4 Hot Business Intelligence Trends: The Joy of Self-Service Business Intelligence (Part 4 of 4)
Do you remember the first time you encountered a self-service checkout terminal in the supermarket? I do. My first reaction was to ask what incentives the store was going to give me for being my own cashier? Discounts? Coupons? Surely I wasn’t expected to do someone else’s job for free.
Today, I rarely even bother with manned cashier lines. Self-service is quicker and I don’t have to deal with chatty employees or comments on what I’m buying. I’m a self-service convert.
Chances are you are, too. In fact, research has shown that more than half of US retail shoppers prefer self-service checkout to cashiers in most situations. A recent study in the UK found that only 10 percent of shoppers say they’ve never used a self-checkout terminal, and 71 percent said self-service machines are more convenient when buying just a few items.
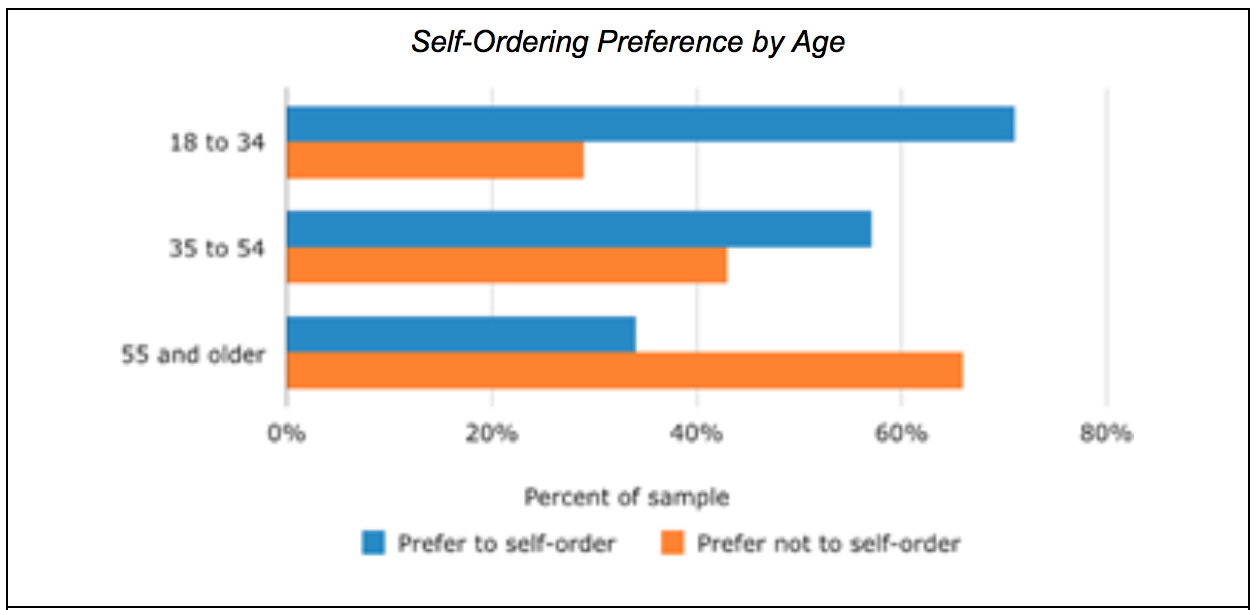
Source: Software Advice
And the trend is clear. A study of users of self-service point-of-sale systems in restaurants by Software Advice found that more than 70% percent of diners between the ages of 18 and 34 preferred them, compared to less than 35 percent of those over the age of 55. We’re raising a self-service generation.
So why shouldn’t the same dynamics apply to business intelligence (BI)? The time is right. From the early days of BI in the late 1980s until recently, the process of supporting analytical queries changed little. Business users specified exactly what data they needed, IT created a custom schema and then extracted, transformed and loaded (ETL) the necessary production data into the BI database. Reports were limited to what could be specified in an SQL query and new data had to go through the same arduous ETL process each time it was updated. The whole process was so painful and time-consuming that few users even bothered.
How times have changed.
Hadoop created the concept of a “data lake,” or a repository of structured and unstructured data that users could mine without supervision for BI-style modeling. Analytics languages like SAS, SPSS and R provide powerful programming capabilities to data scientists, but tools like Tableau, Qlik and AtScale give much of the same functionality to business users without all the complexity. A visit to the Tableau Gallery shows you the wonderful things people come up with when not hidebound by schemas and rules.

Building a self-service BI playground on top of a data lake doesn’t have to be difficult or expensive. Here are a few principles to keep in mind if you go that way:
- Use a sandbox approach. Data lakes are initially a staging area for analytics. They house large volumes of data inexpensively, enabling users to experiment with different combinations and dimensions. Keep the data lake separate from your operational data store and don’t put a lot of restrictions on what users can do there. Let them play.
- Say “yes” to data. The most stunning analytical insights these days come when users combine data elements that don’t intuitively make sense together. If someone wants to correlate sales of chicken pies and sweaters, let them. They just might be onto something. The point of a data lake is to find interesting relationships that are worth formalizing in your data warehouse. The cost and impact of experimenting with different data sources is small, so let a hundred data flowers bloom.
- Don’t structure things too much. One big difference between data warehouses and data lakes is in schema design. A data warehouse schema is typically defined before data is stored (“schema on write”) in order to deliver maximum performance, security and integration. In contrast the schema in a data lake isn’t typically defined until after the data is stored (“schema on read”). This process is less efficient but easier and far more flexible. Data that is chosen for operational use in the data warehouse should go through a formal schema design process.
- Provide training and help desk support. One in three shoppers has walked out of a store without making a purchase because of a bad experience with self-service checkout, according to a survey by customer experience management consultancy Tensator. In fact, frustration with self-service terminals is the biggest factor holding back them back. The same applies to self-service BI. If users struggle to figure out the tools you’ve given them, they will quickly abandon the effort. Keep the palette of options limited and be sure to offer training.
- Protect the data warehouse. A data lake delivers greatest value when it unearths data and relationships that can be operationalized in the data warehouse. That said, not every discovery is a Big Bang theory. Users should be held accountable for demonstrating the validity and value of their discoveries before IT goes to the expense and trouble of creating schemas and conducting ETL for the data warehouse.
- Don’t forget security. Because self-service BI is exploratory nature, it might be tempting to go easy on security. After all, users aren’t working with transactional data. But they probably are working with data that’s proprietary to your business, even if it’s a few days old. As a rule of thumb, data in the lake deserves just as much security as data in the warehouse.
The beautiful thing about self-service is that it’s a win-win. The organization providing the service saves on labor and can allocate its resources to more productive and interesting tasks. Users get the information they need quickly without a lot of overhead. With cost barriers tumbling and tools proliferating, now might be a good time to give self-service BI a try.
Learn more by downloading the free book: The Definitive Guide to BI and Analytics on a Data Lake.![]()
| Reference: | 4 Hot Business Intelligence Trends: The Joy of Self-Service Business Intelligence (Part 4 of 4) from our JCG partner Sameer Nori at the Mapr blog. |
