In the blog post Apache PDFBox 2, I demonstrated use of Apache PDFBox 2 as a library called from within Java code to manipulate PDFs. It turns out that Apache PDFBox 2 also provides command-line tools that can be used directly from the command-line as-is with no additional Java coding required. There are several command-line tools available and I will demonstrate some of them in this post.
The PDFBox command-line tools are executed by taking advantage of PDFBox’s executable JAR (java -jar with Main-Class: org.apache.pdfbox.tools.PDFBox). This is the JAR with “app” in its name and, for this particular blog post, is pdfbox-app-2.0.2.jar. The general format used to invoke these tools in java -jar pdfbox-app-2.0.2.jar <Command> [options] [files].
When the executable JAR is executed without arguments, a form of help is provided that lists the available commands. This is shown in the next screen snapshot.
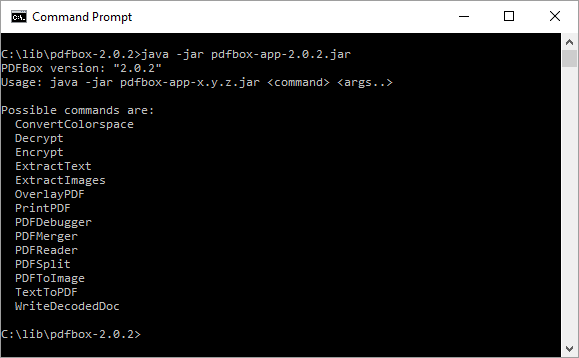
This screen snapshot shows that this version of Apache PDFBox (2.0.2) advertises support for the “Possible commands” of ConvertColorspace, Decrypt, Encrypt, ExtractText, ExtractImages, OverlayPDF, PrintPDF, PDFDebugger, PDFMerger, PDFReader, PDFSplit, PDFToImage, TextToPDF, and WriteDecodedDoc.
Extracting Text: “ExtractText”
The first command-line tool I am looking at is extracting text from a PDF. I demonstrated using PDFBox to do this from Java code in my previous blog post. Here, I will use PDFBox to do the same thing directly from the command-line with no Java source code in sight. The following operation extracts the text from the PDF Scala by Example. In my previous, post the Java code accessed this PDF online and used PDFBox to extract text from it. In this case, I’ve downloaded the Scala by Example and am running the PDFBox ExtractText command-line tool against that downloaded PDF stored on my hard drive at C:\pdf\ScalaByExample.pdf.
The command to extract text from the PDF from the command-line using PDFBox is: java -jar pdfbox-app-2.0.2.jar ExtractText C:\pdf\ScalaByExample.pdf. The next two screen snapshots demonstrate running this command and the file it generates. From these screen snapshots, we can see that the text file generated by this command by default has the same name as the source PDF but with a .txt extension. This command supports multiple options including the ability to specify the name of the text file by placing that name after the source PDF’s file name and the ability to write the text to the console instead of to a file via the -console flag (from which the output could be redirected). Examples of how to specify a custom text file name and how to direct text to console instead of file are shown next.
- Explicitly Specifying Text File Name:
java -jar pdfbox-app-2.0.2.jar ExtractText C:\pdf\ScalaByExample.pdf C:\pdf\dustin.txt
- Rendering Text on Console
java -jar pdfbox-app-2.0.2.jar ExtractText -console C:\pdf\ScalaByExample.pdf
PDF from Text: “TextToPDF”
When it is desirable to go the other way (start with text as the source and generate a PDF), the command TextToPDF is appropriate. To demonstrate this, I’m using a source text file called doi.txt that contains a portion of the United States Declaration of Independence:
The unanimous Declaration of the thirteen united States of America, When in the Course of human events, it becomes necessary for one people to dissolve the political bands which have connected them with another, and to assume among the powers of the earth, the separate and equal station to which the Laws of Nature and of Nature's God entitle them, a decent respect to the opinions of mankind requires that they should declare the causes which impel them to the separation. We hold these truths to be self-evident, that all men are created equal, that they are endowed by their Creator with certain unalienable Rights, that among these are Life, Liberty and the pursuit of Happiness
With a sample text file in place at C:\pdf\doi.txt, PDFBox’s TextToPDF can be run against it. The command, java -jar pdfbox-app-2.0.2.jar TextToPDF C:\pdf\doi.pdf C:\pdf\doi.txt (note that the target PDF is listed as the first argument and the source text file in listed as the second argument). The next three screen snapshots demonstrate running this command the successful generation of a PDF from the source text file.


Extracting Images from PDFs: “ExtractImages”
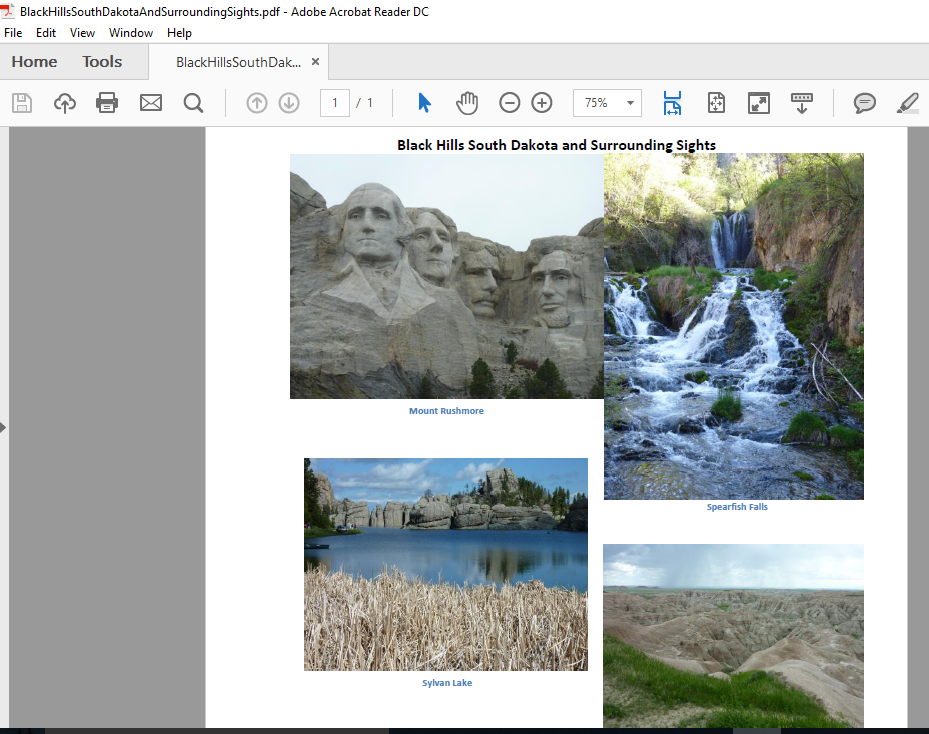
The PDFBox command-line tool ExtractImages makes it as easy to extract images from a PDF as the command-line tool “ExtractText” made it to extract text from a PDF. My demonstration of this capability will extract four images from a PDF I created with images from the Black Hills (and surrounding area) of South Dakota that is called BlackHillsSouthDakotaAndSurroundingSights.pdf. A screen snapshot of this PDF is shown next.
PDFBox can be used to extract the four photographs in this PDF with the command java -jar pdfbox-app-2.0.2.jar ExtractImages C:\pdf\BlackHillsSouthDakotaAndSurroundingSights.pdf as demonstrated in the next screen snapshot.
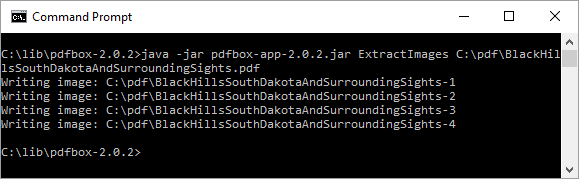
Running this command as shown in the last screen snapshot extracts the four images from the PDF. Each extracted image is named after the source PDF with a hyphen and counting integer appended to the end of the name. The generated images are also JPEG files with .jpg extensions. In this case, the names of the generated files are thus BlackHillsSouthDakotaAndSurroundingSights-1.jpg, BlackHillsSouthDakotaAndSurroundingSights-2.jpg, BlackHillsSouthDakotaAndSurroundingSights-3.jpg, and BlackHillsSouthDakotaAndSurroundingSights-4.jpg and each is displayed next in the form extracted directly from the PDF.
| BlackHillsSouthDakotaAndSurroundingSights-1.jpg | BlackHillsSouthDakotaAndSurroundingSights-2.jpg |
|---|---|
 |  |
| BlackHillsSouthDakotaAndSurroundingSights-3.jpg | BlackHillsSouthDakotaAndSurroundingSights-4.jpg |
 |  |
Encrypting PDF: “Encrypt”
Apache PDFBox makes it easy to encrypt a PDF. For example, I can encrypt the PDF used in the “ExtractImages” example with the following command: java -jar pdfbox-app-2.0.2.jar Encrypt -O DustinWasHere -U DustinWasHere C:\pdf\BlackHillsSouthDakotaAndSurroundingSights.pdf as shown in the next screen snapshot:

Once I’ve run the encrypt command, I need a password to open this PDF in Adobe Reader:
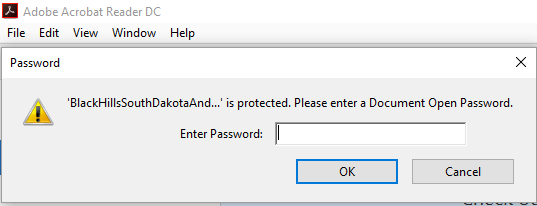
Decrypting PDF: “Decrypt”
It’s just as easy to decrypt this PDF with the command java -jar pdfbox-app-2.0.2.jar Decrypt -password DustinWasHere C:\pdf\BlackHillsSouthDakotaAndSurroundingSights.pdf as shown in the next screen snapshot. The image demonstrates that an InvalidPasswordException is thrown when no password is provided (or the wrong password is provided) for decrypting the PDF and then it shows a successful decryption and I’m once again able to open the PDF in Adobe Reader without password.
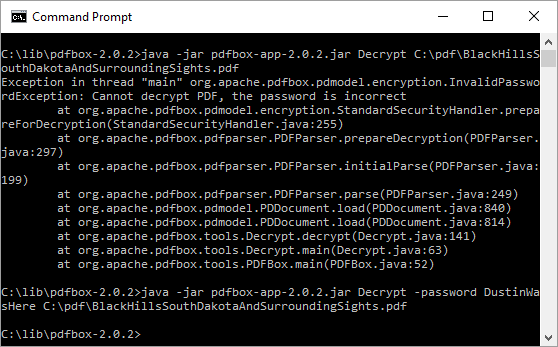
Merging PDFs: “PDFMerger”
PDFBox allows multiple PDFs to be merged into a single PDF with the “PDFMerger” command. This is demonstrated in the next screen snapshots by merging the two single-page PDFs mentioned earlier (doi.pdf and BlackHillsSouthDakotaAndSurroundingSights.pdf into a new PDF called third.pdf with the command java -jar pdfbox-app-2.0.2.jar PDFMerger C:\pdf\doi.pdf C:\pdf\BlackHillsSouthDakotaAndSurroundingSights.pdf C:\pdf\third.pdf.


Splitting PDFs: “PDFSplit”
I can split the third.pdf PDF just created with PDFMerger with the command PDFSplit. This is a particularly simple case because the PDF being split is only two pages. The command is demonstrated with the next screen snapshots.


The snapshots demonstrate that the PDFs split out of third.pdf are called third-1.pdf and third-2.pdf.
Conclusion
In this post, I showed several of the command-line utilities available out-of-the-box with no Java coding required. There are a few other command-line utilities available that were not demonstrated here. All of these commands are easily used by running the executable “app” JAR provided with a PDFBox distribution. As command-line utilities, these tools enjoy the advantages of command-line tools including being quick to run and able to be included within scripts and other automated tools. Another benefit of these tools is that, because they are implemented in open source, developers can use the source code for these tools to see how to use the PDFBox APIs in their own applications and tools. Apache PDFBox‘s command-line tools are freely available and easy-to-use PDF manipulation tools that can be used with no extra Java code being written.
| Reference: | Apache PDFBox Command-line Tools: No Java Coding Required from our JCG partner Dustin Marx at the Inspired by Actual Events blog. |
