Java developer? Takipi replaces logging in production JVMs and lets you see the source code, call stack, and variable state behind all logged errors, warnings, and exceptions – Try Takipi
The dark side of microservices: What can possibly go wrong?
It seems like everyone are into microservices these days, while monolith architectures are just as popular as crumbling down old and abandoned castles.
The public attention certain trends get is often exaggerated and doesn’t reflect what’s going on in practice, but this time it feels more like a consensus. Microservices iterate over the basic separation of concerns principle and put a name on insights from teams of engineers who crafted solutions to real problems they needed to solve.
In this post, we’ll play the devil’s advocate, share some insights from the community and our users, examine the top issues with microservices in production – And how you can solve them.
New Post: 5 Ways to NOT F**K Up Your Microservices in Production https://t.co/RfdxwrE5qm pic.twitter.com/I5J1h0JEUW
— OverOps (@overopshq) May 5, 2016
The flip side of microservices
Separation of concerns is not a new concept, neither distributed computing. The benefits are huge, but they come at a price which usually translates to higher ops costs both in time and money. Mix the two, and you get a petri dish of all sorts of awkward problems. Put it in production, and the problems quadruple. Debugging to the rescue, but oh wait…
Debugging is not about making problems go away.
As Bryan Cantrill points out on his talk in QCon, “debugging devolved into an oral tradition, folk tales of problems that were made to go away”. When in fact, it is more like a science, understanding how the system really works and not how we THINK it works.
Debugging is not just minor side task, it’s a fundamental issue. Sir Maurice Wilkes, debugger of one of the first programs ever created, already realized the major role debugging is going to play for developers:
“In 1949 as soon as we started programming, we found to our surprise that it wasn’t as easy to get programs right as we had thought. Debugging had to be discovered. I can remember the exact instant when I realised that a large part of my life from then on was going to be spent in finding mistakes in my own programs”.
We were made into thinking that it’s just about making problems go away. When the real challenge is about understanding how the system really works.
Problem #1: As if monitoring a monolith wasn’t hard enough
Whether you’re gradually breaking down a monolithic app to microservices or building a new system from scratch, you now have more services to monitor. Each of these is highly likely to:
– Use different technologies / languages
– Live on a different machine / container
– Have its own version control
The point is that monitoring wise, the system becomes highly fragmented and a stronger need arises for centralized monitoring and logging, to have a fair shot at understanding what’s going on.
For example, one of the scenarios described in a recent Continuous Discussions podcast was a bad version that needs to be rolled back. Mostly a straightforward procedure for monoliths. But… We have microservices now. So we need to identify which of the services needs to be rolled back, what would be the impact of the rollback on the other services, or maybe we just need to add some capacity, but then it could just push the problem to the next service in line.
Takeaway #1: If you thought monitoring a monolith architecture was hard, it’s 10x harder with microservices and requires a bigger investment in planning ahead.
Problem #2: Logging is distributed between services
Logs logs logs. GBs of unstructured text is generated by servers on a daily basis. The IT equivalent of carbon emission, in the shape of overflowed hard drives and crazy Splunk bills / ELK storage costs. btw, if you’re looking into Splunk or ELK, you should check out our latest eBook: Splunk vs ELK: The Log Management Tools Decision Making Guide.
With a monolith architecture, your logs are probably already scattered in different places, since even with a monolith mindset you probably had to use a few different layers that probably log to different places. With microservices – your logs break further down. Now when investigating a scenario related to some user transaction, you’ll have to pull out all the different logs from all the services that it could have gone through to understand what’s wrong.
In Takipi, our team solves this by using Takipi… on Takipi. For all log errors and warnings coming from production JVMs, we inject a smart link into the log which leads to the event’s analysis. Including it’s full stack trace and variable state at every frame, even if it’s distributed between a number of services / machines.
Takeaway #2: Microservices are all about breaking things down to individual components. As a side effect, ops procedures and monitoring are also breaking down per service and lose their power for the system as a whole. The challenge here is to centralize these back using proper tooling.
Problem #3: An issue that’s caused by one service, can cause trouble elsewhere
If you follow up on some broken transaction in a specific service, you don’t have the guarantee that the same service you’re looking at is to blame. Let’s assume you have some message passing mechanism between your services, like RabbitMQ, ActiveMQ, or maybe you’re using Akka.
There could be several possible scenarios going on, even if the service behaves as expected and there’s no problem to be found:
– The input it received is bad, and then you need to understand what made the previous service misbehave
– The recipient of its result returned some unexpected response, and then you need to understand how the next service behaves
– What about the highly likely scenario where these dependencies are more complex than 1:1? Or there’s more than one service that benefits to the problem?
Whatever the problem is, the first step with microservices is to understand where to start looking for answers. The data is scattered all over the place, and might not even live within your logs and dashboard metrics at all.
Takeaway #3: With monoliths you usually know that you’re looking at the right direction, microservices make it harder to understand what’s the source of the issue and where you should get your data from.
Problem #4: Finding the root cause of problems
Alright, let’s carry on with the investigation. The starting point now is that we’ve nailed down the problematic services, pulled out all the data there’s to pull, stack traces and some variable values from the logs. If you have an APM (Like New Relic, AppDynamics or Dynatrace, which we also wrote about here and here) you might also get some data about unusually high processing times for some of the methods / do some basic assessment of the severity of the issue.
But… What about… The actual issue? The real root cause? The code that’s actually broken.
In most cases, the first few bits of variable data you HOPEFULLY get from the log won’t be the ones that move the needle. They usually lead to the next clue which requires you to uncover some more of the magic under the hood and add another beloved log statement or two. Deploy the change, hope for the issue to reoccur, or not, because… sometimes merely adding a logging statement seems to solve issues. Some sort of a diabolical reverse Murphy’s law. Oh well.
Takeaway #4: When the root cause of an error in a microservice spans across multiple services, it’s critical to have a centralized root cause detection tool in place. If you’re using Java / other JVM languages, be sure to check out the stuff we do at Takipi.
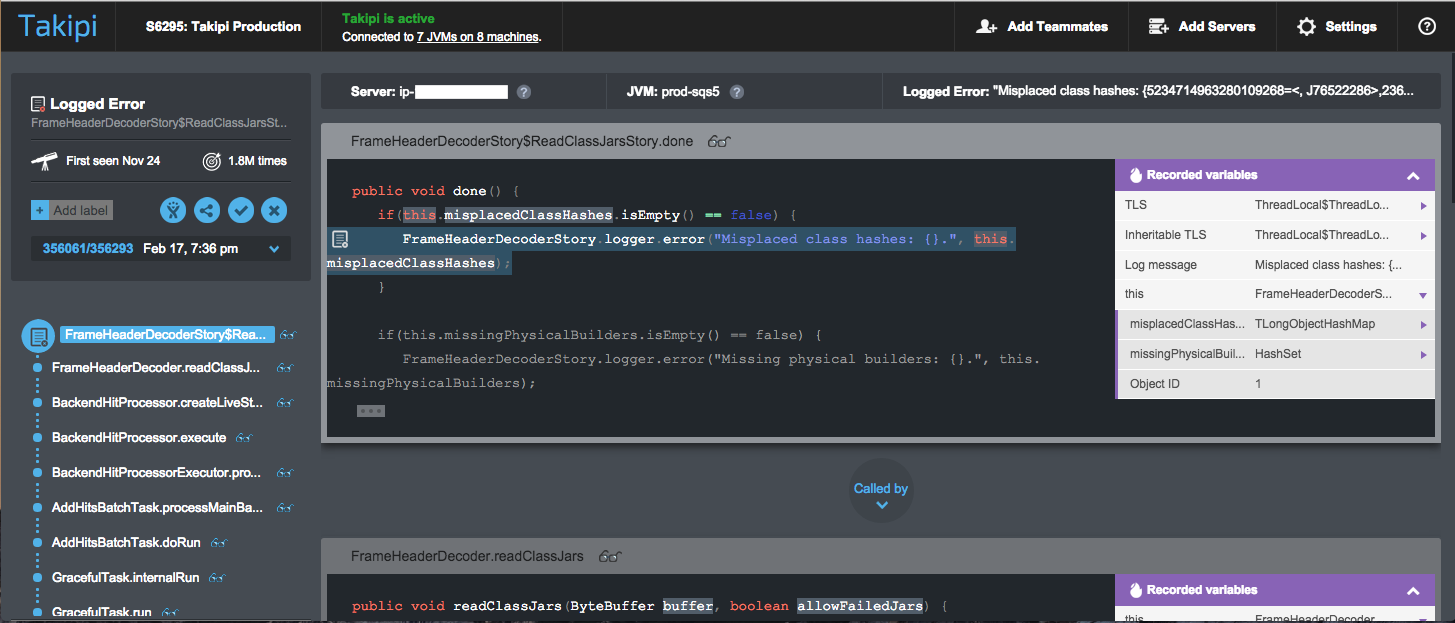
Takipi’s Error Analysis Dashboard – variable values overlaid on the actual code at every frame in the stack – See a live demo
Problem #5: Version management and cyclic dependencies between services
Another issue that was mentioned in the Continuous Discussions podcast that we’d like to highlight here is going from a layer model in a typical monolithic architecture, to a graph model with microservices.
Two problems that can happen here relate to keeping your dependencies in check.
1. If you have a cycle of dependencies between your services, you’re vulnerable to distributed stack overflow errors when a certain transaction might be stuck in a loop.
2. If two services share a dependency, and you update that other service’s API in a way that could affect them, then you’ll need to updated all three at once. This brings up questions like, which should you update first? And how to make this a safe transition?
More services means different release cycles for each of them which adds to this complexity. Reproducing a problem will prove to be very difficult when it’s gone in one version, and goes back in a newer one.
Takeaway #5: In a microservice architecture you’re even more vulnerable to errors coming in from dependency issues.
Final Thoughts
Debugging immediately gets you in the mindset of making problems go away, this is literally the direct meaning of the word debugging. When you think of it with the system’s context in mind, there’s much more to it than ad hoc problem solving. It’s about understanding the system as a whole, what makes it tick, and how things really are versus how you hope they’d be.
At the bottom line, it’s all about the tools you use and the workflows you employ. This is precisely what we had in mind while building Takipi, solving these exact type of issues, and turning the world of application logs upside down to face the current state of production applications.
Java developer? Takipi replaces logging in production JVMs and lets you see the source code, call stack, and variable state behind all logged errors, warnings, and exceptions – Try Takipi
| Reference: | 5 Ways to NOT Mess Up Your Microservices in Production from our JCG partner Alex Zhitnitsky at the Takipi blog. |
