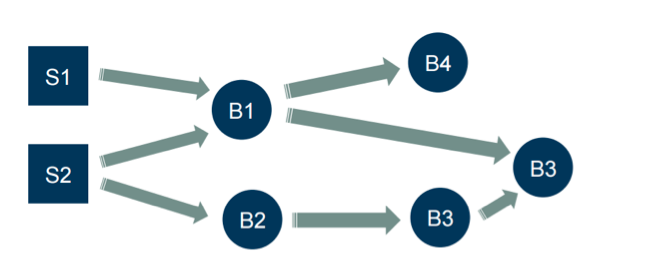
Topologies are basically a directed graph of spouts and bolts, as shown above. Like Samza, if you want to tie the code together, you’ve got a model for it.
Stream Grouping
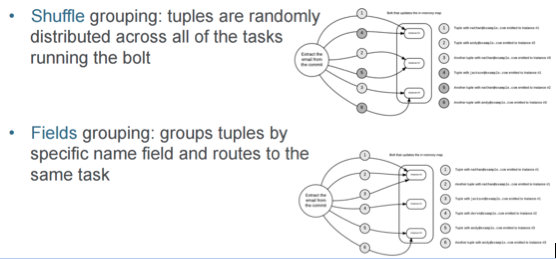
The next concept that we’ve got is the stream grouping concept. The graphic above shows two examples —shuffle and fields. There are actually seven different grouping models that you can use in Storm. It’s got some good flexibility, and things have been thought out reasonably well. Conceptually, you need to decide how you want your messages to be handled, where you want them to go, and which workers to use. When you look at this model for how to manage your events that are coming through, you really should read through all of the descriptions to make sure that you’re meeting your expectations; you could very easily pick the wrong one and bombard your system by sending the same message to every single bolt you have.
Tasks and Workers
Conceptually, tasks and workers are fundamentally not very different from how Samza handles it. With a task, each spout/bolt executes as many threads of execution across the cluster. A worker is a physical JVM that executes a subset of all the tasks for the topology. It is slightly different based on the native build of Samza with YARN.
Here’s where Storm starts to get interesting—I hear a lot of people talk about Trident, which delivers a set of features on Storm that make it more competitive, feature for feature, with the other frameworks.
Trident-the ‘Cascading’ of Storm
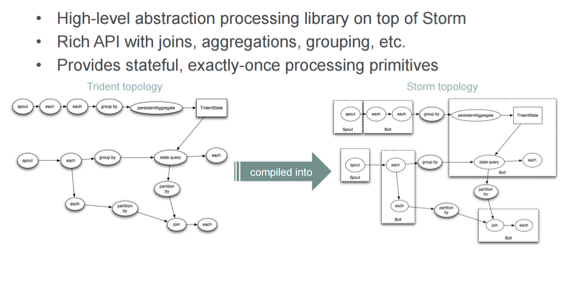
The big advantage here is you actually get the exactly-once semantic with Trident. If that’s important to you, it’s good. Conceptually, what happens is that these Trident topologies get compiled into Storm topologies. Personally, I don’t necessarily always like that model of having to go from one to the other.
Execution
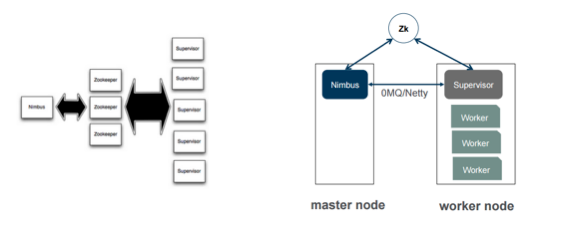
In terms of execution, one of the things to be aware of is the concept of Nimbus in Storm. You may say that Nimbus is a single point of failure. Technically, it is, but it’s not really a detrimental single point of failure due to how it operates. It can be spun back up really fast if it crashes, and it doesn’t have any downstream impact on anything that’s already running. Although it’s a single point of failure, it’s not a huge point of concern for me. If I were implementing it at my organization, it would probably be one of the least concerns I would have about implementing Storm.
Please read through the resources for Apache Storm which are listed below, as there are a lot of details related to Storm that I’m not able to cover here.
Apache Storm Resources
Apache Spark
Spark Streaming is getting some fantastic adoption, in part due to the fact that it plays with the rest of the Spark framework. It has access to all of the components that are part of Spark, and there’s some power that comes along with that. If you’re already using Spark for other things, this may influence your decision for which streaming framework to use.
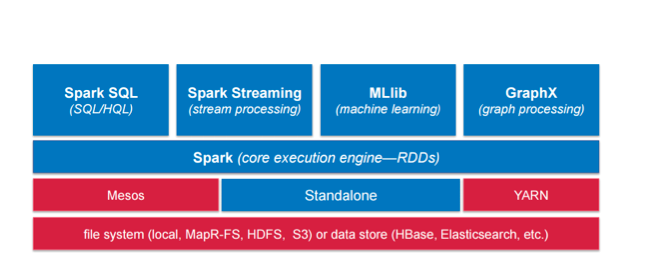
Let’s take a look at cluster managers. Right off the top, you’ve got a Spark driver. If that driver crashes, you need to restart it. There’s been a lot of work done in previous releases that have made this more resilient and highly available.
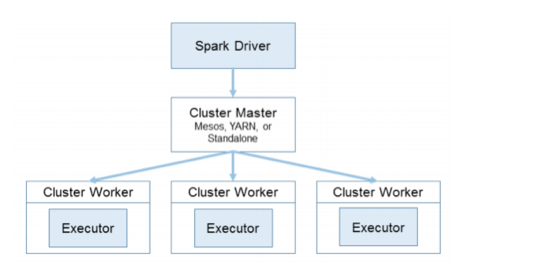
This is where people really pay attention to this framework. From a standalone perspective, you can run it, you can run it on EC2, you can run it on YARN, and you can run it on Mesos. Your mileage will likely vary in functionality for each of these, depending on what you need and what you require. From my experience, you will likely get the best performance with Mesos, as it was the first product that all of this was built for. However, if you don’t use Mesos, it works with all the rest, too.
RDD Operations
The differentiator here for Spark Streaming comes by way of RDDs—resilient distributed data sets. This is where these streams come in; the data is then put into an RDD, and you have all of the functional and computational abilities that Spark delivers at your fingertips in this framework. Again, if you have any predisposition to Spark, you likely will choose this; you should really educate yourself on everything else that you have at your fingertips. The transformations are the strength here. Having all of this available to you from the RDDs is where you’re going to see the biggest benefits for this framework.
Spark Streaming

- High-level language operators for streaming data
- Fault-tolerant semantics
- Support for merging streaming data with historical data
Exactly-once is extremely difficult to do in a distributed system; making it perfect is darn near impossible. There are a number of different companies that build distributed systems in different ways, and every one of them will tell you how complicated it is. That being said, there are parts here that will work well, but it doesn’t necessarily mean that you have a one hundred percent guarantee across all use cases against data loss. You’ll need to figure out what your use cases are and what they mean to your implementation.
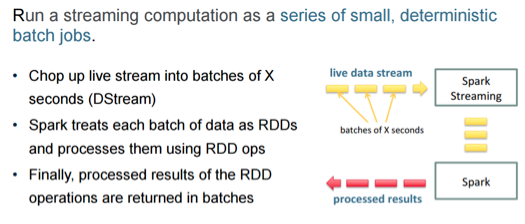
The primitive concept here is actually the DStream. Your data comes in the DStream, you have access to it, you do your data processing, you have your results, and you’re probably going to get pretty good performance right out of the box.
The important thing here is that with micro-batches, as opposed to single record, you’re going to have certain latency and certain minimum window times that you can operate on. For example, if you have a very slow stream at certain times of the day, but you have a really fast stream at other times of the day, your window time that you batch these in could have a big impact on you. For example, if you end up with 500 events in a window at your peak time of day, but then every window has one event, you’re probably not going to be happy at the end of the end when you have RDDs with one object each in them, as you may see negative performance impact. You have to consider your use cases for the data coming through and how this is all working together. Think about this as you start testing these out; it’s important to understand what your usage patterns really are.
Spark Streaming: Transformations
- Stateless transformations
- Stateful transformations
- Checkpointing
- Windowed transformations
Stateless and stateful transformations—do you maintain state in between iterations? Checkpointing is invaluable if you have to restart your process. If you have a long series of operations, you will want to checkpoint periodically, so that if your driver crashes, you can replay it from a checkpoint.
Spark Streaming: Execution
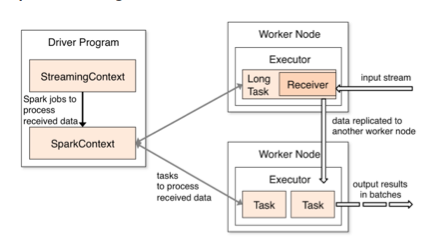
The receiver here is going to be similar to a spout in Storm. This is considered a much heavier piece of code to run than what you would see in Storm, as the receivers are kind of big. You end up consuming a lot of memory in order to run your receivers. However, I don’t hear a lot of negative comments about Spark in the community.
Apache Spark Resources
Comparison
Samza vs Storm vs Spark
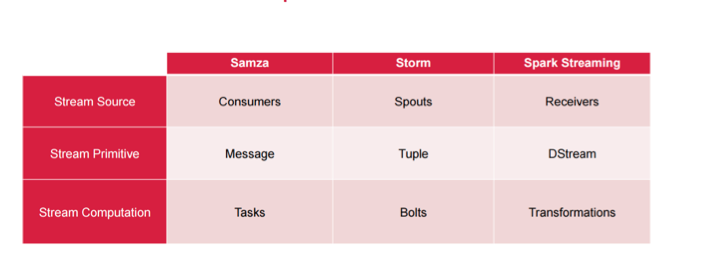
Terminology-wise, these are the rough equivalents between each of the frameworks. When you look at the primitives—message, tuple, and DStream, it’s not very complicated. If you wanted to do a full evaluation of what’s going to work best for you, you could use this as your checkbox guide to see if any of these specific components are better for your implementation model than the others. Of course, that’s after you’ve decided exactly what semantics are required, and if at-least-once is good enough.
vs Storm vs Spark
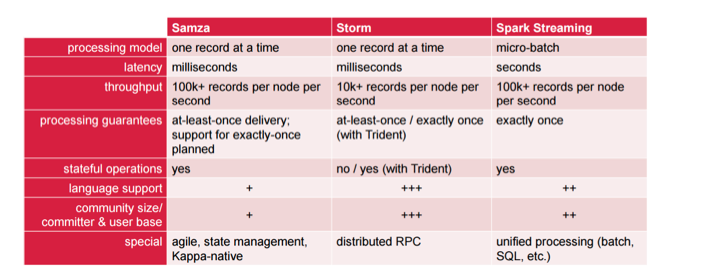
This grid is a little more complicated. The processing model options are one record at a time vs. micro-batch. This has a very big impact on performance possibilities, and it directly leads into latency, which is seconds for Spark Streaming. With throughput, it really depends on the needs of your particular use case. In terms of processing guarantees, Samza has support planned for exactly-once, but it’s not there yet. If you need exactly-once with Storm, you can use Trident.
Language support will most likely be a big deciding factor. If you require multiple languages for interaction, you’re going to have a really tough time with Samza, because you can have Java Virtual Machine-based languages only. If you are cool with that and with Python, then you’re cool with Spark Streaming. If you need a bunch of other languages, you’re almost locked out of those two options, and you’re going to need to choose Storm.
When to use what?
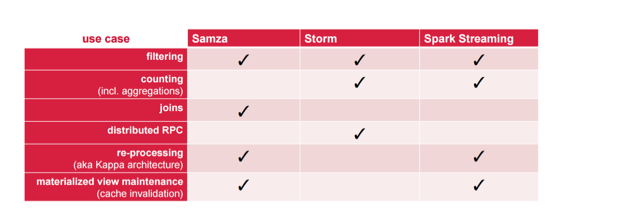
The big one for me is the concept of Kappa-native. It’s the concept of reprocessing. In my opinion, reprocessing is one of the most important things in any of these streaming frameworks. If you change your code in the future and you want to reprocess the events that have happened, you need to be able to handle reprocessing. It’s a big standout feature that I think too many people overlook.
Now does this mean that the lack of checkboxes in the other areas means they don’t have it? No. Please note that the purpose of this table is to show the strength areas of each of these projects. For example, if you want to do counting, then Samza isn’t just the best option in most cases.
In this blog post, I reviewed three open source stream processing frameworks: Apache Storm, Apache Spark, and Apache Samza.
Since this presentation was given, Apache Flink has also become a viable option to consider, as it is a streaming-first processing engine with stellar performance with exactly-once processing models.
Apache Flink Resources
Please take a look at the following in-depth resources to help you in your decision-making process, and feel free to ask any questions in the comments section below.
| Reference: | Stream Processing Everywhere – What to Use? from our JCG partner Jim Scott at the Mapr blog. |
