What is a Parallel Database Stream?
Read this post and learn how you can process data from a database in parallel using parallel streams and Speedment. Parallel streams can, under many circumstances, be significantly faster than the usual sequential streams.
With the introduction of Java 8, we got the long awaited Stream library. One of the advantages with streams is that it is very easy to make streams parallel. Basically, we could take any stream and then just apply the method parallel() and we get a parallel stream instead of a sequential one. By default, parallel streams are executed by the common ForkJoinPool.

So, if we have work items that are relatively compute intensive, then parallel streams would often make sense.Parallel streams are good if the work items to be performed in the parallel stream pipelines are largely uncoupled and when the effort of dividing up the work in several threads is relatively low. Equally, the effort of combining the parallel results must also be relatively low.
Speedment is an open-source Stream ORM Java Toolkit and RuntimeJava tool that wraps an existing database and its tables into Java 8 streams. We can use an existing database and run the Speedment tool and it will generate POJO classes that corresponds to the tables we have selected using the tool.
One cool feature with Speedment is that the database streams supports parallelism using the standard Stream semantics. This way, we can easily work with database content in parallel and produce results much faster than if we process the streams sequentially!
Getting Started With Speedment
Visit open-souce Speedment on GitHub and learn how to get started with a Speedment project. It should be very easy to connect the tool to an existing database.
In this post, the following MySQL table is used for the examples below.
1 2 3 4 5 6 | CREATE TABLE `prime_candidate` ( `id` int(11) NOT NULL AUTO_INCREMENT, `value` bigint(20) NOT NULL, `prime` bit(1) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB; |
The idea is that people may insert values into this table and then we will write an application that computes if the inserted values are a prime numbers or not. In a real case scenario, we could use any table in a MySQL, PostgreSQL or MariaDB database.
Writing a Sequential Stream Solution
First, we need to have a method that returns if a value is a prime number. Here is a simple way of doing it. Note that the algorithm is purposely made slow so we clearly can se the effects of parallel streams over an expensive operation.
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | public class PrimeUtil { /** * Returns if the given parameter is a prime number. * * @param n the given prime number candidate * @return if the given parameter is a prime number */ static boolean isPrime(long n) { // primes are equal or greater than 2 if (n < 2) { return false; } // check if n is even if (n % 2 == 0) { // 2 is the only even prime // all other even n:s are not return n == 2; } // if odd, then just check the odds // up to the square root of n // for (int i = 3; i * i <= n; i += 2) { // // Make the methods purposely slow by // checking all the way up to n for (int i = 3; i <= n; i += 2) { if (n % i == 0) { return false; } } return true; }} |
Again, the object of this post is not to devise an efficient prime number determination method.
Given this simple prime number method, we can now easily write a Speedment application that will scan the database table for undetermined prime number candidates and then it will determine if they are primes or not and update the table accordingly. This is how it might look:
01 02 03 04 05 06 07 08 09 10 11 | final JavapotApplication app = new JavapotApplicationBuilder() .withPassword("javapot") // Replace with the real password .withLogging(LogType.STREAM) .build(); final Manager<PrimeCandidate> candidates = app.getOrThrow(PrimeCandidateManager.class); candidates.stream() .filter(PrimeCandidate.PRIME.isNull()) // Filter out undetermined primes .map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) // Sets if it is a prime or not .forEach(candidates.updater()); // Applies the Manager's updater |
The last part contains the interesting stuff. First, we create a stream over all candidates where the ‘prime’ column is
null using the stream().filter(PrimeCandidate.PRIME.isNull()) method. It is important to understand that the Speedment stream implementation will recognize the filter predicate and will be able to use that to reduce the number of candidates that are actually pulled in from the database (e.g. a “SELECT * FROM candidate WHERE prime IS NULL” will be used).
Then, for each such prime candidate pc, we either set the ‘prime’ column to true if pc.getValue() is a prime or false if pc.getValue() is not a prime. Interestingly, the pc.setPrime() method returns the entity pc itself, allowing us to easily tag on multiple stream operations. On the last line, we update the database with the result of our check by applying the candidates.updater() function. So, this application’s main functionality is really a one-liner (broken up into five lines for improved readability).
Now, before we can test our application, we need to generate some test data input. Here is an example of how that can be done using Speedment:
01 02 03 04 05 06 07 08 09 10 11 12 | final JavapotApplication app = new JavapotApplicationBuilder() .withPassword("javapot") // Replace with the real password .build(); final Manager<PrimeCandidate> candidates = app.getOrThrow(PrimeCandidateManager.class); final Random random = new SecureRandom(); // Create a bunch of new prime candidates random.longs(1_100, 0, Integer.MAX_VALUE) .mapToObj(new PrimeCandidateImpl()::setValue) // Sets the random value .forEach(candidates.persister()); // Applies the Manager's persister function |
Again, we can accomplish our task with just a few lines of code.
Try the Default Parallel Stream
If we want to parallelize our stream, we just need to add one single method to our previous solution:
1 2 3 4 5 | candidates.stream() .parallel() // Now indicates a parallel stream .filter(PrimeCandidate.PRIME.isNull()) .map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) .forEach(candidates.updater()); // Applies the Manager's updater |
And we are parallel! However, by default, Speedment is using Java’s default parallelization behavior (as defined in Spliterators::spliteratorUnknownSize) which is optimized for non compute-intensive operations. If we analyze Java’s default parallelization behavior, we will determine that it will use a first thread for the first 1024 work items, a second thread for the following 2*1024 = 2048 work items and then 3*1024 = 3072 work items for the third thread and so on.
This is bad for our application, where the cost of each operation is very high. If we are computing 1100 prime candidates, we will only use two threads because the first thread will take on the first 1024 items and the second thread will take on the rest 76. Modern servers have a lot more threads than that. Read the next section to see how we can fix this issue.
Built-in Parallelization Strategies
Speedment has a number of built-in parallelization strategies that we can select depending on the work item’s expected computational demands. This is an improvement over Java 8 that only has one default strategy. The built-in parallel strategies are:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | @FunctionalInterfacepublic interface ParallelStrategy { /** * A Parallel Strategy that is Java's default <code>Iterator</code> to * <code>Spliterator</code> converter. It favors relatively large sets (in * the ten thousands or more) with low computational overhead. * * @return a ParallelStrategy */ static ParallelStrategy computeIntensityDefault() {...} /** * A Parallel Strategy that favors relatively small to medium sets with * medium computational overhead. * * @return a ParallelStrategy */ static ParallelStrategy computeIntensityMedium() {...} /** * A Parallel Strategy that favors relatively small to medium sets with high * computational overhead. * * @return a ParallelStrategy */ static ParallelStrategy computeIntensityHigh() {...} /** * A Parallel Strategy that favors small sets with extremely high * computational overhead. The set will be split up in solitary elements * that are executed separately in their own thread. * * @return a ParallelStrategy */ static ParallelStrategy computeIntensityExtreme() {...} <T> Spliterator<T> spliteratorUnknownSize(Iterator<? extends T> iterator, int characteristics); static ParallelStrategy of(final int... batchSizes) { return new ParallelStrategy() { @Override public <T> Spliterator<T> spliteratorUnknownSize(Iterator<? extends T> iterator, int characteristics) { return ConfigurableIteratorSpliterator.of(iterator, characteristics, batchSizes); } }; } |
Applying a Parallel Strategy
The only thing we have to do is to configure a parallelization strategy to a manager like this, and we are good to go:
1 2 3 4 5 6 7 8 9 | Manager<PrimeCandidate> candidatesHigh = app.configure(PrimeCandidateManager.class) .withParallelStrategy(ParallelStrategy.computeIntensityHigh()) .build(); candidatesHigh.stream() // Better parallel performance for our case! .parallel() .filter(PrimeCandidate.PRIME.isNull()) .map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) .forEach(candidatesHigh.updater()); |
The ParallelStrategy.computeIntensityHigh() strategy will break up the work items in much smaller chunks. This will give us considerably better performance, since we now are going to use all the available threads. If we look under the hood, we can see that the strategy is defined like this:
1 2 3 4 | private final static int[] BATCH_SIZES = IntStream.range(0, 8) .map(ComputeIntensityUtil::toThePowerOfTwo) .flatMap(ComputeIntensityUtil::repeatOnHalfAvailableProcessors) .toArray(); |
This means that, on a computer with 8 threads, it will put one item on thread 1-4, two items on thread 5-8 and when the tasks are completed there will be four items on the next four available threads, then eight items and so on until we reach 256 which is the maximum items put on any thread. Obviously, this strategy is much better than Java’s standard strategy for this particular problem.
Here is how the threads in the common ForkJoinPool looks like on my 8 threaded laptop:
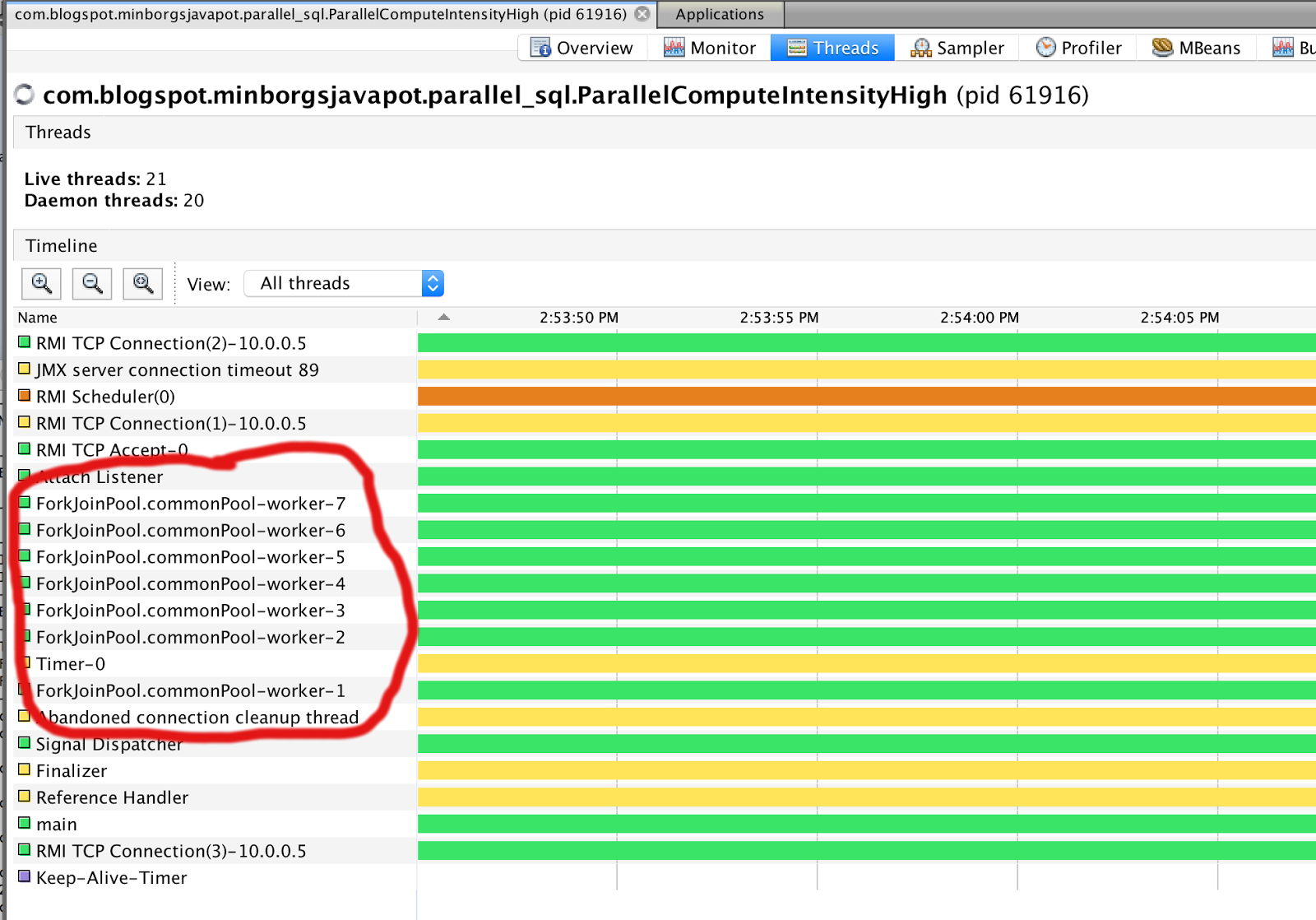
Create Your Own Parallel Strategy
One cool thing with Speedment is that we, very easily, can write our parallelization strategy and just inject it into our streams. Consider this custom parallelization strategy:
01 02 03 04 05 06 07 08 09 10 | public static class MyParallelStrategy implements ParallelStrategy { private final static int[] BATCH_SIZES = {1, 2, 4, 8}; @Override public <T> Spliterator<T> spliteratorUnknownSize(Iterator<? extends T> iterator, int characteristics) { return ConfigurableIteratorSpliterator.of(iterator, characteristics, BATCH_SIZES); } } |
Which, in fact, it can be expressed even shorter:
1 | ParallelStrategy myParallelStrategy = ParallelStrategy.of(1, 2, 4, 8); |
This strategy will put one work item on the first available thread, two on the second, four on the third, eight on the fourth with eight being the last digit in our array. The last digit will then be used for all subsequent available threads. So the order really becomes 1, 2, 4, 8, 8, 8, 8, … We can now use our new strategy as follows:
1 2 3 4 5 6 7 8 9 | Manager<PrimeCandidate> candidatesCustom = app.configure(PrimeCandidateManager.class) .withParallelStrategy(myParallelStrategy) .build(); candidatesCustom.stream() .parallel() .filter(PrimeCandidate.PRIME.isNull()) .map(pc -> pc.setPrime(PrimeUtil.isPrime(pc.getValue()))) .forEach(candidatesCustom.updater()); |
Voilà! We have full control over how the work items are laid out over the available execution threads.
Benchmarks
All benchmarks used the same input of prime candidates. Tests were run on a MacBook Pro, 2.2 GHz Intel Core i7 with 4 physical cores and 8 threads.
1 2 3 4 5 | StrategySequential 265 s (One thread processed all 1100 items)Parallel Default Java 8 235 s (Because 1024 items were processed by thread 1 and 76 items by thread 2)Parallel computeIntensityHigh() 69 s (All 4 hardware cores were used) |
Conclusions
Speedment supports parallel processing of database content. Speedment supports a variety of parallel strategies to allow full utilization of the execution environment.
We can easily create our own parallel strategies and use them in our Speedment streams. It is possible to improve performance significantly by carefully selecting a parallel strategy over just settling with Java’s default one.
| Reference: | Work with Parallel Database Streams using Java 8 from our JCG partner Per Minborg at the Minborg’s Java Pot blog. |
