Co-authored by Jean-Francois Puget (@JFPuget)
Machine Learning represents the new frontier in analytics, and is the answer of how many companies can capitalize on the data opportunity. Machine Learning was first defined by Arthur Samuel in 1959 as a “Field of study that gives computers the ability to learn without being explicitly programmed.” Said another way, this is the automation of analytics, so that it can be applied at scale. What is highly manual today (think about an analyst combing thousand line spreadsheets), becomes automatic tomorrow (an easy button) through technology. If Machine Learning was first defined in 1959, why is this now the time to seize the opportunity? It’s the economics.
A relative graphic to explain:
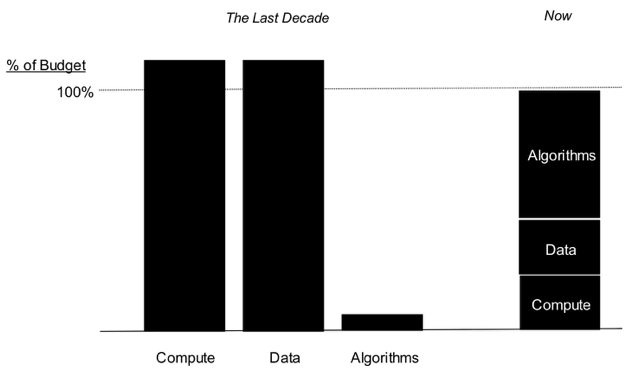
Since the time that Machine Learning was defined and through the last decade, the application of Machine Learning was limited by the cost of compute and data acquisition/preparation. In fact, compute and data consumed the entirety of any budget for analytics which left zero investment for the real value driver: algorithms to drive actionable insights. In the last couple years, with cost of compute and data plummeting, machine learning is now available to anyone, for rapid application and exploitation.
***
It is well known that businesses must constantly adapt to changing conditions: competitors introduce new offerings, consumer habits evolve, and the economic and political environment change, etc. This is not new, but the velocity at which business conditions change is accelerating. This constantly accelerating pace of change places a new burden on technology solutions developed for a business.
Over the years, application developers moved from V shaped projects, with multi-year turnaround, to agile development methodologies ( turnaround in months, weeks, and often days). This has enabled businesses to adapt their application and services much more rapidly. For example:
a) A sales forecasting system for a retailer: The forecast must take into account today’s market trends, not just those from last month. And, for real-time personalization, it must account for what happened as recently as 1 hour ago.
b) A product recommendation system for a stock broker: they must leverage current interests, trends, and movements, not just last months.
c) A personalized healthcare system: Offerings must be tailored to an individual and their unique circumstance. Healthcare devices, connected via The Internet of Things (IoT), can be used to collect data on human and machine behavior and interaction.
These scenarios, and others like them, create a unique opportunity for machine learning. Indeed, machine learning was designed to address the fluid nature of these problems.
Firstly, it moves application development from programming to training: instead of writing new code, the application developer trains the same application with new data. This is a fundamental shift in application development, because new, updated applications can be obtained automatically on a weekly, if not daily basis. This shift is at the core of the cognitive era in IT.
Secondly, machine learning enables the automated production of actionable insights where the data is (i.e. where business value is greatest). It is possible to build machine learning systems that learn from each user interaction, or from new data collected by an IoT device. These systems then produce output that takes into account the latest available data. This would not be possible with traditional IT development, even if agile methodologies were used.
***
While most companies get to the point of understanding machine learning, too few are turning this into action. They are either slowed down by concerns over their data assets or they attempt it one-time and then curtail efforts, claiming that the results were not interesting. These are common concerns and considerations, but they should be recognized as items that are easily surmounted, with the right approach.
First, let’s take data. A common trap is to believe that data is all that is needed for successful machine learning project. Data is essential, but machine learning requires more than data. Machine learning projects that start with a large amount of data, but lack a clear business goal or outcome, are likely to fail. Projects that start with little or no data, yet have a clear and measurable business goal are more likely to succeed. The business goal should dictate the collection of relevant data and also guide the development of machine learning models. This approach provides a mechanism for assessing the effectiveness of machine learning models.
The second trap in machine learning projects is to view it as a one-time event. Machine learning, by definition, is a continuous process and projects must be operated with that consideration.
Machine learning projects are often run as follows:
1) They start with data and a new business goal.
2) Data is prepared, because it wasn’t collected with the new business goal in mind.
3) Once prepared, machine learning algorithms are run on the data in order to produce a model.
4) The model is then evaluated on new, unforeseen, data to see whether it captured something sensible from the data. If it does, then it is deployed in a production environment where it is used to make predictions on new data.
While this typical approach is valuable, it is limited by the fact that the models learn only once. While you may have developed a great model, changing business conditions may make it irrelevant. For instance, assume machine learning is used to detect anomaly in credit card transactions. The model is created using years of past transactions and anomalies are fraudulent transactions. With a good data science team and the right algorithms, it is possible to obtain a fairly accurate model. This model can then be deployed in a payment system where it flags anomalies when it detects them. Transactions with anomalies are then rejected. This is effective in the short term, but clever criminals will soon recognize that their scam is detected. They will adapt, and they will find new ways to use stolen credit card information. The model will not detect these new ways because they were not present in the data that was used to produce it. As a result, the model effectiveness will drop.
The cure to avoid this performance degradation is to monitor the effectiveness of model predictions by comparing them with actuals. For instance, after some delay, a bank will know which transactions were fraudulent or not. Then it is possible to compare the actual fraudulent transactions with the anomalies detected by the machine learning model. From this comparison one can compute the accuracy of the predictions. One can then monitor this accuracy over time and watch for drops. When a drop happens, then it is time to refresh the machine learning model with more up to date data. This is what we call a feedback loop. See here:
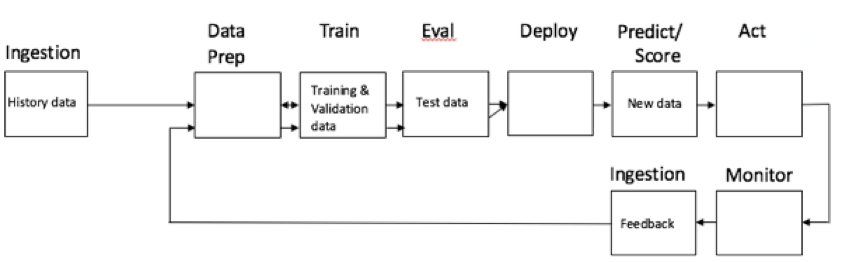
With a feedback loop, the system learns continuously by monitoring the effectiveness of predictions and retraining when needed. Monitoring and using the resulting feedback are at the core of machine learning. This is no different than how humans perform a new task. We learn from our mistakes, adjust, and act. Machine learning is no different.
***
Companies that are convinced that machine learning should be a core component of their analytics journey need a tested and repeatable model: a methodology. Our experience working with countless clients has led us to devise a methodology that we call DataFirst. It is a step-by-step approach for machine learning success.
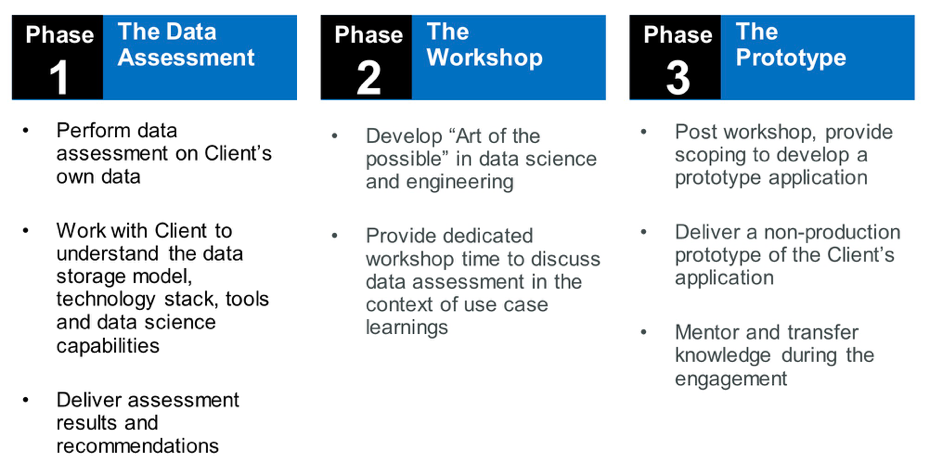
Phase 1: The Data Assessment
The objective is to understand your data assets and verify that all the data needed to meet the business goal for machine learning is available. If not, you can take action at that point, to bring in new sources of data (internal or external), to align with the stated goal.
Phase 2: The Workshop
The purpose of a workshop goal is to ensure alignment on the definition and scope of the machine learning project. We usually cover these topics:
– Level set on what machine learning can do and cannot do
– Agree on which data to use.
– Agree on the metric to be used results evaluation
– Explore how the machine learning workflow, especially deployment and feedback loop, would integrate with other IT systems and applications.
Phase 3: The Prototype
The prototype aims at showing machine learning value with actual data. It will also be used to assess performance and resources needed to run and operate a production ready machine learning system. When completed, the prototype is often key to secure a decision to develop a production ready system.
***
Leaders in the Data era will leverage their assets to develop superior machine learning and insight, driven from a dynamic corpus of data. A differentiated approach requires a methodical process and a focus on differentiation with a feedback loop. In the modern business environment, data is no longer an aspect of competitive advantage; it is the basis of competitive advantage.
| Reference: | A Practical Guide to Machine Learning: Understand, Differentiate, and Apply from our JCG partner Rob Thomas at the Rob’s Blog blog. |
